深度解析苹果A12处理器 性能和能耗比令安卓旗舰SoC汗颜 (苹果手机深度解析需要多久)
过去的几年里,苹果的芯片设计团队一直在架构设计和制造工艺两条路线上稳居业界最前沿,此番随新一代iPhone XS一齐亮相的A12处理器同样保持了这份优良传统,它是业界第一个实现量产应用的7nm移动SoC芯片。
此前在雷锋网《 详细解读7nm制程 》一文中我们曾介绍过,一般来说制程的数字越小,晶体管的Metal Pitch和Gate Pitch等特征尺寸就越小。虽然最近几年制程的命名逐渐脱离了与实际物理尺寸之间的关联而转向商业化名称,但它们仍然代表着晶体管密度的飞跃,供应商能够在相同的芯片面积中塞入更多晶体管以提升性能。
不久前,外媒TechInsights对iPhone XS进行了拆解并为A12芯片进行了X光扫描,我们可以借由他们分享的透视图对A12进行一波深入的分析和猜想。

A12的主要性能模块均位于芯片的右方和下方,其中最右侧是占地面积最大的GPU集群,4颗核心2*2对称排列,将一小块公用电路夹在中间。左侧紧挨着GPU集群中腰的是CPU和GPU的共享缓存(L3缓存),下方是低功耗CPU核心集群,左方是的高性能CPU核心集群,最左边则是8核NPU。
GPU和CPU的共享缓存是整个SoC缓存体系的一部分,层级位于内存控制器和独占缓存之间。由于处理器访问内存要消耗掉大量电力,使用片上共享缓存可以节能降耗,且由于数据的局部性,性能还会有所提升。
从图上可以看出,A12的共享缓存被划分成了4个区块,而此前自A7至A11这5代处理器均为2区块设计。缓存区块的加倍很有可能代表着缓存性能有了很大提升,这个在稍后的测试中再见分晓。
最后, NPU可以说是此次A12中进化幅度最大的一个性能模块,核心数从A11的双核激增为8核,实际性能更是从A11的0.6TOP暴涨至5TOP,提升近9倍。需要注意的是,有传言称此前A11的NPU使用的是CEVA的架构设计,不过直到现在也没有得到证实,而此次苹果A12的网页上明确提到了“Apple-designed”,这意味着这次的NPU架构的确是出自苹果的自主研发。
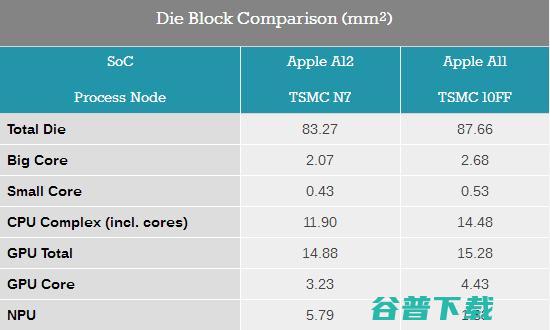
纵观A11和A12中不同模块的面积变化,可以清晰的看到台积电全新7nm制程的优势。鉴于几乎所有的模块架构都有了变化,无法计算出7nm制程的晶体管密度有多大提升,不过若以单个GPU核心作为参考,在A12中相比A11中的面积减小了37%。
此次A12的大核心代号为“Vortex(旋风)”,相比A11的“Monsoon(季风)”最大的改进在于L1数据缓存和指令缓存双双翻倍,均从64KB增加到了128KB。人们一直很想搞清楚的一个问题是,苹果处理器的缓存体系到底具有怎样的结构,现在我们可以通过使用不同队列深度测试内存延迟来一窥端倪。

测试结果是,L1缓存的延迟拐点从64KB转移到了128KB,这很正常,但在L2缓存的延迟在3MB~6MB范围内会一直持续增加,而这种情况仅在以完全随机的模式访问时发生,在较小的访问窗口中,L2缓存的延迟从3MB到6MB又是一直平坦的。

在队列深度超过L2缓存的容量后,Monsoon核心的延迟曲线会进一步增加4MB左右,Vortex核心的曲线则会一直延续8MB,这便是二者的共享缓存容量范围,再往后便进入了内存的领域。这与在芯片透视图上实际看到的情况很相符,A12的共享缓存不仅分区数量加倍,容量也从4MB增加到了8MB。
而代号为“Tempest(暴风)”的小核心这边情况则稍有些复杂,乍看之下可能会认为A11中代号为“Mistral(干冷的北风)”的小核心只有512KB L2缓存而A12则有1.5MB,但实际上这只是缓存电源管理策略造成的假象。通过延迟图表可以看出,Mistral核心在768KB和1MB处存在明显的波动,而Tempest核心的类似波动则发生在2MB处。
综合以上数据,可以得出下表中的数据:
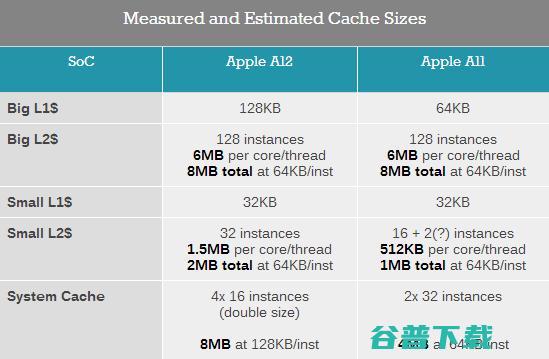
A12的大核心L2缓存结构相比A11没有任何变化,两者都有128个SRAM块,每个SRAM块大小为48KB。而A12的小核心L2缓存容量翻倍,意味着SRAM块数从16个增加到了32个。
不过,苹果在A11和A12上使用的缓存电源管理策略允许在数据粒度较小时只激活部分缓存电路,在A11上这个粒度应该是256KB,而在A12上这个粒度应该是512KB。这也让我们更加有理由认为A11的小核心L2缓存容量是1MB,A12则是2MB,这也意味着每个SRAM块大小为64KB。
然而再回过头看大核心,虽然我们之前认为其容量为6MB,不过仔细观察可以发现其曲线在8MB处有一些变化。曲线的变化预示着测试数据的尺寸正在接近缓存容量的边界,这使我们猜测A11和A12的大核心实际上有8MB L2缓存。
总而言之,苹果处理器的缓存方面毫不吝惜晶体管的使用,A12在这方面则更进一步,整颗SoC上的各级缓存超过了16MB,这样不惜血本的规模真的足以让高通三星等公司同时期的旗舰产品无比汗颜。
在GPU方面,业界普遍对A12有着很高的期望,不仅仅是在性能方面,同样也在架构方面。
去年,Imagination发布了一份新闻稿,称苹果计划在未来15~24个月内不再在新产品中使用其知识产权。
撇去Imagination股票价格的崩溃以及随后卖身的命运不谈,尽管苹果确实声称A11的GPU为自主设计,但它看起来仍然像是从Imagination的Rogue架构衍生而来,依然是基于TBDR(Tile Base Deffered Rendering,Imagination的专利渲染技术),只不过A11 GPU一颗核心的规模就相当于A10的两颗而已。

而A12代号为“G11P”的GPU仍然与A11的GPU有着非常明显的相似之处,各个功能块似乎都位于相同的位置并以类似的方式构造。苹果表示A12 GPU最大的进步是支持显存压缩,而这也就意味着苹果此前使用的GPU都不支持显存压缩(喵喵喵???),以及显存压缩可以显著提升GPU性能。
所谓显存压缩,指的是从GPU到显存的透明帧缓冲区压缩。据雷锋网了解,PC端像NVIDIA和AMD这样的厂商已经应用这一技术N多年了,即使在内存带宽没有增加的情况下,它也能提高GPU的性能。移动SoC的GPU也需要内存压缩,这是因为移动SoC的带宽相比桌面级GPU更加有限。
Arm的AFBC是移动领域最公开谈论的显存压缩方案,高通和Imagination等其他厂商也都有自己的显存压缩技术。相比之下苹果在A12上刚刚引入这一功能似乎太晚了,不过这也意味着A12将从中获得效率和性能上的显著提升。
在谈及Vortex核心之前,首先需要了解一下苹果新SoC的频率。在过去几代中,苹果一直在稳步提高其大核心的频率,同时也提升了微架构的IPC。下表是A12和A11的频率表:
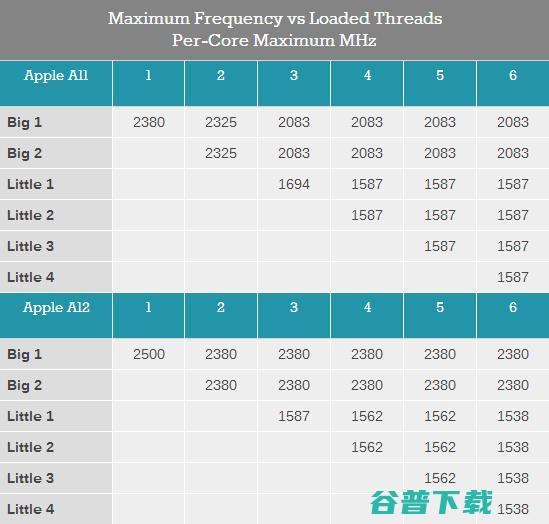
A11和A12在单大核心满载时的最高频率分别为2380MHz和2500MHz;双大核心满载频率分别为2325MHz和2380MHz。而在小核心加入工作后,A12的大核心频率仍被设计为稳定在2380MHz,而A11则会进一步下调至2083MHz。
与愈发激进的大核心相比,A12的小核心部分则更显保守。在只启动一颗小核心时,A11的频率为1694MHz,而A12则为1587MHz;启动两颗和三颗时A11为1587MHz,A12为1562MHz;而在四颗小核心满载时,A11仍能保持在1587MHz,而A12则进一步降至1538MHz。
正如之前所提到的,苹果在A12的缓存结构和内存子系统上投入了大量的工作。回到线性延迟图上,我们看到以下针对大核和小核的完全随机延迟的行为:
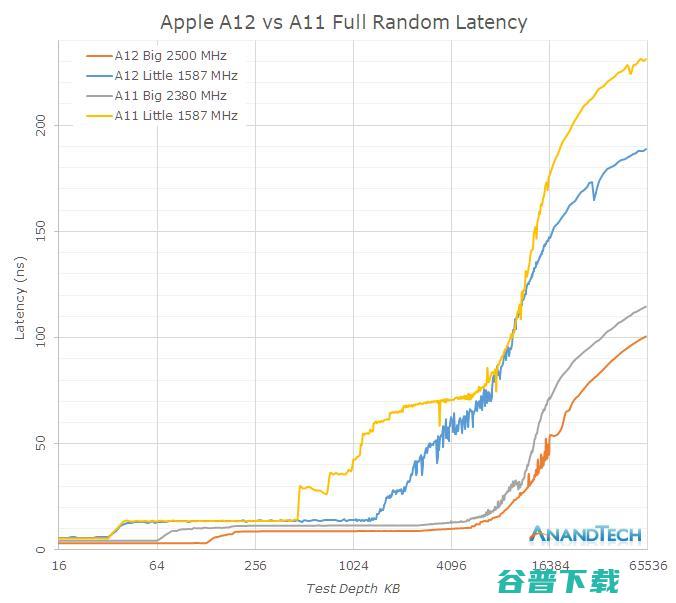
大核心方面,与A11的Monsoon核心相比,A12的Vortex核心仅有5%频率提升,但L2缓存的绝对延迟从约11.5ns降至约8.8ns,降幅高达29%,这意味着Vortex核心的L2缓存可以在更短的时间内完成读写访问。
小核心方面,A12的Tempest核心与A11的Mistral核心延迟表现相似,但A12在L2分区和电源管理方面又有了很大的变化,允许访问更大的L2物理区块。
这里只进行了64MB队列深度的测试,显然延迟曲线在这个数据集中并没有变得平缓,但可以看出内存延迟已经有所改善。当小核心处于活动状态时,内存控制器DVFS的最大频率会提高,这也是Tempest核心的内存访问存在较大的差异的原因:当大核心上有高负载时,它们的性能会更好。
A12的共享缓存也发生了巨大的变化,虽然缓存带宽相比A11有所降低,但访问延迟得到了很大改善。

由于苹果并没有像Arm和三星一样公布其架构设计,为了比较Vortex核心的后端特性,我们测试了A12的指令吞吐量,其中后端的性能由其执行单元的数量决定,延迟由其设计质量决定。
Vortex核心与Monsoon核心看起来非常相似,整数除法和浮点除法的执行延迟都减少了2个周期,浮点吞吐量则是翻了一倍。
从架构的中端和后端来看,Monsoon核心是一次重要的更新。此前A10处理器的大核心代号为“Hurricane(飓风)”,其解码宽度为6,而Monsoon核心解码宽度增加至7,同时后端的整数ALU单元也从4个增加到了6个。
Monsoon核心和Vortex核心均有6个整数执行单元(包括2个复杂单元)、2个加载/存储单元、2个分支端口和3个浮点/矢量流水线,这样宽裕的后端执行单元规模远远超过三星M3和Arm即将推出的Cortex A76。
事实上,如果没有非典型的共享端口情况的话,完全可以说苹果的微架构在后端单元方面远远超过其他任何处理器架构,包括桌面CPU。
SPEC2006是一个重要的基准测试软件,它与其他测试软件的区别在于所处理的数据集更大更复杂。虽然GeekBench 4已经成为行业中的热门,但它的测试项目较小,工作负载也较轻。因此使用SPEC2006作为基准测试更有代表性,它可以充分展示微架构的更多细节,特别是在内存子系统性能方面。
性能测试在一个散热良好的环境中进行,可以保证在1~2小时内完整运行测试套件不会出现问题。
在左侧轴上,条形图表示给定工作负载下的电能消耗情况,越长的条形意味着消耗的电能越多。条形上的文字标注显示的是消耗电能的具体数值(单位为焦),以及测试期间的平均功耗(单位为瓦)。

在大多数工作负载下,A12的大核心频率比A11高5%,但实际上频率并不是锁死的,因而在SPECint2006中,A12的表现平均比A11好24%。
其中增幅最小的是456.hmmer和464.h264ref这两项测试,这也是SPECint2006套件中成为瓶颈最多的测试。由于A12架构方面似乎没有真正的重大变化,小幅增长主要归功于更高的频率以及缓存结构的改进。
而在445.gobmk测试项上A12的改进则非常大,相比A11增幅为27%。这项测试的负载特征是存储地址事件中的瓶颈以及分支错误预测。
429.mcf、471.omnetpp、473.Astar、483.xalancbmk以及部分403.gcc测试项对内存子系统很敏感,A12在这几项上取得了30%~42%不等的性能提升,显然新的缓存结构和内存子系统在这方面取得了很大的成效。
在能耗比方面,A12相比A11平均提升了12%,但需要注意的是,这里的能耗比指的是最高性能时的功耗降低了12%,而A12展示出性能相比A11提高了24%,两个SoC的性能功耗曲线已经大不相同。
不过,尽管7nm制程可以降低能耗,但在性能提升幅度最大的基准测试中,A12的功耗相比A11不降反升,平均功率从3.36瓦增加到了3.64瓦。也就是说,A12花在提升性能上的功耗,要比7nm制程降低的功耗更多一些。

接下来是SPECfp2006测试,由于XCode中没有Fortran编译器且它不是NDK的一部分,要让它在Android上工作非常复杂,因此我们选择C和C++基准测试。
SPECfp2006有更多的内存密集型测试,在7次测试中,只有444.namd、447.dealII和453.povray在内存子系统达不到标准时才会看到主要的性能回归。这对A12很有利,其在SPECfp的平均性能增幅为28%,提升最大的433.milc一项甚至提升了75%。同样的分析适用于450.soplex,优秀的缓存结构和内存性能带来了40%的性能提升。
而470.lbm是一项有趣的测试,它展示了苹果的架构与Arm和Samsung比起来有哪些性能优势。470.lbm的特点最代码中有大量循环,要求架构中有更大的指令循环缓冲区来优化这样的工作负载,在循环迭代中,核心将绕过decode阶段并从缓冲区获取指令。看起来苹果的架构恰好有某种类似的机制,也有可能是苹果处理器内核的矢量执行性能Lbm的热循环大量使用SIMD,而高达3倍的执行吞吐量优势最终产生了优秀的性能。
(雷锋网注:高通的Kryo架构由于独特的设计使骁龙820在这一项上的表现仍优于最近的安卓阵营处理器。)
与SPECint测试类似,A12在SPECfp测试中的能耗比有明显提升,在所有测试中总能量比A11低10%。另一方面A12的功耗也有所增加,平均功耗从3.65瓦上升至4.27瓦,其中433.milc项目的功耗从2.7瓦增至4.2瓦,增加了75%;482.sphinx3项目的功耗则达到了A12所有SPEC测试项中的最大值5.35瓦。
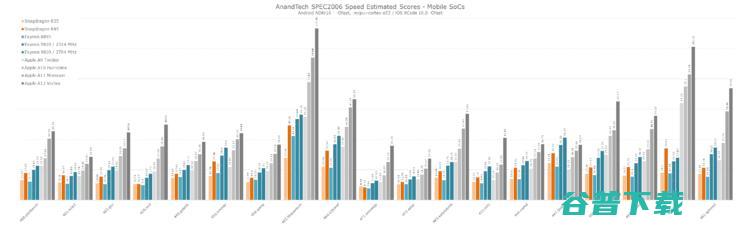
总体而言,苹果在Vortex核心和内存子系统方面的改进,使A12的实际性能比宣传中的还要强。与目前最强的安卓阵营SoC相比,A12无论在性能上还是在能耗比上都有将近2倍的压倒性优势,而如果是在正常使用条件下A12的优势可能还会更大。
这也让我们对今年发布的三星M3 架构有了更好的认知,即只有当功耗在可控范围内时,更高的功耗才能带来更高的性能(Exynos 9810的功耗是苹果上代A11的2倍,但其性能却只有A11的一半)。

GPU的性能提升是此次A12的最大亮点之一,通过 “简单的”将GPU从3核扩充为4核,以及引入显存压缩技术,苹果表示A12的GPU性能相比A11提升了50%。
在进入基准测试之前必须要知道的是,在最近两三年里,苹果开始注重注重峰值性能而忽视长时间运行时的稳定性能,使用中常常出现过热降频导致性能下降。因此苹果最新GPU的峰值性能和峰值功耗是一个必须关注的大问题。
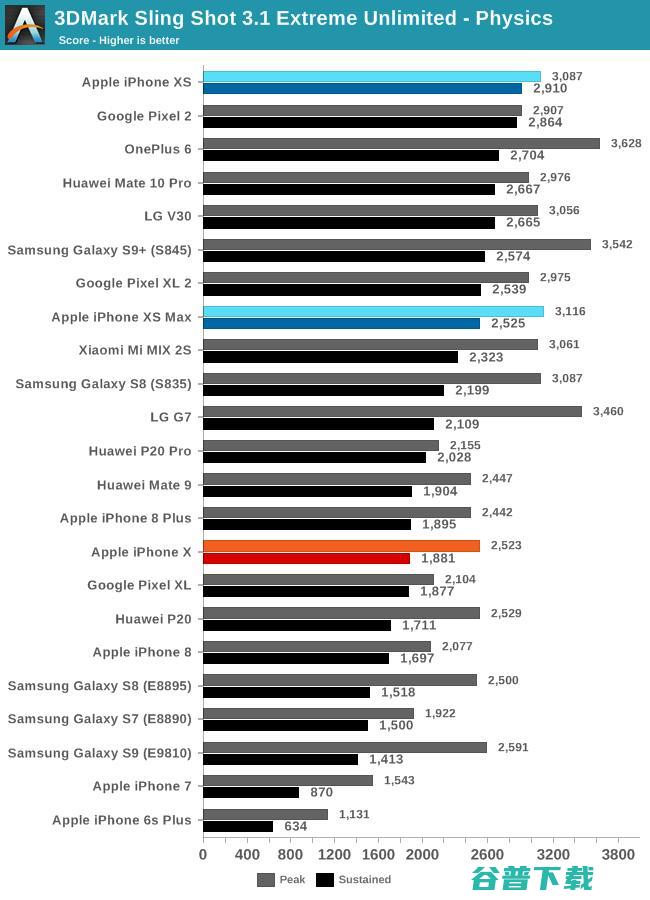
在3DMark物理测试中,iPhone XS和A12相比去年的iPhone X取得了很大的进步。3DMark物理测试此前一直对苹果的处理器不够友好,这个境遇在A11上才得到了一定的缓解。A12整体上再次提高了SoC的性能和能耗比,最终在本次测试中胜过了骁龙845。
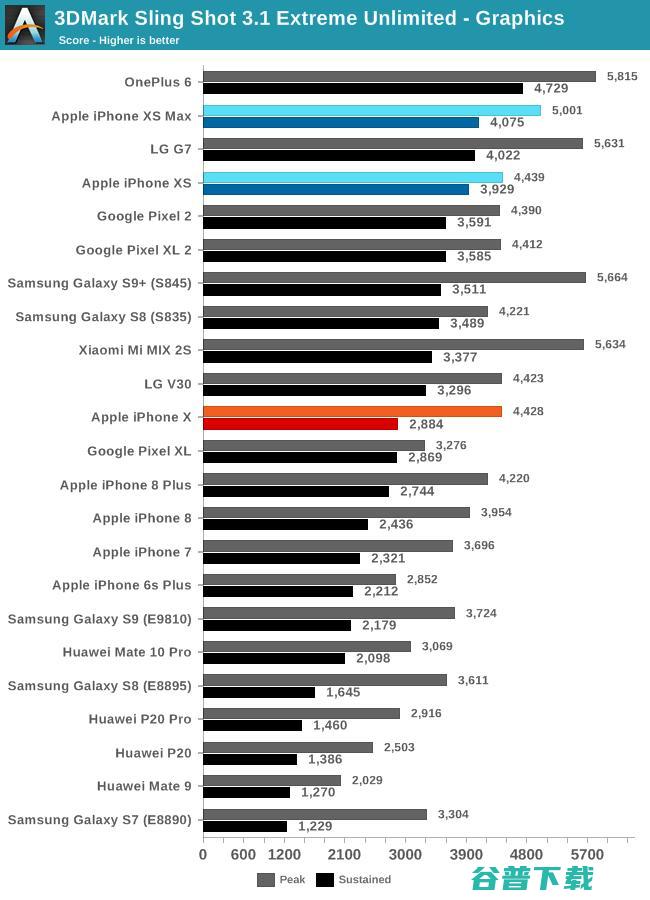
在3DMark测试的图形部分,iPhone XS的持续性能比去年的iPhone X提高了41%,不过一加6更加奔放的功耗和温度限制让其性能仍然更胜一筹。
不过就性能峰值而言,iPhone XS在3DMark测试中遇到了大问题,如果测试时手机的温度比较低,就会很快在测试中崩溃。监控显示在低温时处理器的频率很高,平台瞬时峰值功耗可达约7.5瓦,系统无法提供足够的瞬态电流,会引起电压下降,甚至损坏GPU。
除了3DMARK之外,Kishonti的GFXBench多年来一直是行业标准,新的Aztec测试给我们带来了不同的工作量。不久前Kishonti发布了GFXBench的5.0版本,这个版本建立在新的渲染引擎上运行,并引入了High Tier和Normal Tier模式下的全新测试场景Aztec Ruins。新的测试更加考验着色性能,利用更复杂的效果来强调GPU的算术能力。
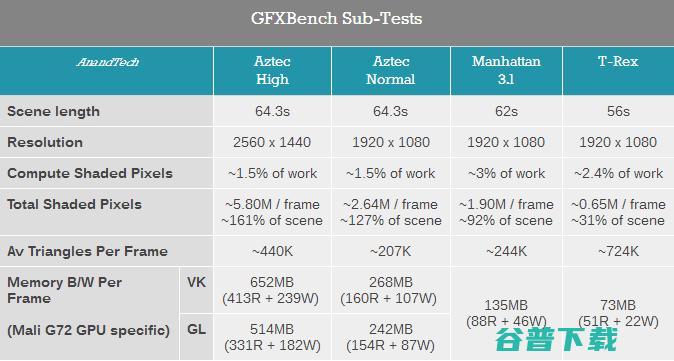
Normal Tier模式下的Aztec Ruins测试要求相对较低,iPhone XS的峰值性能相较于去年的iPhone X提升了51%,持续性能则提升了61%,相比一加6则提升了45%。而在High Tier模式下,iPhone XS的持续性能比iPhone X高出61%,比一加6则高出31%。
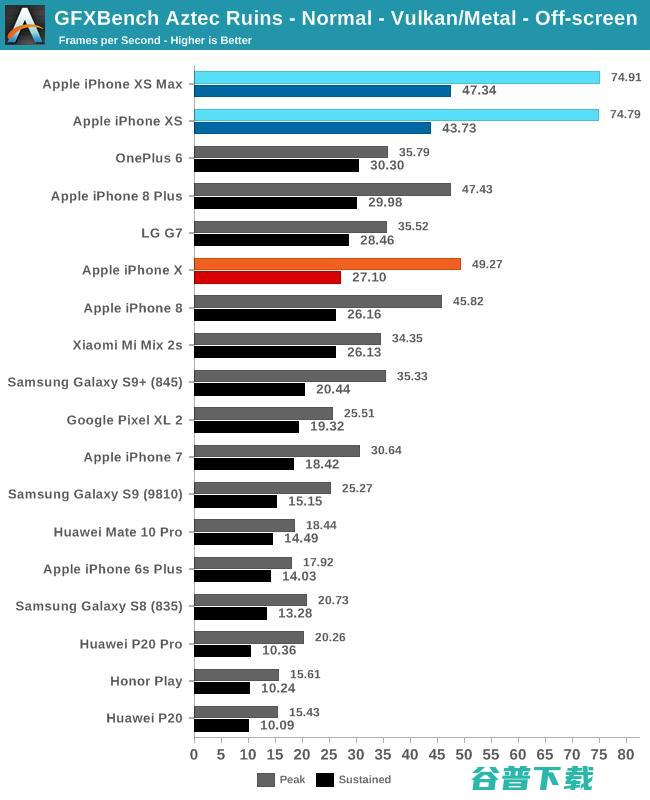

功耗方面,由于没有时间在各种设备上测量Aztec,所以仍然依赖标准的曼哈顿3.1和T-Rex测试数据。

在曼哈顿3.1中, iPhone XS的性能比iPhone X高出75%。这里的改进不仅要归功于增加的核心,还有显存压缩技术降低RAM功耗的功劳。

在环境温度22°C时,A12测试曼哈顿3.1时的峰值功耗达到6瓦。但即使在这样的峰值功耗下,A12的效率也超过了所有其他SoC,说明苹果对功耗的控制是非常有效的。在运行测试3分钟后功率回落至合理的3.79瓦,而此时处理器的能耗比仅相较峰值功耗时提升了16%, 证明A12的能耗比曲线非常平坦,6瓦的峰值功耗仍在芯片本身的可控范围之内 ,足见苹果在芯片设计上的功力之强大。

在T-Rex测试中,iPhone XS的持续性能相比iPhone X提升了61%,而功耗与曼哈顿3.1测试时表现相似,峰值功耗略高于6瓦,数分钟后降至4W以下,能耗比同样提升不大。

那么为什么近两三年的苹果处理器在峰值性能和持续性能之间存在如此大的差异呢?实际上这种变化是由于日常GPU应用场景的变化,以及苹果将GPU用于非3D相关应用的加速需求。
苹果对API栈的垂直集成和严格控制意味着GPU加速成为现实,而峰值性能是一个重要指标。苹果大量将GPU用于各种其他用途,例如在应用程序中使用GPU进行相机图像处理的硬件加速。这些应用场景均为事务性工作负载,需要较高的峰值性能以尽快处理完成。
相比之下,过去几年里Android在GPU计算方面一直是一场灾难,这主要怪没有在AOSP中支持OpenCL——这使得供应商对OpenCL的支持非常不完善。RenderScript由于无法保证性能而从未获得太多的关注,Android设备和SoC的碎片化意味着在第三方应用程序基本上无法使用GPU计算。
得益于新的A12处理器,iPhone XS和XS Max展示了业界领先的性能和效率,并且目前是最佳的游戏移动平台。不过苹果还是应该在手机的热量分布上做一些功课,iPhone XS一如上代iPhone X一样热量分布过于集中,非常影响使用体验。
版权文章,未经授权禁止转载。详情见 转载须知 。


【中公优就业-国内知名IT培训机构】提供实战IT培训课程,含JAVA培训、Python培训、大数据培训、UI设计培训、Web前端培训班、Linux培训、游戏开发培训机构、软件测试培训、营销、网络安全培训等,是IT培训优选。

巨达人才-巨达招聘云平台

浙江国鸿新瑞房地产集团有限公司,创立于温州,总部位于温州市,集团成立至今,累计投资全国30余城共计80余个项目,累计总货值超200亿元,以多个优秀住宅、商业及产业新城项目享誉浙江房产界,成为近十万家庭的倾心之选。目前集团已形成“深耕浙江,立足华东,重点布局长三角黄金城市”的战略布局,为以更高的起点,进军全国地产百强而澎湃前行。

重庆正鼎司法鉴定所是由重庆市司法局批准的独立司法鉴定机构(许可证代码:34500000075673875Y),获得国家认证认可监督管理委员会(CNCA)、中国合格评定国家认可委员会(CNAS)认可和实验室认可证书,是国家级资质认定认可的司法鉴定机构!

python学习网为广大python程序员提供python编程、python爬虫、python算法、python数据分析、机器学习、python自动化等技术文章,python学习网欢迎您

常春藤建工集团有限公司

H+是一个完全响应式,基于Bootstrap3最新版本开发的扁平化主题,她采用了主流的左右两栏式布局,使用了Html5+CSS3等现代技术

方舟志云是优质的代办公司服务商.为北京,上海,广州等全国中小企业提供增值电信业务经营许可证办理,ICP许可证,edi许可证,idc许可证,isp许可证,网络文化经营许可证办理,代理记账等企业资质代办

秒处理,免费文章降重软件,是目前最好用的文章修改神器,使用后有效降低文章重复率,让文章改重和降低文章查重率变得更快速更智能,是人工降重,软件降重,降重软件,文章降重,维普降重,万方降重,大雅降重,文章降重,文章修改,机器降重,文章改重,人工降重,文章检测,文章查重,降重软件,降重神器,降重助手。

九五网络科技

汽车租赁,二手车,海庆二手车,夏津县二手车


如何写好软文,我后面将从素材的累积、题目的甄选、文章的措辞、内容的描写等多个角度来详细的阐述,网上很多软文,让人眼花缭乱,但看完却不知所云,这让我深刻体会到一点,千万别跑题,我原来没有计划谈起这一点,因为这个是常识,我觉得没有必要说,但是看了很多的案例之后,彻底地改变了我的想法,这个,一定要提前说,下笔千言不算少,离开主题半字多,软文...。
在北美,艺术教育更多关注孩子如何理解生活中遇见的各种图像,学会用多样的艺术语言表达自己,这就是视觉艺术美术教育的概念,橡皮虫少儿国际美校在此理念的基础上结合了加拿大英属哥伦比亚省的美术教育观点,崇尚自然、释放天性,走进生活、体验学习,感受无处不在的多感官,多样化的艺术,注重气质培养与审美情趣,让孩子拥有认知世界的,美力,橡皮虫少儿国...。

7月30日,成立不到一年的百图生科,BioMap,宣布完成上亿美元的A轮融资,这家由李彦宏牵头发起并亲任董事长、原百度风投CEO刘维作为联合创始人兼CEO掌舵的,中国首家生物计算驱动的生命科学平台公司,向外界放出雄心,公司致力于用高性能生物计算和多组学数据技术加速创新药物和早筛早诊等精准生命科学产品的研发,力图让更多疾病可预警、可控制...。

据路透社报道,IBM计划在新加坡与当地政府合作建立一个区块链技术创新中心,后者正竭力想要成为亚洲的主要金融科技,fintech,中心,接下来,IBM将会和新加坡主要的经济规划机构——新加坡经济发展署,EDB,以及新加坡金融管理局,MAS,一起,推进金融和交易中的区块链技术应用和发展,路透指出,其中一个和新加坡国际港务集团,PSA,的项...。

dkngo大神级投影控发表于2023,07,24避免伤害眼睛的方法,1.保持足够的距离,不要过度靠近屏幕或投影仪,2.减少屏幕使用时间,最好每1,2小时休息10,15分钟,3.调整屏幕亮度和对比度,使其适合当前环境,4.调整字体大小和颜色,减少对眼睛的压力,5.使用特制的护眼滤镜或遮光罩,投影仪上网课操作步骤,1.将投影仪放置在稳固的...。

武汉化工学院已更名,如今的正式名称是武汉工程大学,这所历史悠久的学校成立于1972年,起初名为湖北化工石油学院,后来经过多次变革,1980年改称武汉化工学院,由化工部主管,1998年归属湖北省人民政府管理,成为央地共建的高校,2006年,学校再次更名为武汉工程大学,如今它不仅是湖北省的重点建设高校,也是国内一流学科建设高校,参与了卓越...。

黄海大柴神至尊版的底盘和三菱越野车底盘一样,黄海大柴神至尊版的底盘是在黄海汽车60年底盘制作阅历的基础上开发的,是国际首款运行越野车底盘的皮卡车,融入了三菱底盘技术,这使得它的底盘具备重载不易变形、牢靠性好等好处,驳回了140X60mm的纵梁厚度,远高于普通车型,使得底盘愈加坚挺,黄海大柴神皮卡车汽油油耗13.14L每100km,黄海...。

赛车游戏哪个最好玩,在赛车游戏大全外面,一切的玩家都是能够去找到自己喜欢的赛车游戏类型,这些赛车游戏都是十分抚慰精彩的,能够失掉更多好玩的赛车游戏内容的应战,当天就为各位玩家带来了2023好玩的赛车游戏介绍,想要尝试赛车游戏的小同伴连忙来看看!登山赛车马里奥赛车8登山赛车2收费赛车游戏哪个最好玩1、登山赛车介绍理由,登山赛车手游是一款...。

爱丽舍是西风雪铁龙旗下除了富康之外销量最好的车型了,但随着车型的老化和竞争对手的增多,爱丽舍到了该换代的时刻了,在第158期,车辆消费企业及产品,通告上有三款新爱丽舍产品型号,区分是DC7163AT、DC7163NT、DC7163DT,可以确定的是,新爱丽舍将会在4月份上市开售,笔者第一眼见到新爱丽舍的图片,心里凉了很多,或者是之前对...。

韩剧tv苹果版是一款为喜欢韩剧的朋友们打造的苹果韩剧播放器,在这里汇集各大韩剧网最新最火爆的韩剧,内容丰富,资源覆盖范围广,是您追剧必备播放器,而且每天都会同步最新的韩国影视剧,还有综艺节目也是可以观看的。韩剧tvios版介绍新鲜热门韩剧大全,看韩剧必

悟空分身PC版是专为电脑打造的一款非常专业的软件多开工具,该工具功能强大,有了它,我们就可以实现微信、支付宝、游戏、办公等应用的多开

微信公众平台是xx公司在微信的基础上新增的功能模块,通过这一平台,个人和企业都可以打造一个微信的公众号,可以*发文字、图片、语音、视频、图文消息五个类别的内容。目前微信公众平台支持PC端网页、移动互联网客户端登录,并可以绑定**进行*发信息

外界提起即构科技时,往往会打上,技术宅,理工男,的标签,与即构科技CEO林友尧交谈时,你会很快意识到,这股,技术宅,的浓厚气质究竟从何而来,谈起技术,他如数家珍,项目的细节小到一处参数,毫秒级的突破如何诞生,全都娓娓道来,联合创始人蒋宁波告诉我们,,yy,林友尧,是很爱学习的人,新事物、新技术他都要亲自研究,即构早期对接了不少直播...。
下周苹果即将召开发布会了!但最令笔者期待的不是iphone16,而是苹果今年提出的AppleIntelligence的进展,这是苹果今年进军端侧AI的一大杀手锏,其实早在今年年初,国内就有一家当时还名不见经传的大模型公司率先喊出,端侧AI是未来大趋势,的口号,当时还没有太多玩家意识到端侧AI的重要性,仅仅半年后,谷歌、苹果等巨头就纷纷...。

发表在专业问答2021,10,2313,45展示机型信息,品牌型号,当贝H2系统版本,当贝OS2.0电视盒子一般是搭配电视使用的智能电视盒子,智能电视盒子内置了智能操作系统,一般通过HDMI线与电视进行连接;通过智能电视盒子可以将传统电视变成智能电视,电视盒子是什么东西电视盒子是一个小型的计算终端设备,通常搭配电视使用,只要简单的通过...。

创业是当今比较热门的话题,对于创业者来说,选择一个好的项目加盟是成功的一半,根据市场的调查,二手货名品汇是一个很有实力,而且加盟费用少的连锁品牌,现在品牌专门致力于打造黄金珠宝领域的一条龙服务,在市场上的需求量很大,在国内行业中拥有很大的竞争力,也是消费者比较相信的华金珠宝品牌,从而得到了创业者的关注,那么加盟二手货名品汇多久能回收成...。

这个不能说是几级,因为每一等级里面又分几个小等级,志愿者里也分了的,你先看看这等级排行吧,称号所需经验QQ平民0~糖果爱好者~采购学徒~熬糖工人~拌糖熟练工~甜味技术员~捏形师傅~品糖高手~造型专家~QQ糖大师~糖果志愿者~奶酪预备兵~泡泡糖战士~刨冰骑兵~棒棒糖游侠~饼干队长~果冻骑士~巧克力将军~冰淇淋勇者~QQ糖英雄~糖果镇长中...。
