2019 语义分割指南 (语义题是什么)
语义分割是指将图像中的每个像素归于类标签的过程,这些类标签可以包括一个人、汽车、鲜花、一件家具等。
它的一些主要应用是在自动驾驶、人机交互、机器人和照片编辑/创意工具中。例如,语义分割在汽车自动驾驶和机器人技术中是至关重要的,因为对于一个模型来说,了解其所处环境中的语义信息是非常重要的。
图源:~tingwuwang/semantic_segmentation.pdf
此处
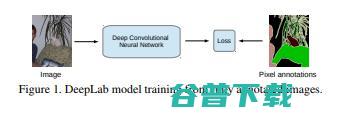
01.用于语义图像分割的深度神经网络弱和半监督学习(ICCV,2015)
这篇文章提出了一种解决方法,用于面对深度卷积网络中处理弱标记数据的难题、以及处理良好标记与未适当标记数据结合。
本文应用了一个深度CNNs与全连接条件随机场的组合。
用于语义分割的DCNN弱和半监督学习(
在PASCAL VOC分割基准中,这个模型给出了超过70%的平均IoU。这种模型的一个主要难题是它在训练时需要在像素层次标记的图像。
这篇文章的主要贡献在于:
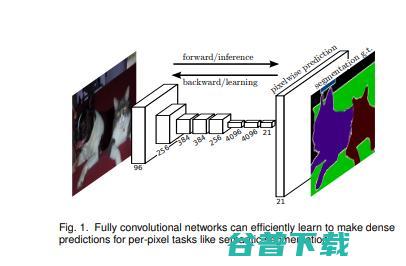
02.用于语义分割的全卷积网络(PAMI,2016)
用于语义分割的全卷积网络(
这篇文章提出的模型在PASCAL VOC 2012上取得了67.2%的平均IU。
全连接网络输入任意大小的图像,生成一个对应空间维度的输出。在这个模型中,ILSVRC分类器被转换成一个全连接网络,并使用逐像素损失和网络内上采样强化来进行密集预测,之后对分割的训练就通过fine-tuning完成。Fine-tuning是在整个网络上进行反向传播完成的。
03.U-Net:用于生物医学图像分割的卷积网络
在生物医学图像处理中,获得图像中每个细胞的类别标签至关重要。而生物医学任务中最大的挑战就在于难以获得数以千计的图像来用于训练。
U-Net:用于医学图像分割的卷积网络(
这篇文章构建在全卷积层之上,并将其修改使其在一些训练图像上有效并产出更精确的分割。
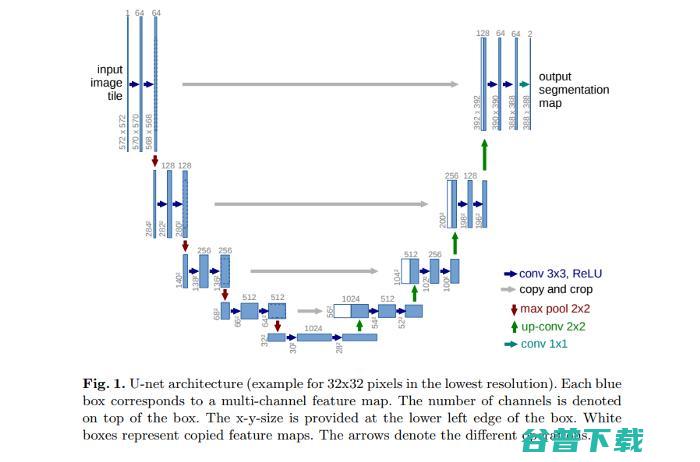
因为只能获得很少的训练数据,这个模型在已有数据上应用弹性变形来对数据增强。就如上面图1中所示,网络架构由左侧的收缩路径和右侧的膨胀路径组成。
收缩路径由两个 3x3 卷积组成,每个卷积后面都跟一个修正线性单元和一个用于下采样的 2x2 最大池化。每个下采样阶段都多使特征通道数加倍。膨胀路径步骤中包含一个特征通道的上采样。这后面跟着将特征通道数减半的 2x2 上卷积。最后一层是一个将成分特征向量映射到要求类别数的 1x1 卷积。
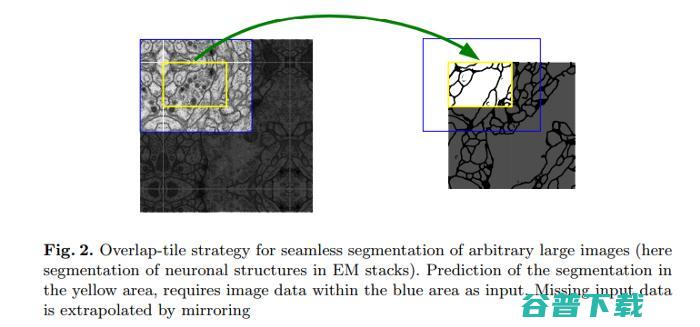
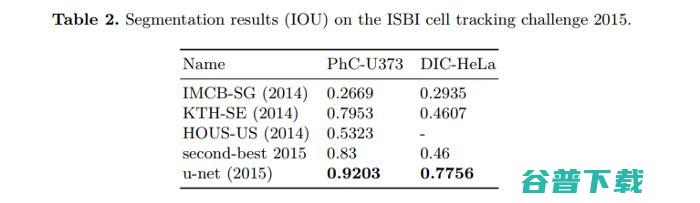
在这个模型中,训练使用输入图像——它们的分割图,和一个Caffe实现的随机梯度下降完成。数据增强用于在使用很少的训练数据时教会网络达到所要求的鲁棒性和不变性。模型在一个实验中达到了0.92的平均IoU。
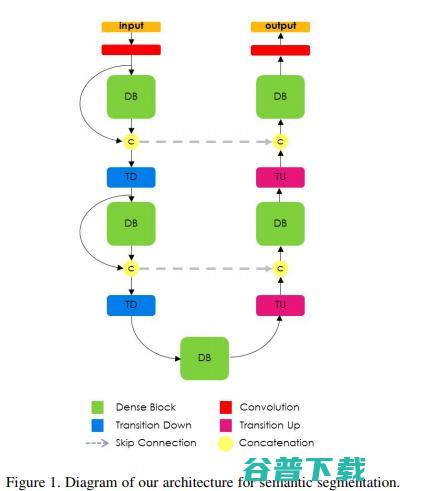
04.100层Tiramisu:用于语义分割的全卷积DenseNets(2017)
DenseNets背后的思想是使每一层以前向传播的方式连接到所有层会使网络更易于训练并更精确。
100层Tiramisu:用于语义分割的全卷积DenseNets()
模型结构构建在dense块的下采样和上采样路径中,下采样路径有2个Transitions Down(TD)而上采样路径有两个Transitions Up(TU)。圆圈和箭头表示网络内的连接模式。
这篇文章的主要贡献在于:
这个模型在CamVid数据集上达到了88%的全局准确率。
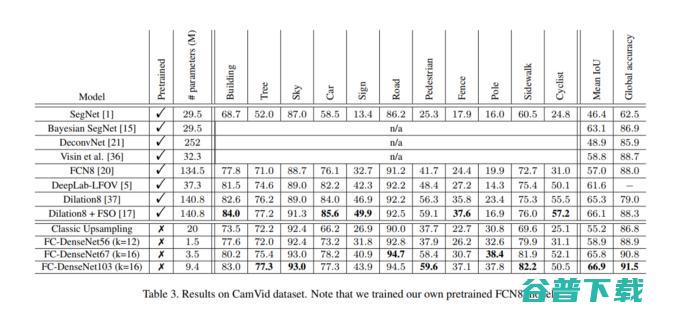
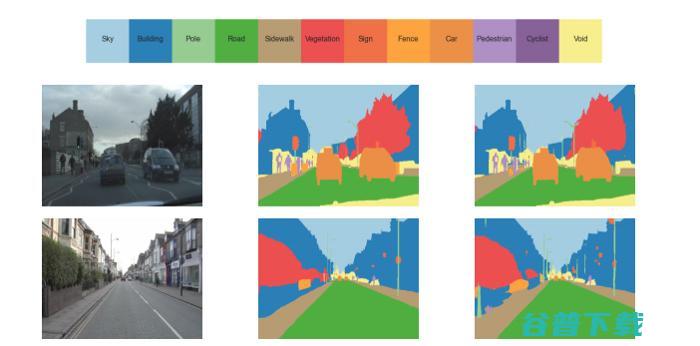
05.扩张卷积的多尺度背景聚合(ICLR,2016)
在这篇论文中,开发了一种卷积网络模块,它可以在不损失分辨率的情况下融合多尺度的上下文信息。然后该模块可以以任何分辨率插入现有架构。该模块基于扩张卷积。
扩张卷积的多尺度上下文聚合( )
该模块在Pascal VOC 2012数据集上进行了测试。它证明向现有语义分段体系结构添加上下文模块可提高其准确性。

经过实验训练的前端模块在VOC-2012验证集上实现了69.5%的平均IoU,在测试机上实现了71.3%的平均IoU。该模型对不同物体的训练精度如下所示。
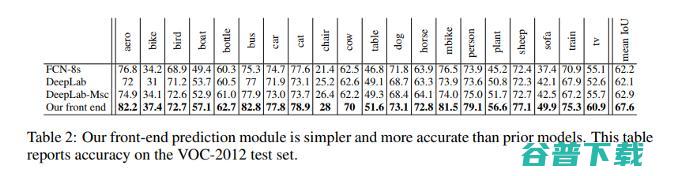
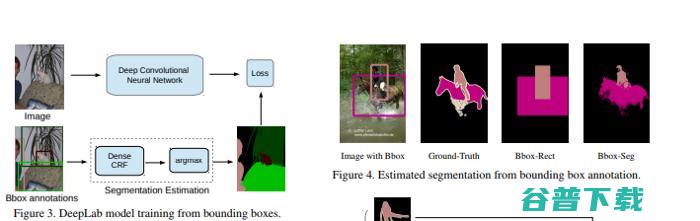
06.DeepLab: 基于深度卷积网络,空洞卷积和全连接CRFs的图像语义分割(TPAMI, 2017)
这篇文章提出的DeepLab系统在PASCAL VOC-2012语义图像分割任务上实现了79.7%的mIOU。
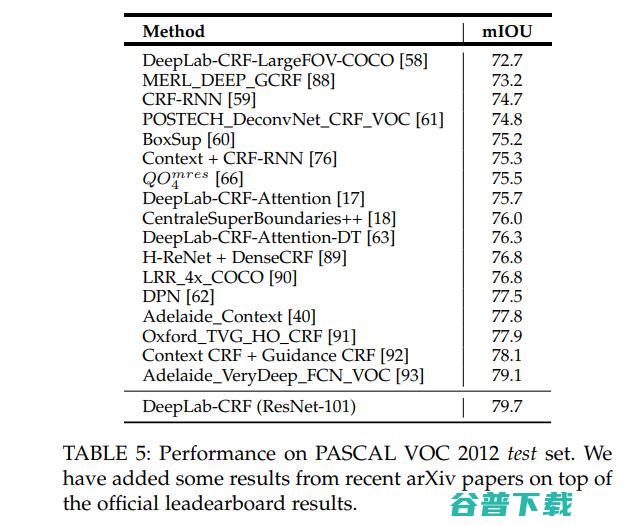
本文针对深度CNNs在语义分割应用中面临的主要挑战,包括:
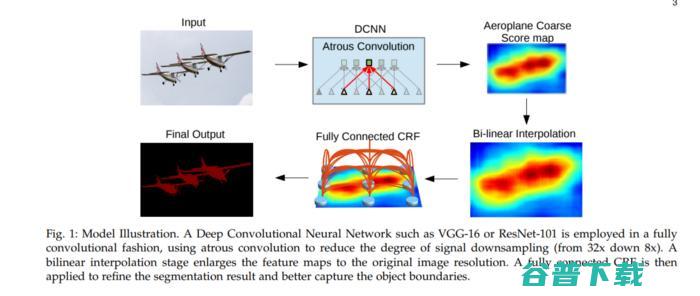
空洞卷积可以通过对滤波器插入零点进行上采样来实现,也可以对输入特征map进行稀疏采样来实现。第二种方法需要对输入特征图通过一个等于空洞卷积率r的因子进行下采样,并将其去除间隔行生成r^2的缩减分辨率map,每种可能的转换为r×r分辨率的缩减变换均对应一个分辨率map。然后,对得到的特征map应用标准卷积操作,将提取到的特征与图像的原始分辨率进行融合。
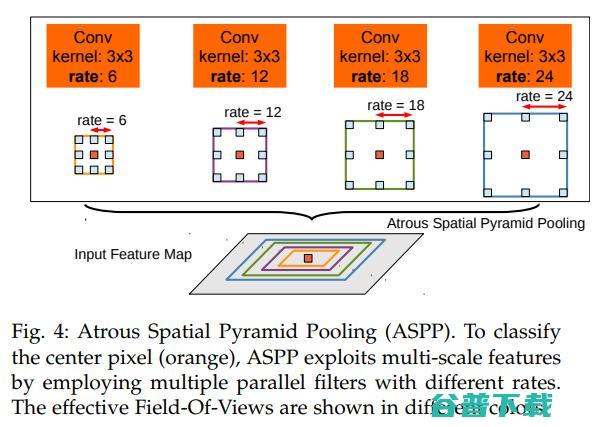
07.重新思考用于语义图像分割的Atrous卷积(2017)
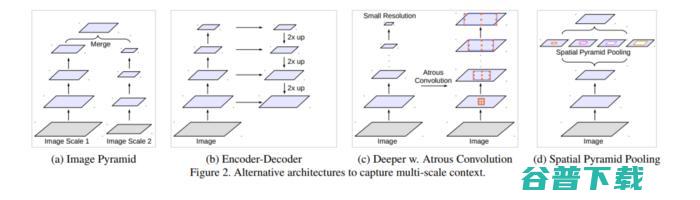
本文讨论了使用DCNNs进行语义分割的两个挑战(前面提及);应用连续池化操作出现的特征分辨率降低和对象在多尺度出现。
重新思考用于语义图像分割的Atrous卷积(
为了解决第一个问题,文章建议使用Atrous卷积,也成为扩张卷积。它提出通过使用Atrous卷积来扩大视野,因此包含了多尺度上下文,来解决第二个问题。
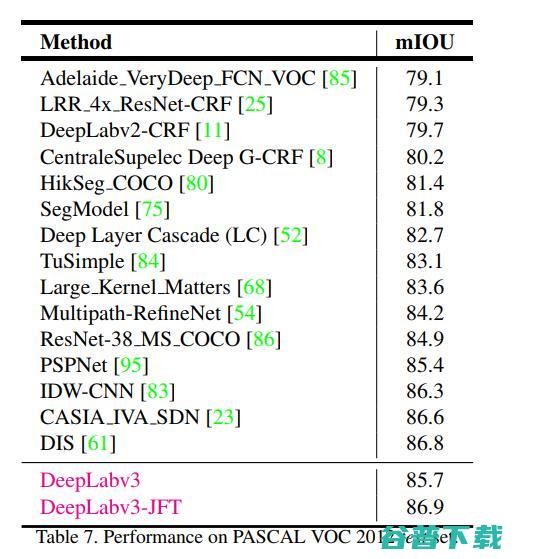
在没有DenseCRF后处理的情况下,本文的'DeepLabv3'在PASCAL VOC 2012测试集上达到了85.7%的准确率。
08.基于空洞可分离卷积编解码器的图像语义分割(ECCV, 2018)
本文的方法“DeepLabv3+”,在无需对PASCAL VOC 2012和Cityscapes数据集进行任何后期处理的情况下,测试集性能分别达到89.0%和82.1%。该模型是DeepLabv3的扩展,通过添加一个简单的解码器模块来细化分割结果。
基于空洞可分离卷积编解码器的图像语义分割

图源:
本文实现了两种使用空间金字塔池化模块进行语义分割的神经网络。一种方法通过融合在不同分辨率下的特征来捕获上下文信息,而另一种方法则着眼于获得清晰的目标边界。
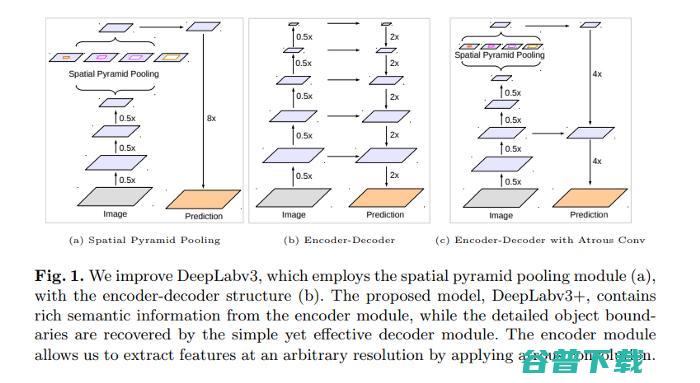
图源:
09.FastFCN:重新思考语义分割模型主干中的扩张卷积(2019)
文章提出了一个联合上采样模块,命名为联合金字塔上采样(JPU),以取代消耗大量时间和内存的扩张卷积。它的工作原理是将获取高分辨率图像的任务转化为联合上采样问题。
重新思考语义分割模型主干中的扩张卷积( )
该方法在Pascal Context数据集上实现53.13%的mIoU性能,运行速度提高了三倍。
图源:
该方法实现了全连接网络(FCN)作为主干,同时应用JPU对低分辨率特征映射进行上采样,从而生成高分辨率的特征映射。用JPU代替扩张的卷积不会导致任何性能损失。
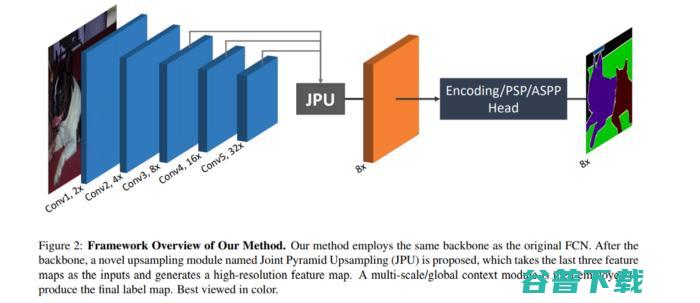
图源:
10.通过视频传播法和标签松弛法优化语义分割(CVPR, 2019)
通过视频传播法和标记松弛法优化语义分割()
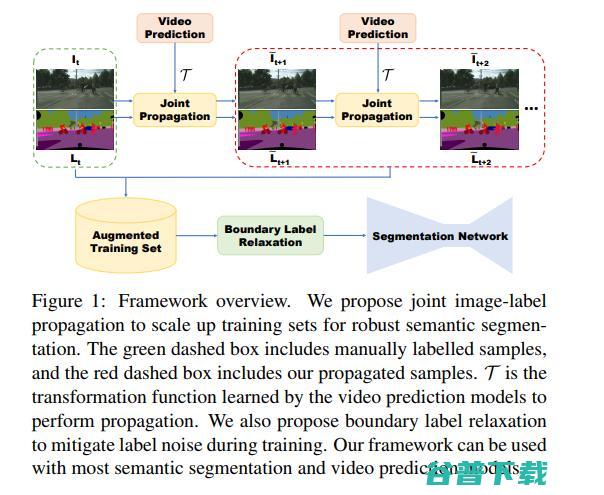
来源:
利用合成数据集对分割网络进行训练,提高了预测精度。本文所提出的方法在Cityscapes数据集上可以达到83.5%的mIoUs,在CamVid数据集上可以达到82.9%的mIoUs。
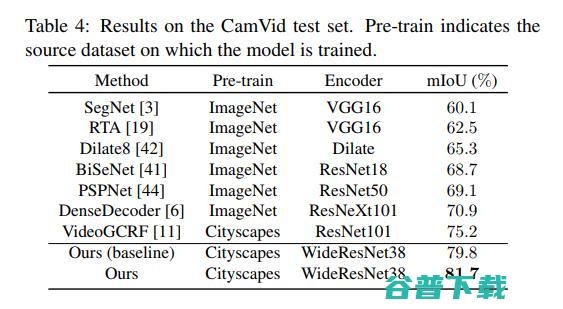
图源:
本文主要有三个命题;利用视频预测模型将标签传播到相邻帧,引入图像-标签混合传播法来处理图像的不对齐问题,并通过最大化联合类概率似然函数来松弛one-hot标签的训练。
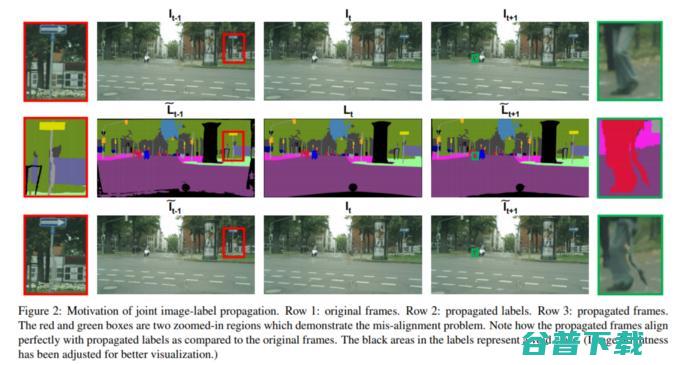
图源:
11.门控 SCNN:用于语义分段的门控形状CNNs(2019)
这篇文章是语义分割模块的最新进展。作者提出了一种双流CNN架构。在此体系结构中,形状信息作为单独的分支处理。该形状流仅处理边界相关信息。这由模型的门控卷积层(GCL)和本地监督强制执行。
门控SCNN:用于语义分段的门控形状CNNs(2019,
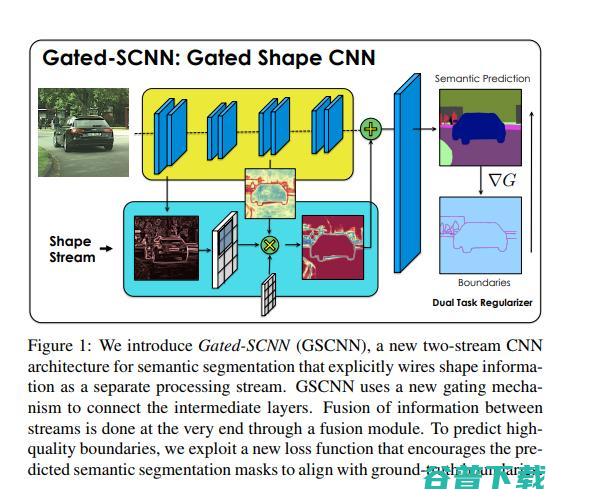
该模型在mloU上的表现优于DeepLab-v3+ 1.5%,在F界面得分上优于4%。该模型已使用Citycapes基准进行评估。在较小和较薄物体上,该模型在IoU上实现7%的改进。
下表显示了Gated-SCNN和其他模型的性能比较
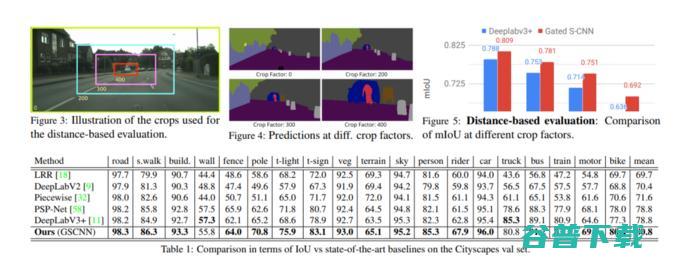
我们现在应该跟上一些最常见的,以及集中最近在各种环境中执行语义分割的技术。
上面的文章/摘要包含其代码实现的链接。我们很高兴看到您在测试后获得的结果。
Via:
想要继续查看该篇文章相关链接和参考文献?
点击【 2019 语义分割指南 】即可访问~
福利 大放送——满满的干货课程免费送!
「好玩的Python:从数据挖掘到深度学习」该课程涵盖了从Python入门到CV、NLP实践等内容,是非常不错的深度学习入门课程,共计9节32课时,总长度约为13个小时。。
课程页面:
「计算机视觉基础入门课程」本课程主要介绍深度学习在计算机视觉方向的算法与应用,涵盖了计算机视觉的历史与整个课程规划、CNN的模型原理与训练技巧、计算机视觉的应用案例等,适合对计算机视觉感兴趣的新人。
课程页面:
现AI研习社将两门课程免费开放给社区认证用户,只要您在认证时在备注框里填写「Python」,待认证通过后,即可获得该课程全部解锁权限。心动不如行动噢~
认证方式:


百度贴吧——全球领先的中文社区。贴吧的使命是让志同道合的人相聚。不论是大众话题还是小众话题,都能精准地聚集大批同好网友,展示自我风采,结交知音,搭建别具特色的“兴趣主题“互动平台。贴吧目录涵盖游戏、地区、文学、动漫、娱乐明星、生活、体育、电脑数码等方方面面,是全球领先的中文交流平台,它为人们提供一个表达和交流思想的自由网络空间,并以此汇集志同道合的网友。

中国民主促进会网站是中国民主促进会中央委员会的门户网站,于2002年创建,2003年6月正式开通。网站的宗旨和定位是,为统一战线服务,为民进工作服务,为民进会员服务,为“民进之友”服务。自开通至今十余年来,民进网站坚持内容为王和需求至上的原则,不断改造升级,进一步完善栏目,已逐步发展成为具有鲜明民进特色的网站。

LOL网址导航网是专业的上网导航网站,精心收录各类优质热门网站信息,同时提供天气、快递、违章等各种生活便民查询工具网址,为您提供安全便捷的上网导航服务,现已被众多网友设为上网主页,网址导航大全首选LOL网址导航.

安徽省成人高考网是提供:安徽成人高考、安徽成教、安徽专升本、安徽省教育招生考试院、安徽省教育厅、安徽函授本科、安徽成人高考报名时间、安徽成人高考考试科目、安徽成人高考录取分数、安徽成人高考成绩查询、安徽成人高考录取查询的公益服务网站。

天长市正业测控仪表有限公司是一家集设计_研发_生产和销售于一体的变送器厂家;主要产品有:压力变送器,差压变送器,单晶硅变送器,液位变送器等,广泛应用于石油开采-火力发电-矿山机械设备等行业.

上海圣界电子科技有限公司,自1999年开始深入与研华合作,代理研华工控机、工业级arm主板、一体机、单板电脑等全系列产品,并开展系统集成相关技术服务,多年合作已成为研华信任的经销商。

深圳市精工彩包装制品有限公司

一起自由行,这里收集整理了自助游,自由行,旅游攻略,旅游指南,旅游经验分享等。带你自由行,尽在攸游日记。

无锡芃禾智能科技有限公司(以下简称“芃禾智能”)成立于2024年11月06日,是聚焦物联网、工业互联网等设备生产研发的科技型企业,同时与国内多个知名厂商合作,代理集成虚拟仿真、思政党建、集成电路、智能制造、新能源汽车、轨道交通、电工电子、机器人、人工智能、电子商务等专业实验实训室建设。

周口市物业服务行业协会

希沃学苑,教师专属信息化教学技能提升平台,致力于K12领域信息化教学技能培训,为广大教师提供微课制作、信息化教学软件体系化课程,分享名师教学经验,共享优质教育资源

爱普搜社区网站是汽车配套行业的专业商务社区,爱普搜汽车社区提供:汽车零部件配套采购商机,汽车零部件配套供应商展示,采购商与供应商在线交流。


根据酷开官方信息,酷开电视P31Max系列、酷开电视P31系列、酷开电视P532023款系列及酷开电视Max86四大型号电视为2022,2023最推荐型号,值得注意的是,以上四款型号酷开电视均为大屏尺寸,1、酷开电视P31Max系列65英寸活动价2599元,75英寸3999元酷开电视P31Max主打,超质价比120Hz体育电视,,具有...。

今早我下去买早点,排队时旁边一大姐手机里的歌声把我逗乐了,你把我灌醉,你让我心碎,爱都收不回,与此同时,让我想起了十几年前的网络情感神曲,有一种爱叫做放手,为爱放弃天长地久,说来也是奇怪,有一些歌很没品位,但总有人把它当宝贝,可能也是唱到心里去了吧,产生了情感共鸣,其实这种两极分化的现象在互联网上十分普遍,你认为的...。

微信群、朋友圈里频繁出现的,漏洞券,,多是商家通过淘客或者第三方APP故意放出,双11前,一则商家被羊毛党薅倒的消息在全网炸开了锅,事发的,果小云旗舰店,店家称,自己失误将原本26元4500克的脐橙标成了26元4500斤,面对一夜之间被拍下的几万个订单实在无力发货,求卖家,留一条生路,店家农民的身份、,凑钱开店,的心酸、一人承担的仗...。

春季回暖,草木萌动,万物生机待发,人的新陈代谢在此也比较旺盛,真正的春日养生秘籍,不是多贵的护肤品,而是——睡个好觉,2021·SPRING近期,#超3亿人存在睡眠障碍#登上热搜,调查显示,当下我国超3亿人存在睡眠障碍,其中,超3,4的人晚上11点以后入睡,近1,3的人熬到凌晨1点以后才入睡,01、印花睡裙春季升温,解锁家居新品,舒适...。

2024年法国夏季奥运会赛事正酣,即便相隔数千公里,国内观众也感受到了火热之势,乒乓球混双夺冠、羽毛球混双夺冠、网球女单夺冠……中国运动员每一次站上领奖台,都收获了广泛关注,随着奥运赛程的推进,以及近年来国人健康生活意识增强,体育运动消费热度持续攀升,在中国优势,三小球,征战巴黎之际,国内消费者也用真金白银表达了对体育运动的热爱,拼多...。

黑幕、机器人、流动行驶的车辆….今天下午,毫末智行在流动着科技与未来气息的幕布背景下,于线上正式举办,HAOMOAIDAY,,一股浓浓的技术风,活动现场,毫末智行董事长张凯、CEO顾维灏共同细数了他们近一年来的亮眼成绩单,1、截至12月用户行驶里程近400万公里;今年第四季度正式上线的智慧领航辅助驾驶系统NOH,2、截至目前,毫末智行...。

北京时间10月28日,商汤科技和AI研习社共同举办决策智能系列公开课,对如何提高决策AI通用能力、泛化能力和适应能力以及复杂场景下AI鲁棒性进行介绍,AI科技评论对此公开课做了不改变原意的整理,摘要人工智能技术已经进入从感知智能到决策智能演变的关键节点,决策AI技术的前沿进展和突破也到了在实际场景部署和应用的阶段,决策AI技术应用的成...。

很多人都想创业,并且纷纷将目光聚焦在了餐饮行业,面馆作为快时尚的餐饮项目,制作方便快捷,因而受到了很多创业新手的追捧,想要创业容易,但是真正做起来却很困难,创业者新书要做好充足的准备工作才行,为了帮主新手更好地创业,今天小编就来为大家介绍新手开面馆要怎么做,先是要进行地域调查,根据地区的特征,确定所开设的面馆类型,现有的面馆类型包括兰...。

制造业数据的指数级增长,就像当年阿里巴巴的‘双11,购物节一样,在这样的景象下,作为一名数据从业者,我感到异常兴奋,这种熟悉的感觉仿佛让我回到了过去,但这一次,我站在了一个全新舞台,曾在阿里工作多年的奇点云CTO地雷,他的眼神中透露出热情与期待,简单来说,他们是独立第三方的大数据基础软件厂商,成功实现与全球十大IaaS云服务商的兼...。

正义网记者7月3日从最高人民检察院得知,山东省委第四巡视组原组长马玉星,正厅级,涉嫌行贿一案,由山东省监察委员会考查终结,移送检察机关审查起诉,日前,山东省人民检察院依法以涉嫌行贿罪对马玉星作出拘捕选择,该案正在进一步操持中,常年在山东任职地下资料显示,马玉星,男,汉族,1961年4月生,山东济南人,中央党校大学学历,1981年10月...。

[中国国防部长,#请各国管好自家的军舰飞机#]当天,第二十届香格里拉对话会上,中国国防部长李尚福回应所谓,中国军机阻拦美国军机,的提问,他示意,我要反诘一下,为什么刚才大家提的疑问都出当初中国领空和领海左近,而不是出当初其余国度的领空和领海左近,这是由于中国的军机和军舰素来不会到其余国度的领空和领海左近去做所谓的飞行霸权,最好的方法...。

何猷君荣获财富中国精英称号,奚梦瑶和婆婆坐在台下鼓掌欢庆,模特,奚梦瑶,何猷君,梁安琪,何鸿燊,中国精英,赌王家族

比较热门的单机游戏有哪些,毕竟现在也有一些玩家对单机游戏是比较感兴趣的,因为单机游戏不需要连接互联网,直接挂机也可以刷怪,但是玩家在挑选单机游戏的时候,往往也会注重相关的细节,下面小编就简单的分享2023高人气的单机手游,相信以下5款单机手游,玩家是会非常喜欢的,说到贪吃蛇,其实很多玩家对它印象深刻,而它也是一款比较经典的游戏,要说贪...。

每每走进一个小店中,明明只是想买一瓶水,但却因为营业员总是跟着你,各种推销,不知不觉就多花了很多钱,所以,当自动售卖机出现时,人们对于这种消费方式是好奇的,同时也是喜欢的,因为可以省去很多在沟通上的麻烦,对于创业者来说,自动售卖机的出现,就是多给了他们一条创业路,那么自动售卖机加盟好吗,快跟着小编一起来了解一下吧!自动售卖机加盟好吗,...。

冷启动推荐一直是推荐系统中一个极具挑战的问题,跨领域推荐系统使用源领域中的交互数据来帮助目标领域的冷启动推荐,这篇文章提出了一种个性化迁移用户兴趣偏好的跨领域推荐的方法,给目标领域冷启动用户进行更精准的推荐,本文基于论文,PersonalizedTransferofUserPreferencesforCross,domainRecom...。

身为工业互联网的,局中人,,相信没有人不知道,双跨,平台,这既是当下中国工业互联网的行业现状,更代表着创新发展的风向,2017年,2018年,当工业互联网在国内兴起时,业内爆发了,平台热,,一些来自家电、机械、石油化工等领域的龙头都发布了工业互联网平台,如今经过几年的摸索,国内逐渐培育出一批,双跨,平台,引领着工业互联网行业走向大规模...。

云出海已经不是新鲜话题,但国内云厂商如何争夺海外市场始终是市场关注焦点,2016年,腾讯云宣布进入国际市场,并把离家近、文化相近、熟人也多的东南亚作为主攻市场,出海打价格战,可能是最差的一个选择在进军新市场时,,价格战,常常成为了进攻者手中紧握的一张王牌,在云计算领域也同样如此,去到海外,到底要不要打价格战,回答要不要打价格战之前,应...。
