云端AI芯片落地难题如何破解 (云端AI芯片)
提到AI的落地你最先会想到什么?
有人想到了AI芯片的利用率以及底层硬件的调度;有人想到AI芯片的算力效益;还有人想到算力服务。
AI的落地,能够为智慧城市的建设,更精准的天气的预测,构建更安全的网络环境等提供底层支撑。

但是,AI的落地依旧面对诸多的挑战。比如,如何才能将AI用起来?如何才能渐进式的实现AI的价值?如何基于AI发展算力经济?
这逐层渐进的问题,考验着所有提供AI技术以及想要使用AI技术的人。对于最底层的AI芯片的提供者,目前非常棘手的问题之一就是软件。
燧原科技创始人兼COO张亚林在2022世界人工智能大会上就表示:“根据过往落地实践,我们发现, AI数据中心因其软件运维复杂,普遍具有方案选型难、各厂商产品兼容未知等痛点,而且数据中心部署交付周期长、沟通成本高、项目管理周期长。 ”
软件问题,特别是基于云端高性能AI推理和训练芯片的上层软件和生态,限制着众多AI芯片创新者的发展。
燧原科技创始人、CEO赵立东认为,“生态的垄断是目前我们面临的最大挑战,而生态垄断的原因是紧耦合的软件和硬件。因此,我们一定要创新。”
为了解决当下云端AI芯片落地的挑战,不同的公司会从不同的维度突破软件和生态的挑战。
2022年9月3日,燧原科技在“算尽其用·定义AI算力中心新实践”云端算力产业应用论坛上给出了解决这一挑战的答案——云燧智算机(CloudBlazer POD)。
云燧智算机是针对大规模、集约化人工智能算力应用场景的高性能AI加速集群,有一站式预集成人工智能加速硬件、一体化开发与管理平台及配套人工智能应用软件与服务,适用于数字政府、科研院所、科创平台等。
简单来说, 燧原科技在解决高性能云端AI芯片落地给出的一个解题思路就是“开箱即用”。
何为开箱即用?在交付方式上,云燧智算机提供包括采购、安装、运维一体的交钥匙方案。
能够以这样的方式交付,还是因为云燧智算机采用一体化设计。
硬件的算力层面,基于燧原科技已经发布的自研AI高性能芯片。在典型配置下,云燧智算机每单元可达到8PFLOPS的TF32浮点算力,并且支持按需横向扩容,可支持数千卡规模集群, 能够实现顶级超算的E级算力。
同时,云燧智算机也集成了合作伙伴的CPU,提供充足的算力。但计算集群除了算力这个核心要素之外,网络和存储和非常关键。
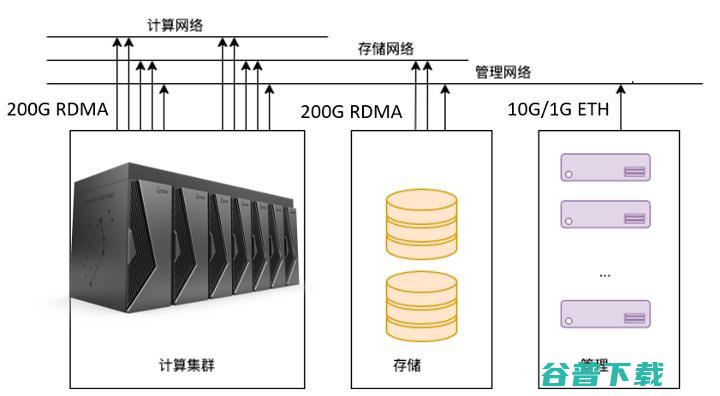
张亚林介绍,“云燧智算机代表了燧原科技经过多个大规模工程实践所形成的计算、网络、存储的整体设计:以全局优化为目标,基于计算、存储、管理网络分离,全互联无阻塞的网络架构,结合高效的多级存储方式,在‘邃思’AI芯片与CPU的异构算力支撑下,云燧智算机能够提供卓越的AI性能。”
了解到, 燧原科技的第一代和第二代“邃思”芯片已实际应用于大规模AI集群工程中,落地规模达千卡级别, 场景包括融媒体生成、城市智能感知等。
当然,提到计算集群就不得不关注数据中心整体能效(PUE),特别是在双碳目标以及绿色环保的总体趋势,以及东数西算有政策性要求。据悉,云燧智算机采用一体化冷板式液冷技术,实现单节点8颗高性能人工智能芯片液冷散热, PUE可降至1.1及以下。
前面提到,AI落地一个巨大的挑战就是软件。不过软件是一个很宽泛的概念,既需要能够提升AI芯片利用率的编译器、库等,也需要算力平台的管理软件。
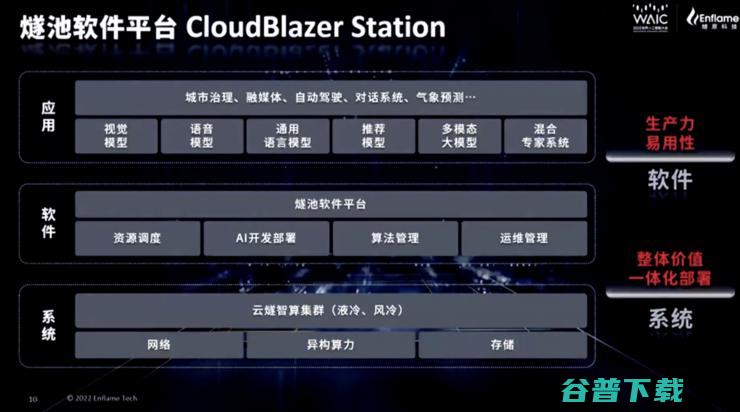
随最新推出的云燧智算机一起推出的是燧原科技提供燧池智算平台(CloudBlazer Station),包含基础设施层的异构算力调度平台,智能运维平台,驭算软件栈SDK,算法服务层的智能算法管理平台以及训推一体化平台。
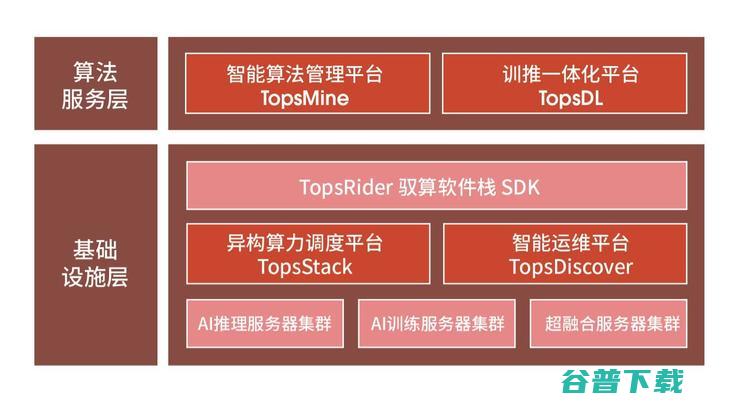
同时,面对超大参数量的巨量模型趋势, 云燧智算机可支持超千亿参数巨量模型的高效、并行训练, 这主要是得益于云燧智算机计算节点内基于GCU-LARE2.0多芯互联技术提供近1TB/s的互联带宽,跨节点互联能力高达600Gb/s,可实现千卡级大规模集群高速互联。
开箱即用的计算集群确实能够在一定程度降低使用者的门槛,但计算集群毕竟是一个复杂的系统,最终能在多大程度上促进高性能AI计算的落地,还需要用更多的落地项目证明。
原创文章,未经授权禁止转载。详情见 转载须知 。


重庆宏庭装饰工程有限公司是一家集装修设计、装修效果图、装修施工、基材、主材、家具、家电为一体的豪华全包装修装饰公司,线上线下为一体,性价比高,质量有保障。咨询电话:131-4033-8379

麦爆啦-互动式效果广告平台,集互动广告投放平台、移动广告平台、手机广告联盟、APP广告投放、原生广告、效果广告于一体的流量变现平台,为流量主提供用户体验佳、流量变现效率高的商业化解决方案。

RUNENS润恩斯

岷山环能高科股份公司是一家集城市矿产、资源再生、综合利用、新型材料、智慧能源为一体的循环经济清洁生产企业。目前公司综合回收黄金500公斤、银300吨(取得商务部白银配额)、铜3000吨、锌2万吨、锑白500吨、铋300吨、碲10吨、铟10吨、电子级硫酸3万吨、精制酸3万吨等。

manfield孟斐德泵业创建于2010年,专注别墅住宅地下室污水提升泵,产品获得出口欧美CE认证、SGS认证等各项顶级认证。十余年服务了上万家别墅客户。拥有铬镍电机、超低滞留,一机三挡,自洁净等多项独特设计,其独创的紧凑型双泵型号深获高端别墅客户的好评。

四川策文科技有限公司

新乡市灵龙水处理材料有限公司专业生产销售:非离子聚丙烯酰胺,聚合氯化铝,碱式氯化铝.咨询热线:0373-5822522

洽单资源库-互联网稀缺资源免费分享平台,分享软件源码、创业项目,网站代码、网络技术、薅羊毛教程等精品资源。网站致力于为广大站长、程序员、互联网从业者提供一站式免费资源分享平台
教育科技有限公司")
九顶(上海)教育科技有限公司

贵州九九起重机厂家(电话:15985199618)公司主营:贵州起重机,贵阳起重机厂家,贵阳通用桥门式起重机,贵阳单双梁桥式起重机,遵义电动葫芦,安顺起重设备,凯里起重机安装,毕节起重机维修,六盘水起重机维护,铜仁龙门吊,安顺防液压升降设备价格,兴义行吊工程,都匀起重机保养,厂家批发直销供应。

宁波永成双海汽车部件股份有限公司

上海回恩主要生产各类绝缘材料配件,库存工程塑料,变压器配件。产品系列有:层压类(环氧板、FR4绝缘材料板、G11绝缘板等)、层压棒(G10\G11)、层压管(棉布管、胶木管、G10管G11管),精加工类(绝缘加工件等)、特种绝缘材料类(GPO-3139179772173240FR4G10G11EPGC201EPGC202EPGC203UPM203GPO3绝缘垫片等。


美容护肤已经是全民热衷的生活服务了,不仅是年轻貌美的小姑娘喜欢追求美,就连男士群体以及中老年人,也都加入了美容的队伍中,这对于水胭脂美容院来说,是一个利好的消息,大大促进了企业的发展,那么,水胭脂美容院有多少美容师,技术好吗,水胭脂美容院有多少美容师水胭脂美容院成立至今,拥有二十多年的丰富经验,不断的成长与发展,令其不再只是单一的美容...。

美柚作为一款专注关爱女性健康的服务软件,通过它大家不仅能记录自己健康情况,还能预测自己的经期,因此很受大家的喜爱,下面小编来为大家介绍美柚切换模式的具体操作,希望对你们有所帮助,...。

放在四五年前,我很难想象5家国内TOP级的经销商会同时竞争小鹏一个授权店的名额,电盒校长回想起2022年,在经销商工作的老友和他聊到一件不同寻常的事,包括利星行、森那美在内的国内5大经销商,同时争夺小鹏汽车上海某一个授权店的名额,有经销商为了拿下该项目,直接派出豪车品牌出身的人担任该项目的销售经理,电盒校长曾在法拉利这样的豪华品牌...。

搜狗纽交所上市首日报收13.51美元市值近53亿美元搜狗公司10月9日正式登陆纽交所,开盘价13.00美元,最高14.70美元,收盘13.51美元,涨3.92%,市值52.89亿美元,搜狗通过首次公开招股发行4500万股美国存托凭证,1股美国存托凭证相当于1股A级普通股,,发行价为每股美国存托凭证13美元,总发行募集金额为5.85亿美...。

叶生晅认为,这个世界上存在三类人,们追求平淡而朴实的生活,在普通学校就读、小公司工作也能知足常乐;一类是世俗意义上的,成功人士,,他们是某个领域的管理者,对该领域有着非常深刻的理解;者,,眼界广阔,无论将他们处于怎样的环境,他们都能得心应手,如果将前两类人的眼界比喻成,点,与,线,,那么第三类人的眼界就是,面,叶生晅很清楚自己想成为...。

1、锅中放油,下入冰糖或冰糖粉,小火将其熬化,2、熬糖的同时,将需要用量的水也在一边烧上,注意后面我们要使用的是开水,千万不要使用凉水,凉开水也不行哦,就是要温度越高越好,3、小火把糖全部熬化需要时间,一定要耐心,不时拿锅铲搅拌,不要失去耐心转成大火了,4、冰糖全部融化之后,表面开始出现气泡,量会由少及多,5、开始是细密的小泡,表面快...。

中国电信APP内虚伪宣传新开星卡流量版29元套餐流量赠送优惠,官网开卡页面显示激活首充50元后赠送20g通用流量每月期限一年,收到卡后实现50元首充激活后迟迟未收到20G流量到账,反应官网客服,说我操持的日期不在优惠范畴内,官网宣传页第1栏清分明楚的写着首充50激活送20G每月全国流量一年,企业涉嫌诱导生产者办卡敞开......。

太清醒也会被骂,女性好难

腾讯软件中心提供2023年最新3.1.5.16官方正式版小智桌面高速下载,本正式版小智桌面软件安全认证,免费无插件。

腾讯软件中心提供2023年最新8.92.0.401官方正式版Skype高速下载,本正式版Skype软件安全认证,免费无插件。

重庆分类目录网站收录健康相关的优秀网站大全分类检索,为上网用户提供健康网站排行榜与您分享、收藏!

野外求生游戏有哪些介绍,这些游戏不仅提供了丰富的生存机制,还通过独特的游戏设定和故事背景,让玩家在紧张刺激的求生过程中感受到无尽的乐趣,无论你是生存游戏的老手还是新手,这些游戏都能让你在这其中找到属于自己的生存之道,1、,生存岛野外逃生,野生动物的出没更是增加了游戏的难度,每种动物都有其独特的攻击方式和威胁,玩家必须时刻保持警惕,在这...。

很多人从小就开始展现自己身上的艺术细胞,比如亲自动手制作衣服,这布置考验玩家的创造力,同时也非常考验动手能力,看一下有哪些可以自己做衣服的游戏,在生活中需要自己裁剪缝制,耗费的时间比较长,但是在游戏中轻松的就能做出一件衣服,省略的制作步骤可以让玩家使用更多的时间设计服装的款式,而且做完的衣服可以直接上身,能更直观的观察到衣服穿上身的整...。

昨天回了外婆家一趟,很长时间没去看看老人家了,想着这段有时间就回去看看,后面忙起来可能会很少回去了,回去以后,正好小舅在家,小舅一直对我比较好,我们两个也算聊得来,舅舅说明年打算养牛,顺带带着我看看他的养殖厂,跟着舅舅去了养殖厂,舅舅开始介绍这里是干什么的,那里是什么,大概做到什么程度,外面天比较冷,看了一会就回屋了,舅舅问我明年准备...。

曾几何时,学手艺,拜师,收徒,这些在现实生活中才有的事,都被转移到网络上来了,童话在2014年的时候,就收了三个来上门学技术的徒弟,主要他们求着你教,又是朋友亲戚,抹不开这个面子,刚好自己也忙不过来,但我现在奉劝大家千万别教自己的亲戚朋友,一边教他们东西一边还得给他们发工资,钱给少了他们不高兴,给多了自己又觉得亏,干活也是能偷懒就偷懒...。
文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为运发广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在运发广告联盟网站首页底部或友情链接位...。
