神经机器翻译的混合交叉熵损失函数 (神经机器翻译的单词错误减少了)

本文提出了一个新的损失函数,混合交叉熵损失(), 用于替代在机器翻译的两种训练方式(Teacher Forcing和 Scheduled Sampling)里常用的交叉熵损失函数(CE)
,计算开销基本和标准的CE持平,并且在多个翻译数据的多种测试集上表现优于CE。这篇文章我们简要介绍Mixed CE的背景和一些主要的实验结果。
本节简单介绍一下 Teacher Forcing 和 Scheduled Sampling 的背景。
Teacher Forcing[1]训练方式指的是当我们在训练一个自回归模型时(比如RNN,LSTM,或者Transformer的decoder部分), 我们需要将真实的目标序列(比如我们想要翻译的句子)作为自回归模型的输入,以便模型能够收敛的更快更好。 通常在Teacher Forcing(TF)这种训练方式下,模型使用的损失函数是CE:

值得注意的是,机器翻译(MT)本身是一个一对多的映射问题,比如同样一句中文可以翻译成不同的英文,而使用CE的时候,因为每个单词使用一个one-hot encoding去表示的,这种情况下MT是被我们当作了一个一对一的映射问题。这种方式可能会限制模型的泛化能力,因为使用CE的模型学到的条件分布
 更接近于一个one-hot encoding,而非数据真实的条件分布
更接近于一个one-hot encoding,而非数据真实的条件分布
 。但不可否认的是,即使模型用CE训练,它在实践中也取得了很好的效果。CE在实践中的成功意味着模型学习到的条件分布
。但不可否认的是,即使模型用CE训练,它在实践中也取得了很好的效果。CE在实践中的成功意味着模型学习到的条件分布
 可能也包含着部分真实分布
可能也包含着部分真实分布
 的信息。我们能不能在训练的时候从 提取
的信息。我们能不能在训练的时候从 提取
 的信息呢?这就是我们的Mixed CE所要完成的目标。
的信息呢?这就是我们的Mixed CE所要完成的目标。
虽然TF训练方式简单,但它会导致exposure bias的问题 ,即在训练阶段模型使用的输入来自于真实数据分布,而在测试阶段模型每一时刻使用的输入来自于模型上一时刻的预测结果,这两个输入分布之间的差异被称作exposure bias。
因此,研究者们进而提出了Scheduled Sampling[2](SS)。 在自回归模型每一时刻的输入不再是来自于真实数据,而是随机从真实数据或模型上一时刻的输出中采样一个点作为输入。 这种方法的本质是希望通过在训练阶段混入模型自身的预测结果作为输入,减小其与测试阶段输入数据分布的差异。也就是说,SS所做的是让训练输入数据分布近似测试输入数据的分布,从而减轻exposure bias。
而另一种减轻exposure bias的思想是,即使训练和测试阶段输入来自不同的分布,只要模型的输出是相似的,这种输入的差异性也就无关紧要了。我们的Mixed CE就是想要达到这样的目标。
需要注意的一点是,SS本来是用于RNN的,但由于Transformer的兴起,后续的研究者们提出了一些改进的SS以便适用于Transformer decoder在训练阶段能够并行计算的特性。即运行Transformer deocder两次,第一次输入真实的数据
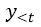 ,然后从t时刻的输出分布里采样一个数据点
,然后从t时刻的输出分布里采样一个数据点
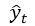
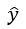 。接着,将
。接着,将
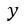 里面的元素随机进行混合,得到新序列
里面的元素随机进行混合,得到新序列
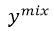 作为decoder的输入,按照正常方式进行训练。
作为decoder的输入,按照正常方式进行训练。
我们提出的Mixed CE可以同时用于TF和SS两种训练方式中。
在TF中,为了应用MixedCE,我们首先做出一个假设: 如果模型当前预测的概率最大的token和目标token不一致,那我们认为预测的token很有可能是目标token的同义词或者同义词的一部分。
我们做出这个假设是因为在实际中的平行语料库里,同样一个源语言的单词在目标语言会有多种不同的翻译方式。如果这些不同的翻译在语料库里出现的频率相差不多,那么在预测该源语言单词时,模型非常有可能给这些不同的翻译相似的概率,而概率最大的那种翻译方式恰好是目标token的同义词。
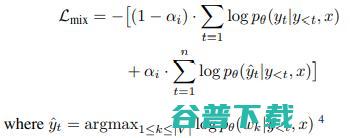
是模型在当前时刻模型预测的最有可能的结果,而根据我们之前的假设,
的同义词。Mixed CE通过以
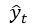 作为目标进行优化,有效利用了
作为目标进行优化,有效利用了


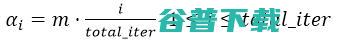
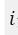 是当前训练的iteration,total_iter代表了总的训练轮数。随着训练的进行,模型的效果越来越好,
是当前训练的iteration,total_iter代表了总的训练轮数。随着训练的进行,模型的效果越来越好,
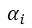 会不断增大,Mixed CE中第二项的权重也就越大。
会不断增大,Mixed CE中第二项的权重也就越大。
在SS中,Mixed CE的形式类似于上述公式:
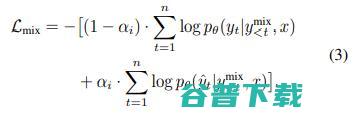
这里的
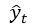 是对第一次运行Transformer decoder的输出进行greedy采样的结果。第一次运行Transformer decoder时的输入是真实的目标序列,而第二次运行时的输入是序列
是对第一次运行Transformer decoder的输出进行greedy采样的结果。第一次运行Transformer decoder时的输入是真实的目标序列,而第二次运行时的输入是序列
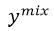 。通过优化这个目标函数的第二部分,无论模型输入是
。通过优化这个目标函数的第二部分,无论模型输入是
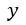 还是
,模型总是能够输出相似的结果,也就是说,
模型能够忽略输入分布的差异,从而减轻了exposure bias的问题。
还是
,模型总是能够输出相似的结果,也就是说,
模型能够忽略输入分布的差异,从而减轻了exposure bias的问题。
值得注意的是,相比于CE,Mixed CE在训练期间只增加很少的计算量,额外的计算量来自于寻找模型预测结果的最大值。
由于篇幅有限,我们只列出几个重要的实验结果,更详细的实验结果可以在原文中找到。
在TF训练方式中,我们在WMT’14 En-De上的multi-reference test set上面进行了测试。在这个测试集中,每个源语言的句子有10种不同的reference translation,我们利用beam search为每一句源语言句子生成10个candidate translations,并且计算了每一个Hypothesis相对于每一种reference translation的BLEU分数,并且取它们的平均值或者最大值。结果如下:
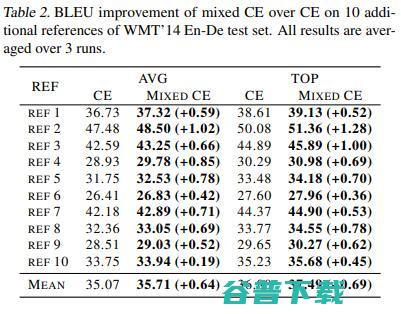
我们可以看到Mixed CE在所有reference上面始终优于标准CE。
另外,我们也在一个paraphrased reference set(WMT’19 En-De)上面进行了测试。这个测试集里面的每一个reference都是经过语言专家的改写,改写后的句子结构和词汇的使用都变得更复杂。结果如下:
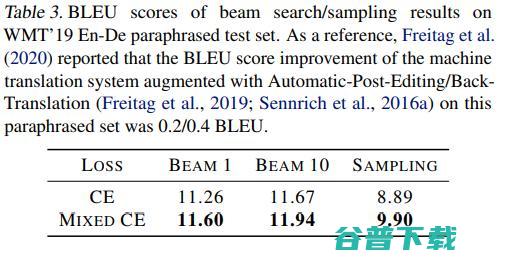
通常在这个测试集上,0.3~0.4 BLEU的提升就表明效果就很显著了。
由于Mixed CE的形式类似于label smoothing,所以我们也具体比较了Mixed CE和label smoothing。我们利用Pairwise-BLEU(PB)衡量模型输出分布的平滑程度,PB越大,输出分布越陡峭,反之则越平滑。结果如下:
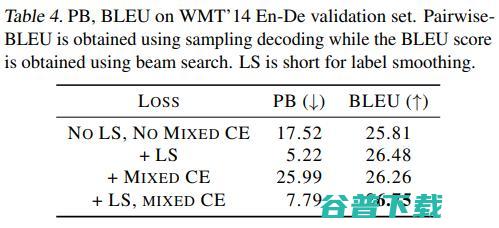
可以看到,加入label smoothing之后,输出分布变得更加平滑,而Mixed CE使得输出分布变得更加陡峭。所以Mixed CE和label smoothing是不同的。并且从BLEU的分数可以看出, label smoothing和Mixed CE并不是一个互斥的关系,两者共用效果会更好。
在SS中,我们以SS和word oracle(SS的一个变种)作为Baseline。结果如下:

可以看到Mixed CE总是好于CE。此外,我们在论文中还提供了ablation study,以确认 Mixed CE中的第二项对性能的提升是必不可少的。
此外,我们在附录中也列出了一些关于domain adaptation的初步实验,欢迎大家继续探索Mixed CE在其他领域的应用。
在本文中我们提出了Mixed CE,用于替换在teacher forcing和scheduled sampling中使用CE损失函数。实验表明在teacher forcing里,Mixed CE在multi-reference, paraphrased reference set上面的表现总是优于CE。同时,我们也对比了label smoothing和Mixed CE,发现它们对输出分布的影响是不同的。在scheduled sampling当中,Mixed CE能够更有效的减轻exposure bias的影响。

若二维码过期或群内满200人时,添加小助手微信(AIyanxishe3),备注ICML2021拉你进群。
特约稿件,未经授权禁止转载。详情见 转载须知 。



抖音来客

学习啦在线学习网是免费的技能、特长、知识综合学习网站,提供各行各业学习资讯供大家学习参考,如学习方法交流、智力测试、记忆力训练、电脑教程、英语学习教程、职场攻略、励志故事、各种实用生活百科知识等等!

爱站网信拦截检测主要是检测域名是否被微信拦截,微信终端是否能够直接打开网站,从而了解域名在微信实时的状态,以避免微信用户打不开网站从而导致用户流失。

爱发表网(ifabiao.com)具有多年期刊服务经验,一对一客服在线咨询,多种方案满足您的定制化需求,不成功可退款的期刊咨询服务网站,刊物信息可到国家新闻出版总署查询,订阅杂志简单快捷、放心可靠!

嘻游猫致力于打造最全面的旅游问答平台,提供国内最新的旅游景点详情及旅游攻略、旅游景点门票、旅游线路、旅游天气、热门游记,以及最全面的自驾游、自由行旅游指南,实现旅游的零地域性。

沈阳敏丝瑞科技有限公司

甜啦啦是安徽汇旺餐饮管理有限公司品牌,以甜啦啦奶茶,冰淇淋,饮品店品牌,凭借着高质量的产品、良好的信誉、优质的服务和完善的团队获得广大创业者和消费者一致好评!

温州贮净环保科技有限公司位于温州,主营净水设备、污水设备、检测设备、消毒设备、空气净化器、除尘设备、废气处理设备等产品。

佛山视康医疗器械有限公司专注于眼科产品研究、开发、生产、销售、培训于一体的现代综合性高科技企业,获得多项发明专利。始终以“开拓创新,回报社会,服务用户,为人类的眼健康事业作贡献”为经营宗旨。公司秉承“诚信为本、质量为先、服务至上、追求卓越”的服务理念持续、健康的发展。我们愿与社会各界有志之士携手并进,共创未来!

海口市连年胜贸易有限公司海口市连年胜贸易有限公司

24小时家电维修服务中心为您解决家用电器故障问题,包括家电安装,移机,漏水,清洗,拆装,声音大,噪音处理,不制冷,不制热,有异味,跳闸以及故障代码等,120MAP一站式家电维修服务平台.

Businnes,Portfolio,Corporate


近日,第六届全球人工智能与机器人大会,GAIR2021,在深圳正式启幕,140余位产学领袖、30位Fellow聚首,从AI技术、产品、行业、人文、组织等维度切入,以理性分析与感性洞察为轴,共同攀登人工智能与数字化的浪潮之巅,在医疗科技高峰论坛上,AIMBEFellow、深圳理工大学计算机科学与控制工程院院长潘毅以,人工智能在生物医疗学...。

5月18日,腾讯发布2022年第一季度业绩报告,其中,金融科技及企业服务,单季收入428亿元,占总营收32%,财报指出,腾讯ToB业务主动调整收入结构,放弃了部分亏损订单,同时,在视频云、网络安全等PaaS领域加大资源投入,去年此时的腾讯云与智慧事业产业群,CSIG,,正好完成新一轮战略调整,确定了深耕行业、深耕区域、提升效率三大方向...。

信息科技愈来愈比较发达,现代化实际操作也绝大多数由机器人替代人工服务,不但释放人力资本还能提升生产率,而在家中智能化层面,机器人在将来必定会变成人们的暖心女保姆,现如今,现有一部分作用的家用的机器人问世,一经发售便得到众多顾客的眼光,人们也是看好了这新时期的物质创业商机,那么,家用机器人加盟代理哪家好,1、爱乐优在销售市场上的准确定位...。

现场视频丨菲方船只故意冲撞我舰艇中国海警正告菲方正视事实、丢弃空想中国海警局资讯发言人刘德军示意,8月31日08时02分,菲律宾合法滞留中国仙宾礁的海警9701号船起锚,位仙宾礁潟湖内继续机动、寻衅肇事,中方海警5205舰依法依规对9701号船采取喊话正告、跟监管控等措施,12时06分,菲9701号船以不专业、风险模式故意冲撞中方反常...。

焕新升级,第11届TMA(TopMobile&AI)大奖正式启动!,top,tma,评审团
美团作为外卖平台有检查监视商家的责任,在明知商家杨国福麻辣烫违规收取生产者打包费的疑问,束之高阁,揭发后不处置疑问,没有任何处置打算等,我置信大局部人都吃过麻辣烫,只要一个打包盒、一次性性餐具包、一个个别的塑料袋,收取打包费5.66元,原本麻辣烫曾经在抖音等上抢手了被生产者戏称某某珠宝店,蔬菜按根卖,汤底也要不要钱等,如今依然存在其余...。

央视网信息,作为中孟两国,一带一路,框架下的关键协作名目,由中国中铁承建的孟加拉国帕德玛大桥铁路衔接线名目标树立将在往年片面收官,这条线路北起首都达卡,超越帕德玛河一路向南加长至杰索尔,被外地人称为,幻想之路,终究这条线路为孟加拉国人成功了什么幻想呢,跟咱们的记者一同去实地体验一下,达卡火车站是孟加拉国最大也是最忙碌的车站,一进到外...。

以下表格为日历查问表,1992日历表,1992年农历表,农历阳历转换,还蕴含了,节日、二十四节气的表现等等,繁难大家的查问和对照,假设您的日常生存中也很须要,无妨点击将该表格收藏至您的电脑中,以便日后的查问与参照,日历表说明,淡蓝色代表二十四节气日,白色代表传统节日,1992年1月农历辛未,羊,年庚子月建国43年1992年2月农历辛未...。

本田City是一款小型车,中文名字,锋范,新一代锋范的市场定位是家庭用车,前期的爱护老本较为低,锋范与飞度相似,都是专为市区下班代步的个体设计,并且也很适宜刚刚开局任务的青年人,锋范的外型就如其名,时兴老练,外部空间不大,紧凑感满满,然而其搭载了与新飞度相反的能源总成,使得油耗以及能源都十分杰出,本田锋范基于飞度底盘打造,在中国由广...。

奥迪S5敞篷版是一款专为速度喜好者打造的小众车型,它搭载全时四驱系统,能源澎湃,驾驶体验热情四溢,<,相比之下,A5的前轮驱动车型虽然驾驶更为温馨,但性能雷同弱小,关于估算有限的消费者,A5敞篷车也是一个值得思考的选用,<,在性能上,S5提供了更初级的19英寸轮圈、静止座椅和换挡拨片等,虽然S5的多少钱相对较高,但...。

不要钱,观众可以经过咪咕视频客户端,在手机、PAD、电脑上不要钱观看2022年乒乓球亚洲杯的直播,本次较量将于11月17日至19日在泰国曼谷举办,赛事包含男女单打两个名目,咪咕视频体育直播1.咪咕视频提供体育直播服务,用户可以不要钱观看,2.该平台上的短视频、影视、综艺等外容雷同不收取费用,3.咪咕视频为用户提供了高品质的直播体验,无...。

广州网易房产为您提供广州城投·领南府楼盘售楼处电话:4001-666-163转23069、最新房价参考:43500元/㎡、户型图、实景图和周边配套等最新楼盘详情信息,买新房尽在广州网易房产!

对想要做生意,成交自我价值的人而言,引流就是成交的开始,但是很多初次做项目的人,或者对营销、对人性还没有深度思考过的人,就会犯最常见的错误——粗暴刷屏,相信大家看到这种粗暴的刷屏行为,即使是好朋友发的,也会选择仅聊天可见,刷屏行为犯了什么忌讳?看似是勤快地做事,其实是为了偷懒,连顾客的需要都没有认真想过,就一顿无脑复制、粘贴,不尊重朋...。

经过整日劳累的工作之后,很多人都会选择到足疗店来放松,现在的足疗店不仅提供足部护理,还提供全身按摩等服务,在为消费者带来好的体验后,也吸引了很多创业者前来加盟,但是,大部分创业者都有这样的疑问,那就是怎样加盟足疗店,今天,小编将介绍汉唐足疗店,来解答这个疑问,创业者加盟汉唐足疗店,需要经过八个主要的步骤,只有严格执行总部给予的流程,才...。

时下,房地产市场的火热大家有目共睹,放到创业开店领域,与之同来的便是成本的持续走高,由此,很多创业者大呼吃不消,他们毅然决然地选择放弃,并将创业的目光投向了颇具潜力的小城市,因而,迫切地想知道小城市创业好项目,那么,接下来,小编急人所难,为大家专门进行项目推荐,不要错过哦!1、产后恢复,在大城市,大多数的中青年一族,工作多,时间紧,、...。

发表在专业问答2022,8,1312,19展示机型信息,品牌型号,极米H5系统版本,GMUI5.0极米H5的遥控器需要同时按住返回键和主页键并靠近投影仪去配对,且遥控器的连接方式是通过蓝牙进行连接的,以下是具体的遥控器配对方法,极米H5遥控器如何重新配对1.遥控器靠近投影先拿起极米H5投影仪的遥控器并靠近到极米投影仪20cm内;2.进...。

陈慧琳分享最新写真照,大秀小巧曲线形态佳,并配文,车祸后第一个照片拍摄,面部仍未齐全消肿,还有些痛,她还暖心送出新年祝愿,,祝大家兔年吉星拱照,最关键是出入安康!,...。
