经济而生的 AI Google 对话算想未来创始人 AWS 希望做 AI 为中国 赵亚雄 算力平台工程师 前 (经济济世)

ChatGPT爆火,引得全世界为之疯狂,恍惚中一夜之间,人人都在讨论ChatGPT,所有大佬和资本纷纷涌进大模型。
上一次如此热闹还是Web 3,不过相对前者是少部分人的自娱自乐,大模型则像魔法,引得全民为之着迷,短短 2 个月内 ChatGPT 就收获 1 亿用户,币圈甚至认为过去3个月内AI创造的价值,超过了虚拟货币历史上创造价值的总和。而创业者和投资人对大模型更狂热,更加充满信念感,坚信大模型的历史意义将不亚于电力的发明;而争夺大模型技术的领导地位,则像“研发核武器”。
“全球最聪明的人都在大模型创业,没人会禁受得住它的诱惑。”前极狐(GitLab)创始人陈冉这样对说。
一个资深技术极客赵亚雄博士亦是如此。2019年从工作了六年的谷歌离职后,便一直奔赴在创业前线,最初加入创业公司Pixie小试牛刀,2022年他决定回国,因为国内涌现出的创业机会深深吸引着他——中国正在发展独立自主技术体系,中国要做自己的IT技术栈,发展自己的技术生态。对他来说,脑海中有无数诱人的技术创新点子,但是在美国成熟的技术生态中,这些想法都显得过于激进。
对他这样一个在国外科技大厂经受过近十年技术训练的人来说,这是一个难能可贵的机会。从2008年到2019年的十年里,赵亚雄博士分别在Amazon、Google工作,在基础软件领域已经成为一名资深的技术极客。
懂技术有国际视野还心怀一腔热情,这是支撑他在人生的舒适期,从大厂离职出来完成自己创业梦想的基础。
2022 年 10 月回国后,赵亚雄博士获得奇绩创坛创始人 CEO 陆奇博士的天使轮投资,开始了每周工作 100 小时以上的硬核模式。他长期关注 OpenAI 及硅谷创投生态,看到在自动驾驶长期无法获得突破、AI 创业领域一片低迷的情况下,ChatGPT从 11 月底横空出世后,重新激发了全球范围内对 AI 的狂热。
“未来一定是AI的世界”,赵亚雄博士的商业猜想转移到大模型。但他的商业方案“算想未来”不直接参与做大模型,而是要做大模型和AI应用的基础设施。 未来“算想未来”要做AI的基础设施—— AI IaaS Cloud,区别于传统的云计算厂商,即一个以AI为导向的云计算厂商。
赵亚雄博士基于自己长期在Google 为 Google Brain、DeepMind 构建的大规模高性能机器学习计算平台上的经验,敏锐地意识到中国大模型的研发,受制于基础设施软件薄弱、人才稀缺、以及 GPU 芯片禁售的风险。他坚信,接下来将迎来大模型大爆发,对算力的需求随之会暴涨,“算想未来”就是要承接住大模型带来的这部分机会。
以下是与赵亚雄博士的对话,讲述了他对大模型的认知,对国内云计算、SaaS产品发展的分析以及“算想未来”的规划。
要做大模AI的基础设施
:是什么时候关注的大模型?
赵亚雄: 2018 年我们就关注到来自 OpenAI 的博客 “AI and Compute”()的一个结论:大模型的算力需求每 3.4 个月翻一番。我还在 Google 时,Google就一直保持对大规模机器学习、深度学习的投入,我这边所在的 Borg 团队一直有专门的小组支持 Google Brain、DeepMind ,负责在大规模 GPU、TPU 集群上的资源管理和调度。
我们一直关注Transfomer、GPT 的进展,但是 ChatGPT 的诞生确实完全出乎意料,的确完全超出了我们之前脑海中固化的“线性发展”的能力曲线。也从前同事了解到ChatGPT对Google的冲击,感到非常震撼。
2018 年我们尝试了 GPU Cloud 的创业方案,2020 年又尝试了 Compute Infra with AI CHIps,都没有成功。当时最大的阻力在于,大规模的 AI 算力需求仍然只是头部大厂的小众需求,市场空间有限。真正重新唤起我们对 AI 基础设施的热情,是在 3 月 27 日陆奇博士在奇绩创坛得宣讲会上,他认为大模型已经带来划时代得变革。
3月 27 号那天,陆奇博士召开了一个奇绩创坛内部成员企业的转型研讨会,主要是有关AI、大模型。我们都知道陆奇博士他对AI领域的贡献:作为AI的一名布道者,他很早就参与过 OpenAI 的早期工作,在微软也一直在做搜索及人工智能方面的技术管理,百度的“All in AI ”战略也是他制定的。
在这个研讨会上,通过陆奇博士的视角,让我从整个人类社会经济历史、社会发展以及大模型带来的机会,对大模型有了更加深刻的认识。
我们意识到 AI 基础设施软件,对中国大模型团队追赶 OpenAI 至关重要。基于我们跟 OpenAI 基础设施团队过往的交流,我们认为中国没有可以匹敌 OpenAI 的基础设施软件技术团队,这是“算想未来”的起点。
:也就是我们要做AI的云,但是现在国内公有云竞争已经是一片红海了。
赵亚雄: 传统 Cloud 市场确实是红海。但是大模型和 AI 应用的需求,完全不同于传统 Cloud 所服务的软件系统。在大模型和 AI 应用领域,大家的技术积累没有质的差别。
首先我们看到中国现在有个最大的机会,就是中国正在发展独立自主技术体系,也就是常说的国产替代,从政府到公众、以及企业都推动。如此一来,从芯片,到服务器等基础设施,再到上面的模型应用,都有机会完全独立自主。每个层面都有全新的机会。
另外,因为 AI 大模型带来的AI算力的需求,包括AI的训练和AI的应用研发,这些场景衍生出来的公有云需求,会持续快速增长。我们有一个非常有名的统计数据——OpenAI 在 2018 年写的 AI and compute 的一个blog,里面介绍了他们统计的每个时间阶段最大的深度学习模型,它训练所需要的算力总额,每3.4个月就要翻一翻。那可想而知,随着未来 AI 持续地被更多人使用,算力以及从算力衍生出来的大数据还有 AI 应用研发,对基础设施的需求会很快地超过传统的云计算。
:能具体讲讲怎么做AI、大模型的基础设施吗?
赵亚雄: 我们要做一个操作系统,或者说一个管理 AI超级计算机的基础设施软件平台。
这个操作系统将 GPU(以及其他定制化的AI芯片)的算力,充分释放给上层的 AI训练和推理,特别是大模型的训练。我们现在要做的这个 GPU 计算平台软件,实际上就是让大模型训练,可以高效地扩展到GPU集群所能允许的最大规模,提升训练过程中对硬件的使用效率,加速大模型训练的迭代速度,最终达到快速追赶 OpenAI 的目标。
通过扩大规模来提高硬件使用效率,缩短模型训练的时间周期,原来可能要两个月训练,我们现在可以三个星期完成,快速地进行模型研发、迭代,从而加速去追赶 OpenAI ,尽早达到OpenAI GPT 3.5 或者 GPT 4 的能力。
“算想未来”第一阶段关注提升分布式大模型训练的规模;第二阶段,我们会寻求国产 AI算力的硬件,即GPU和其他 AI芯片的合作,为大模型及AI应用提供最具性价比的AI推理算力,并推出算想未来自己的AI算力基础设施解决方案,来为大中型企业建立私有AI云。
“算想未来”的最终目标,是在第三阶段,集合大数据、训练、推理以及其他 AI 计算相关的基础设施能力和服务,立足中国、服务全球,成为中国领先的 AI IaaS 云服务提供商。
:上面提到超级计算机,是类似Meta的RSC()?
赵亚雄: AI 超算的这个概念,现在指的是一类专门来服务大规模机器学习和深度学习,还有其他 AI 训练的一类集群式的计算平台。我们说的超算跟你提到Meta的RSC,其它的系统还有Google TPU Pod(、Tesla Dojo ExaPod()这些都是同一类型的硬件系统。
AI超算的硬件之上还有软件层,那这个软件层我们可以把它想象成, AI超级计算机的操作系统,它最核心的是要提供一种能力:可以把底层硬件的算力资源,通过软件的 API 形式,更容易地让模型这些框架性的软件高效率地对接起来,从而让机器学习和人工智能的研究人员和 AI 应用的开发者,可以用尽量小的研发投入,来使用 AI 超级计算机下面的硬件计算能力。
:国内做AI公有云的,有百度百舸、火山引擎,我们是对标他们吗?
赵亚雄: 是的。百度百舸,是针对客户自有硬件之上的私有化部署的软件产品。“算想未来”在第二阶段推出的私有 AI 基础设施解决方案,就会包含一个与百舸类似的软件平台。而火山引擎中针对 AI 的基础设施云服务,包括网络,相关大数据产品,也是我们未来要尝试的方向。“算想未来”的优势在于,拥有来自硅谷一线大厂中核心 AI 基础设施团队,从事 AI 超算系统研发的实践经验。
另一个区别在于大家聚焦点不同,“算想未来”平台聚焦底层硬件资源的管理、优化、调度。而以上的产品专注在提供软件工具来帮助机器学习研究者、AI 应用开发者,来更快速完成机器学习模型代码和AI 应用代码的编写。换言之,“算想未来”关注的是如何将硬件资源以软件 API 的形式呈现给机器学习研究者、AI 应用开发者,让模型训练、AI 应用能更高效地使用硬件资源。
此外,我们的平台将聚焦在支持国产 GPU,目标是基于国产 GPU 构建媲美 nVidia 芯片的算力平台解决方案。以上百舸、火山引擎也支持其他非 nVidia GPU,但只是将其作为补充、并非核心。从技术独立自主这个角度看,百舸、火山引擎并没有优势。
大模型的未来
:前面提到“算想未来”是基于大模型做基础设施,提供公有云服务,那您怎么看待国内这群做大模型的人和公司?我们听到的有一种观点是,目前国内这些做大模型的企业大多都是白费力气,他们用的都是很老的算法,您为什么不直接切入做大模型,而是要做大模型的基础设施?
赵亚雄: 首先我认为这些投资和大模型团队的出现都是非常好的,对中国的AI发展有积极作用。
这一次,在人工智能方面,中国和美国的差距通过 ChatGPT 放大出来。以前官方报道的中国人工智能的水平,很多是通过专利、论文,还有毕业工程师和博士的数量等等,这种量化指标来体现。那这些量化指标有个很大的缺陷,就是没有关注AI 理论研究的实际水平,以及支持 AI 理论研究和应用软件系统的基础设施(包括硬件、软件)的能力, AI 应用实际落地的商业闭环和对 Ai 技术生态的飞轮效应。
ChatGPT让我们看到美国整个生态是有更深的“内功”,以前不过是发“大招”之前的蓄力,看上去平平常常,一爆发就震惊世界。
当然差距没有想象中那么大。相比之前各个轮次的创业热点来说,这次的热点是一个完全由技术驱动的创业热潮。上一轮技术驱动的热潮是无人车,但当时的问题是它是以美国的团队为核心,像小马智行、文远知行等,实际上都是美国的人才在美国的土地上来做这件事情,虽然接受了大量中国风投的资金,但是它整个还是美国公司。
这一次大模型的创业有一个非常好的变化,就是中国本土的人员搭上本土的资金,然后也是完全关注中国本土市场,而且完全由技术驱动。
以技术驱动的创业,最后能取得好的商业成果的概率都是很低的。这是毋庸置疑的。但是,技术驱动的创业所积累下来的技术成果,在未来都是有更大机会在新的场景下发挥价值,这跟以往的商业模式驱动的同质化创业竞争区别就在这儿。商业模式同质化竞争的失败者,他所积累的东西本身几乎没有复用价值,至多就是提供给后来者如何规避商业竞争中的同类风险。
“算想未来”的信心在于,我们能搭建一个世界一流的工程团队,拥有在硅谷头部企业研究团队中实践大模型训练的技术经验,根据我们在美国的技术经验和技术的实践成果,把这些技术能力转移到国内来做第一批早期客户。
我们最近也是跟国内的大模型团队,还有其他的历史更长的一些人工智能公司做交流。我们很明显地感觉到, 大家对基础设施方面有一些共性的技术问题,都是我们之前在 Google 还有其他的公司都已经解决过的。所以在技术解决能力上我们很有信心。
:您说我们正在跟很多大模型团队有过讨论,能透露一下接触过哪些团队吗?
赵亚雄: 所有中国过去一段时间出现的大模型团队,我们都在接触中。另外还有一些传统的 AI 应用厂商,大家耳熟能详企业,我们也在积极地做业务拓展,具体的信息在“算想未来”后期有了阶段性成果之后,肯定会公布出来。
:既然您同意国内大模型创业公司只有30+家,竞争激烈,后期活下来的也不会很多。那么,“算想未来”闯进AI的基础设施领域,市场空间有多大?
赵亚雄: 首先要明确一点,我们的AI IaaS Cloud只是从服务大模型团队做切入,实际上我们的愿景是AI 基础设施的云服务,它无论是大模型、中模型,还是小模型,甚至是边缘的,甚至是嵌入式移动端的,都会有相应的需求。我们会为所有的企业提供相应的训练、推理,还有大数据以及其他支撑性的软件服务,像 MLOPs、AI 应用框架、Serverless AI 等等这些。
目前大模型创业,是争夺大模型市场的领导地位,其中绝大多数企业都会在竞争中被淘汰,从而消失,或者只享有极小的市场份额。但是这不意味着未来只有极少数几家大模型团队。实际上在主流投资圈关注的视野之外,有很多大模型团队都在默默地自由生长着。最后的格局应该是少数几家头部,后面跟了大量长尾的大模型团队服务各个行业客户。
另一个方面,大模型训练也不是少数企业才会有的需求。因为大模型开启了 AI 经济的序幕,意味着一般意义上的 AI 模型即将被大多数消费者、软件厂商所接受。
此外,虽然大模型与传统手工编写的软件,采用了完全不同的生产方式,但大模型仍然是一种软件,仍然需要在使用过程中不断进行重新训练、微调来满足用户的具体需求,这导致需求会源源不断。
正如用户在使用开源软件,都或多或少会进行相应的定制,因此不会出现由少数几个大模型公司垄断模型训练、推理的情况。
综上,我们认为以大模型训练为开端,逐步扩大和深入的国内AI经济,将会是一个多元多维度不断发展的市场,不会是单一的,也不会是停滞的市场。
:大模型会给中国软件产业带来什么样的影响?
赵亚雄: 鉴于中国经济的独特结构,国有企业主导的、以公有制主体的经济格局,要有美国模式的 SaaS 产品出现,成本太高了。
大模型的出现意味着以 AI 为主体的软件服务,会给中国软件产业带来跳跃式发展。如同中国跳过 PC 互联网的成熟而直接进入移动互联网,中国的软件服务业也会跳过 SaaS 进入 AiaaS 阶段,这意味着绝大部分软件应用都会用AI 模型来支持其功能,也意味着更广泛的 AI 算力需求,这正是“算想未来”最关注的市场空间。
如此一来,国内的 AI 基础设施市场有机会出现一个“为中国 AI 经济而生的 AWS”,在AI云上也随之能长出如Netflix这样的现象级SaaS应用。这是“算想未来”的机会和目标。
但国内这些以大模型为核心的公司,不会成为像AWS那样的大公司。我们当然是希望王慧文这样的成功创业者,能走出一条出人意料的商业化路径,这也是我们愿意跟所有的大模型团队,一起来琢磨在更大的集群上跑更大的模型的办法,首先完成对 OpenAI 的追赶,然后大家再厮杀角逐出最强的团队,跑出最好的商业模式。
:为什么国内这批以大模型为核心的创业公司,不会成为像AWS那样的大公司?
赵亚雄: 假设这些大模型公司,打算以大模型构建公有云平台,那这意味着大模型要具有广泛的应用能力,来为其他 AI 应用团队提供一种等同于(现有公有云上的)IaaS 能力,换句话说,AI 应用团队要能够使用大模型来搭建自己的 AI 应用。
这就存在两个问题:1、大模型的泛化能力有待验证。现在仅仅依靠文本语言作为媒介的大模型,虽然表现出了类人的能力,但是难以想象这种能力如何作为基础能力,来嵌入其他应用,即商业化场景模糊。
2、大模型的技术壁垒有限。LLaMA开源之后,其能力已经接近、或部分超越 GPT3,虽然 GPT4 的能力大幅提升。但是在大厂之间,模型的能力差距在 3 年之内(以两者发布时间为对比, llama 2023年对比 GPT3 2020 年),并且这个差距是在 meta 等企业无意持续扩大模型和训练数据规模的情况下产生的。OpenAI 尚且可以凭借先发优势,保证市场主导地位,而国内公司由于均处于同一出发点,而且在技术路线上完全跟踪 OpenAI,因此并不存在一家独大的现实基础。
当然一切仍需由市场、时间给出答案。美团诞生之初,恐怕也很难以预测其能成长为 O2O 的统治者吧。
国内SaaS的机会?
:回到“算想未来”,名字是您取的吗?有什么样的含义或者寄予了怎样的意义?
赵亚雄: 一开始项目名字叫初芯,大概意思就是说 AI 的计算,但是很多人反映听上去像一个做芯片的公司,就换成了“算网”。
因为我们是一个云计算公司,这是“网”代表的含义。那“算”则是对计算需求的体现。算网加在一起,代表我们就是一个做计算的、一个云的提供商。因为在未来比较长一段时期里面,我们相信AI算力需求会成为人类所有的算力需求里面最主流的、最重要的这一部分。算网这个阶段正是要服务 AI 计算的需求。
我们觉得“算网”非常顺口,但很快因为这个名字注册不到公司和商标。团队一起头脑风暴后有了“算想未来”这个名字。
“算想未来”表达了我们对未来 AI 算力需求的愿景,算、想这两个字代表以计算为基础,通过 AI 技术服务人们的想象力、创造力。“算想未来”代表用计算将人们想象中的未来,变成现实的使命。
:以前的职业生涯对您此次创业有什么启发和帮助?
赵亚雄: 我在 Amazon Kinesis 待了 1 年不到,Google 做了快 6 年,后来以早期员工身份加入 Pixie 并被 New Relic 收购。这些年里我一直在做云基础设施、AI基础设施相关的工作,积累了很多经验。
例如,参与过Amazon一个很有名的云产品 Kinesis;2015年加入Google的Borg团队,负责 Google 内部所有服务器集群,它类似一个 K8S 的平台;2018 年之后,以我为主在Borg内部开启了一个新项目,即让 Borg 上面的应用开发者,可以更容易地开发管理他自己的业务,这个系统用到了机器学习来优化集群管理和资源调度,同时也提高了Borg 平台上的底层硬件资源的使用效率。
Borg后期的工作,主要的重点都是来支持机器学习和人工智能,就像网络层的话,我们给机器学习这些算力芯片都专门设计了高性能的网络。我也直接参与和领导了 Google 内部全球化 GPU 算力池的项目,目的是让 Brain、DeepMind 的 AI 研究者和工程师,非常容易地把机器学习训练任务跑在全球各地的数据中心里。
2019 年作为第四号员工,正式加入 Pixie初创公司,这个公司的软件工程体系是我跟创始人一起,按照 Google 的实践经验来搭建的。
具体来说,Pixie算是我第一次正式创业,它是一家硅谷初创公司,产品是面向 Kubernetes 的微服务观测平台,创新点是用 eBPF(Linux 内核中的可观测性 API)实现无侵入式的数据采集。Pixie 曾获得顶级 VC Benchmark & GV的投资,并于 2020 年 12 月被应用性能监控领域的老牌厂商,同时在纽约证券交易所上市公司 New Relic 收购。
其实,Amazon和Google的经历,除了让我在技术上得到历练和积累,更多的是对我创业精神的影响。Amazon和Google都是极具创业文化的公司,在Amazon,内部每个团队都可以作为一个小的创业公司,来定位自己的业务方向;而Google鼓励员工创业,在员工离职创业后,想要再加入Google并不需要面试,这给了员工很大的心理保障和激励。
:作为初创公司,我们怎么与百度百舸、火山引擎这些大厂的产品来竞争?
赵亚雄: 对于这个问题,我有四个观点可以回答。
第一,也是最重要的点,初创企业胜在小而精悍!初创公司整个团队凝成一股劲之后的战斗力,是很多大厂比不了的。大厂有钱有资源,也无法弥补文化和团队精神上的绵软和懈怠;毕竟人不是机器,不是老板说一句大家要拼,就能拼得起来。对此我在Pixie深有感触。这也是“算想未来”的最大的动力和信心来源。
举个例子,当遇到一个非常难的一个技术问题的时候,创业公司往往整个团队更加执着,以及整个团队的紧密合作最后得出来的解决方案,其质量远高于大厂。
这可以用“木刀”和“钢刀”来比喻大厂和初创企业,相比木头,钢铁更锋利是因为它的元素更紧密地贴合在一起,密度大。大厂更像是一个木质的机构,自然会面临组织能力涣散、退化。所以“算想未来”要解决的就是如何长期拧成一股绳,保持高战斗力,跟大厂对抗,如何能始终保持这种凝聚力,这是我们最核心、最关键要考虑的问题。
第二,我们有技术上的后发优势。怎么理解呢?从技术发展角度来看,每次出现一次巨大技术变革之后,新入局的玩家共同具有的一个优势,就是可以很容易规避之前的发展进程中的弯路和各类无效的投入。说白了就是相对于更大、更成熟的厂商,初创公司从一开始就能花小钱办大事儿。
第三,在大模型带来的 AI 计算需求之前,在所有主流平台上的AI需求都不是主流的需求,所以大家对该问题的研究都是很有限的。换句话,今天我们跟他们其实是处在同一个起跑线上。
具体到正在做的事情。我们的核心团队成员都是来自国际大厂的infra技术专家,同时我们能时常与 OpenAI、 MSR 、Google、DeepMind这些AI先进团队保持密切交流、合作,从而从各个层面了解世界前列对 AI 的趋势判断。这是国内以业务驱动的 AI 团队所不能比拟的,因为我们所了解的信息始终比他们要高一个层次。
第四,我们更多是把AI作为一种改变世界的技术手段,而不是服务某项特定业务的技术能力来看待。所以我们能看到中国的SaaS实力不足,过去中国经济发展实际上没有办法支持,如美国那么大规模的 SaaS 企业,只有AI这样的技术工具出现,我们才能以更高效的方式来实现软件服务。
最基本的逻辑是美国的 SaaS,现在都是以公有云为支撑的数据的搬运和处理,那它对数据本身的大小处理并没有实质性的变化。有了大模型之后,就可以把上TB的数据浓缩到几百G的模型里面,再加上模型还有自学习能力,实际上便可以大大降低软件服务在交付功能过程中,对数据的这个依赖程度,如此就能大大提升软件服务的效率。
这也是为什么中国的 SaaS 在国内反而发展不起来,因为市场给它的空间很有限,但对它的效率要求又非常高,又没有一个技术手段,能用更高效率来实现这些软件服务。现在有了大模型后,我们意识到在技术上用 AI 的通用手段来实现软件服务,会比传统的SaaS模式效率更高,而且是可行的。
我们把公司的名字叫做 “算想未来”,体现的就是我们用 AI + 计算来实现人们想象中的未来世界的愿景,我们对AI 价值的认知,比我们接触到的国内这些大厂或者是其他创业公司,要走在更前面。我们这个团队人员来自中国大陆、日本、美国,既有金融背景在高盛待过的投资人、硅谷大厂的技术专家、清华基础科学班毕业的人工智能专家,都是围绕在我们对 AI 经济未来的认知上的,才能把天南海北、各行业的顶尖专家聚拢起来。
最后总结一下的话,毫不夸张地说,我每天睡觉之前都反复拷问自己你问的这个问题;我们创始团队每次都会专门花时间来一起思考这个问题。头脑风暴啊、假想场景啊等等,大家的共识就是,困难很大,但是我们这个团队,就只喜欢做最具挑战性的事儿。
:我们的团队筹备情况如何?
赵亚雄: 李静是我们的COO,她之前在高盛做投后管理,我们的首席科学家和CTO,他们分别都是在日本和美国AI 研究和应用领域知名的研究机构供职,但现在不方便透露他们的具体身份。
目前我们正在加速筹备完整的团队,同时也已经开始跟很多大模型团队做业务探讨。我们已经在推进与国内知名的语言类 AI 产品供应商的合作,来推进帮他们如何提升大模型训练,即 GPU的使用效率。
总体上来说,我们是一个进展非常快的团队,因为机会很重要,我们一直是以成为中国 AI IaaS Cloud领导者的目标来快速推进。像我的话,基本上从去年 10 月份到现在,每天都是 997 的工作节奏。
:您认为未来国内SaaS会如何发展?
赵亚雄: 因为Netflix它是传统云计算上的一个杀手级应用,是伴随着 AWS 的成长逐渐长出来一个SaaS产品代表。我们希望未来在“算想未来”的平台上,也可以生长出一个能颠覆现在各类 To C 互联网企业的,一个全新的,以 AI为核心的一个消费者应用。
(如有意愿与赵亚雄博士沟通交流可加微信:15910236560)。
特约稿件,未经授权禁止转载。详情见 转载须知 。



《防务新观察》是一档战略话题栏目,从最新的新闻事件出发,以新视角、新思路对“新安全观”进行详尽的阐述和分析,秉承“新闻演播室就是新闻现场”的现代传播理念,用新闻事件在国家防务层面的广度、深度为增强全民国防意识和国家安全防务理念服务。
")
长街网07CJ.COM-肉类、水产、预制食品,酒水一级批发商云集,品种多,质量高、价格低、安全放心,省钱。冷链物流山东省全覆盖,全国大中城市可达

傲蓝筑动力建材租赁软件,建材租赁行业业务财务一体化协同管理软件。全面规范管理钢管钢材、扣件、铝模板、钢板桩、爬架脚手架等建筑周材及塔吊、施工升降机、吊篮等建筑设备的租出、丢损、租入、租转售和进销存等租赁业务管理。

中国文化管理网
官方网站")
IRCC风险管理提供世界级专业风险解决方案及风险控制服务的集团组织

海宁市玖玖包装有限公司是一家专业从事木制托盘,各类木箱,大型设备木(铁)包装,真空包装,铁框箱等的设计与制作。 我们玖玖公司自成立起,一直本着诚信!优质!快速!为服务所有客户满意的经营理念!与客户!社会共同发展,一起成长!

山西恒驰种业有限公司|架豆种子|萝卜种子|玉米种子

上海宁明软件科技有限公司成立于2006年,是一家从事软件自主研发的科技公司,致力于企业、政府、机构的管理软件的研发和服务。

昆山市英杰纺织品进出口有限公司是一家专业生产专业户外运动面料,复合面料,阻燃面料,防紫外线面料为一体的公司,您身边的功能性面料及布料专家,公司主要生产功能性面料,复合面料,TPU复合面料,阻燃面料,防紫外线面料,吸湿排汗面料,防水透气面料,箱包面料,滑雪服面料,羽绒服面料为主的企业。

法书网创办初衷,为法律需求者、法律问题疑惑者提供更加全面细致的法律知识,让您在遇到问题时学会利用法律武器维护自身权益。

懂金融是金融知识科普网站,包括贷款、信用卡、理财、保险、股票、基金等金融领域的知识内容,更多金融知识尽在懂金融。


雷锋网AI科技评论按,继ICML2018之后,同为人工智能,机器学习顶级会议的IJCAI2018也于7月16日在瑞典斯德哥尔摩开幕,本届IJCAI,InternationalJointConferenceonArtificialIntelligence,人工智能国际联合大会,是与ECAI,EuropeanConferenceonArt...。

其实对于很多餐饮行业的内部人士可以知道,开正常的餐饮店是蛮的,但是对于小吃店来说其实会更,因为它很多的费用相对来说不是很高,所以对于加盟者来说也是一个比较低的门槛,近期也是有很多人都能够看到餐饮行业这样的一个前景,所以会选择要去加盟小吃店,川魂帽牌货冒菜是个不错的选择,它的出现也是让很多加盟者看到了希望,希望经过平台可以实现自己的创业...。

发表在知麻投影仪2024,7,2317,03知麻P20是知麻最新发布的高亮品质旗舰投影仪,具体知麻P20投影仪怎么样呢,下面就分享知麻P20投影仪的详细参数配置,看看知麻P20投影仪优缺点有哪些,是否可以满足用户的日常使用需求,知麻P20投影仪怎么样,1.画质上知麻P20采用业内领先的LED脉冲光源控制技术,可极大程度的降低光耗,让光...。
转眼间博客已经整整一年没更新了,为了不要让SEO每天一贴变为多年一贴,在刚好一年的时候更新一下,今年简直是世界大乱,虽然各个事件会以怎样的方式结束还不知道,但可以肯定的是,对世界、对国家、对个人,都有方向性的巨大影响,影响大到想对世界、对人生发些感慨,都不知道从何说起了,所以还是回到seo这个小话题吧,前几天一位国内某大型电商SEO部...。

日前,苏州颁布政策落实党政机关,过紧日子,,提到高铁沿线公务出行准则上不布置公务用车和租车保证、公务应酬布置在机关食堂、公务用车改换需满十年十万公里、向社会放开停车场卫生间等规则,7月11日,苏州机关事务控制局上班人员通知红星资讯记者,这次规则是依照省机关事务控制局和市财政要求、依照苏州特点制订,局部规则有一些自我加压,不清楚为何引发...。

楼主你好,可以加装腾讯地图我很青睐,觉得很好用,性能弱小,违章查问性能收费查问车辆违章消息,及时准确推送新违章,真正零流量地图,不联网也能用允许多目标地导航,宿愿你也会青睐,这车触动特意大,高档位嗡嗡的,震的脑袋痛,再一点上坡有力,超车减速不行这车小故障多,一汽造车还得用心啊走烂路巅的凶猛,没方法面包车都一样密封性差,最近下大雨,副驾...。

不一样,手机管家普通的作用是治理软件,担任装置或许卸载软件,治理手机存储,治理手机程序运转状况,而手机卫士是为了防护手机装置,普通的配置是病毒查杀、防止流量窃取、防骚扰阻拦等配置,从配置角度来讲是齐全不同的,腾讯的手机管家和360的手机卫士哪个好些,安卓系统上,倡导装置360手机卫士就可以了,如今360手机卫士是一款齐全收费的手机安...。

澎湃资讯记者从公安部网站得知,岳修虎任公安部党委委员、反恐专员,副部长级,岳修虎,男,汉族,1973年4月生,硕士钻研生学历,中共党员,现任公安部党委委员、反恐专员,副部长级,,副总警监警衔,...。

是股份制企业陕西汽车控股个人有限公司简称陕汽控股,始建于1968年,总部位于陕西西安,现已开展成为占低空积450万平方米,领有资产总额149亿元,从业人员2.3万余人的特大型汽车企业个人,公司产品范围笼罩重型越野车、重型卡车、大中型客车,底盘,、中轻型卡车、重型车桥、康明斯发起机及汽车零部件等畛域,是国度选型对比实验后保管的惟一指定越...。

腾讯软件中心提供2023年最新10.0.9.3官方正式版雷神加速器高速下载,本正式版雷神加速器软件安全认证,免费无插件。

将.apk包后缀改为.zip进行解压 查询META-INF目录 将CERT.RSA后缀名修改为p7b打开查看公钥信息

150首胎教音乐,150首MP3格式胎教音乐打包,整理给准妈妈分享,您可以免费下载。

在众多游戏类别中,驾驶类游戏以其卓越的沉浸感脱颖而出,为了赋予玩家近乎真实的驾驶感受,这类游戏在视觉呈现与车辆设计上都力求贴近日常生活场景,接下来,我们将探索几款超真实模拟驾驶游戏手机版,小编精心挑选了七项高度模拟现实的驾驶体验,若大家对驾驶充满热情,不妨一探究竟,看看这些游戏是否能满足大家对真实性的追求,1、,遨游城市遨游中国卡车模...。

投影仪光源显示技术的论战一直是前段时间业内的焦点,各大厂商都在为自家产品技术据理力争,激烈的论战中,其实还有一项技术——ALPD激光不容忽视,要知道在去年年底,光峰最新一代的ALPD5.0激光显示技术已经正式发布,且搭载该项技术的投影仪当贝X5Ultra已经正式面世,那么究竟ALPD5.0是什么,下面小编整理了相关资料供用户快速了解,...。

苹果确认今年新iPhone将推迟数周发布苹果公司今天发布了2020财年第三财季业绩,在财报发布后的电话会中,苹果公司首席财务官卢卡·梅斯特里,LucaMaestri,表示,相较往年,今年新一代iPhone手机将推迟数周发布,财报显示,苹果公司第三财季净营收为596.85亿美元,比去年同期的538.09亿美元增长11%;净利润为112....。
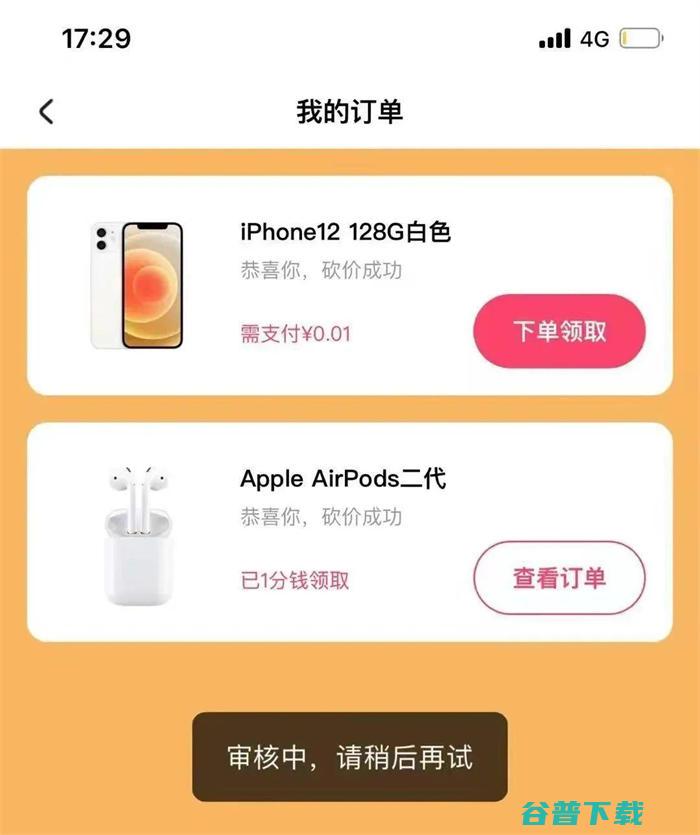
今天下午社群里面分享了一个新项目,收益是1分钱买iPhone12或者苹果耳机等其他商品,没过一会就看到有人在朋友圈卖这个项目,因为这个项目就是一个拉新活动,只能算是信息差,免费分享,避免大家被割,#活动,1.下载,快手极速版2.打开侧边栏、点击去赚钱3.找到,一分钱抢好货,,点击立即抢4.选择合适商品开始砍价说明,有的手黑,是没有iP...。

现在很多人在多年的打拼之后,就会想要自己创业,而在创业的时候,会需要技术,大量的资金,而加盟一家连锁的餐饮店面,也成为了很多人创业的选择,加盟连锁的店面,能够有较高的人气,就像在身边就会有很多连锁的美食店,并吸引了大量的顾客,一些创业者就想要加盟连锁的店面,喔喔鸡煲就赢得了创业者的关注,如果加盟开店的话,喔喔鸡煲加盟多少钱,喔喔鸡煲的...。
