华人学者再创佳绩!包揽CoRL2021最佳论文奖项 (海外华人学者)

备受关注的论文大奖全部被华人学者包揽。 来自麻省理工大学的Tao Chen, Jie Xu, Pulkit Agrawal(导师)拿下最佳论文奖;来自哥伦比亚大学的Huy Ha, 宋舒然(导师)拿下最佳系统论文奖。
本次获提名奖的共有七篇论文,四篇最佳论文奖提名,三篇最佳系统论文提名。 七篇佳作皆有华人学者参与。占比42.3%。
CoRL于11月8日——11日在伦敦举行。同时在网络上也开设了虚拟会场以飨诸位:PheedLoop主题演讲、指导性建议和论文演讲;gather.town 用于海报会议和交流。即使不能到现场的同学,也不用担心错过关注论文的演讲了。
荣获CoRL 2021最佳论文奖的是:


由于高维驱动空间以及手指与物体之间接触状态的频繁变化,手持物体重新定向一直是机器人技术中难攻克的问题。Tao Chen等人提出一个简单的框架,框架的核心是无模型强化学习: 可被称为“师生关系”的训练法、重力课程设置和物体稳定初始化。 它可以解决复杂的问题,用机械手学习重新定向,让2000多个不同物体的系统面朝上和朝下。该系统不需要物体或机械手模型、接触动力学和任何特殊的感官观察预处理。
过去的一些方法,如使用强大轨迹优化法分析模型,虽然解决了重新定向问题,但结果主要是在模拟简单的几何形状,无法拓展到现实中推广到新对象,结果差强人意。
Tao Chen他们的研究首先在模拟中对“老师” 进行有关物体和机器人信息的训练,为了确保机器人可在现实中运作,模拟中缺失的信息如指间的位置,强化学习智能体接受的知识被转化为模拟外可用的数据,像摄像机捕获的深度图像等。为了提高性能,机器人先在零重力空间里学习,再在正常的重力环境中适应调控器。看似违反直觉,但单个控制器可以重新定向大量它以前从未见过的物体。

Chen Tao, 麻省理工学院EECS & CSAIL 博士,师从Pulkit Agrawal教授。本科毕业于上海交通大学机械工程及自动化专业,期间在普渡大学机械工程学院交换。读研之前,Chen Tao曾是上海LX Robotics的研究工程师,从事目标检测、图像分割、机器人深度强化学习、SLAM等方面的研究。研究生毕业于卡内基梅隆大学机器人学院,师从Abhinav Gupta 教授。主要研究机器人学习、操作和导航的交叉领域 。

Jie Xu, 麻省理工学院CSAIL博士,师从计算设计和制造组(CDFG)的Wojciech Matusik教授。本科毕业于清华大学计算机科学与技术系。
研究主要方向机器人、仿真、机器学习的交叉领域。感兴趣的主题: 机器人控制、强化学习、基于可微分物理的仿真、机器人控制和设计协同优化、模拟现实。











版权文章,未经授权禁止转载。详情见 转载须知 。



亿方云网盘是360旗下一款专业的协同办公企业网盘(企业云盘),强大的在线文档编辑功能为企业提供文件管理、文件存储、共享文件、协同办公、移动办公等便捷服务,亿方云网盘满足企业团队协作和高效办公需求。

-交通-航空公司网址

厦门市中捷信息科技有限公司(简称中捷科技)总部位于美丽的花园城市厦门,是一家以技术为核心的互联网+综合型创投公司。目前,通过自主研发或深度定制为客户提供互联网系统以及项目运营指导,进而实现项目的创新发展,最终达成双赢。

智能小程序,智能连接人与信息、人与服务、人与万物的开放生态,依托APP为代表的全域流量,通过百度AI开放式赋能,精准连接用户,无需下载安装便可享受智慧超前的使用体验。

嘉兴市建设工程造价管理协会造价协会嘉兴造价协会

拉卡拉POS机,作为A股上市企业拉卡拉旗下的明星产品,凭借其高效、安全、便捷的支付体验,赢得了广大商户和消费者的信赖。支持多种支付方式,包括有卡支付、无卡支付和NFC支付,全面满足您的支付需求。同时,拉卡拉POS机还提供一站式服务,包括商户认证、快速到账、账目明细清晰等,让您轻松管理支付事务,提升业务效率。

张建庆个人设计师网站

成都玛时特电子科技有限公司

天生武侠,世界无羁!《燕云十六声》12.27正式公测,纪念时装、配饰免费送。游戏首次实现了“中国特色武功”与开放世界品类的融合,玩家将在充满迷题的无缝地图中,众揽天下风光,探秘海量地宫,同时偷师百家武学,身兼十八般武器,学遍太极、点穴、狮吼功、蛤蟆功等全新奇术,创造属于自己的武侠冒险。

卓创资讯坚持中立第三方立场,专业提供大宗商品行情、分析、数据以及咨询、会展等服务,专注产品领域涵盖能源、化工、农业、金属等大宗商品行业。热线电话:400-811-5599

逸群信息提供:方寸自助打印机,花生壳,内网穿透,DDNS,自助打印系统,自助打印机柜,自助打印,共享打印机,DDNS服务热线:4008600217

全科界·智慧赋能平台是一个服务广大基层医疗机构,为基层医务人员持续赋能的综合性平台。平台依托全科场景,倾心打造了以“医-教”为核心的赋能架构,通过远程教学培训、全科医生职业发展、远程医疗协作等子系统建设,结合优质的专家资源,高效精准地进行专业能力的输出,同时灵活丰富的培训教学方式,真正实现基层医务人员的“个性化”学,促进基层医务人员能力提升,落实国家分级诊疗政策,让社区群众便捷接触到优质医疗资源,增进民生福祉。


无论是做小说短剧推广类的视频、还是做好物分享,混剪都是很重要的一个去重、丰富视频内容的环节,所以就有了智能混剪软件有哪几个这个话题,因为有这类软件的帮助,视频制作者可节省大量的时间与精力,因此小编接下来献上智能混剪软件排行榜,希望能帮助到各位需要混剪视频的网友,不管你是哪个平台的视频创作者,这都是你值得下载的创作类辅助工具,因为它不仅...。
刚收到确认消息,Alexa中文网站关闭,访问Alexa中文站,cn.alexa.com,会跳转到英文主站,www.alexa.com,上,而且也得到Alexa官方的确认,这意味着运营不到2年的Alexa中文站关闭,据我观察,目前国内大部分中小网站的Alexa都开始呈下滑状态,而自卢松松博客建立以来,博客Alexa一直处于上升阶段,近期...。

古人云,爱美之心,人皆有之,当今社会,人人都追求高颜值,在日常生活中,会到皮肤管理中心做皮肤护理,正是如此,美容护肤行业很热门,不仅消费市场庞大,而且服务产品营收高,在选择创业项目的时候,有些创业者想要加盟开皮肤护理店,奇迹之光皮肤管理品牌很有名气,值得推荐,那么,奇迹之光皮肤管理的服务项目有哪些,加盟好运营吗,奇迹之光皮肤管理品牌的...。

现如今人们大部分的时间都用于工作、学习等等,没有太多的时间照顾老人和小孩,也没有多余的时间整理自己的房子,这时候经常会寻找专业的家政公司来帮忙,苏州作为一个经济比较发达的城市,一直都有着很高的吸引力,让不少的创业者想要在苏州加盟一家家政品牌,实现自己的创业梦想,在选择加盟家政的时候可以选择一些名气比较高、影响力大的品牌,这样能够减少自...。

AI时代一个值得关注的新变化是科技巨头们都纷纷开始自主研发AI芯片,一方面可能是因为科技巨头们积累了大量数据价值待挖掘,另一方面是目前的芯片算力不足且十分昂贵,美国作为传统的科技强国,FANG中的谷歌正在领跑,中国互联网巨头也大力发展AI,其中阿里的AI芯片进展最受关注,那么,BTA能否在AI芯片领域挑战FANG,中国有BAT,百度、...。

第七届GAIR全球人工智能与机器人大会,于8月14日,15日在新加坡乌节大酒店举办,论坛由GAIR研究院、、世界科技出版社、科特勒咨询集团联合主办,这是国内首个出海的AI顶级论坛,也是中国人工智能影响力的一次跨境溢出,GAIR创立于2016年,由鹏城实验室主任高文院士、香港中文大学,深圳,校长徐扬生院士、GAIR研究院创始人朱晓...。

直资讯陈先生,中国外长王毅和俄罗斯安保会议秘书绍伊古独特掌管了新一轮策略安保商量,为何惹起环球各方关注,特约评论员陈冰美国大选结果揭晓后,特朗普就像地震波,惹起环球各地包括美国盟友的担忧、焦虑,在这种背景下,中俄新一轮策略安保商量,仿佛又让躁动的环球安静上去,发现这环球是多极的,并非美国一极,特朗普是美国的总统,而不是环球的总统,这就...。

据知情人士泄漏,外地期间7月3日,拜登与其竞选团队上班人员通话,通知他们他,哪儿也不会去,而在拜登的竞选团队收回的一份电子邮件中,拜登称,,没有人排挤我,我不会走的,我将在这场竞选中保持究竟,他还向其允许者继续募款,以助其在往年11月5日的大选中击败特朗普,外地期间7月3日黄昏,拜登还与24位独裁党籍州长和华盛顿特区市长举办面对面...。

2024年高考时期,一则,迈巴赫送考,的视频引发了网友的热议,这名高三考生是中国工艺美术巨匠、国度级非遗铜雕技能代表性传承人朱炳仁的孙子朱也天,6月25日,该少年的高考效果出炉了,总分达700分,值得一提的是,朱也天还是奥林匹克化学金奖得主,朱也天接受记者采访时沉稳而虚心,他说,我如今确实挺激动的,,但700分,也不是很高的分数,我...。
网络输入法下载,extended=true>,网络输入法下载,extended=true>,网络拼音输入法,简称网络输入法、网络拼音,是搜狐公司推出的一款汉字拼音输入法软件,是目前国际干流的拼音输入法之一,号称是以后网上最盛行、用户好评率最高、配置最弱小的拼音输入法,网络输入法与传统输入法不同的是,驳回了搜查引擎技术,是第...。

文博日历丨“浙”幅会动的《富春山居图》,细节拉满!,沈周,董源,文博,黄公望,山水画,警匪片,动作片,犯罪片,电影导演,书法作品,天机:富春山居图

译名忍者神龟变种大乱斗忍者龟变异危机港忍者龟变种大乱斗台新忍者神龟忍者神龟重启版片名年代产地美国类别喜剧动作科幻动画奇幻冒险语言英语字幕中文上映日期中国大陆美国评分豆瓣评分片长分钟导演杰夫罗韦凯勒斯皮尔斯编剧塞斯罗根埃文戈德堡杰夫罗韦丹埃尔南德斯本吉萨米特布兰登奥布莱恩彼得拉尔德凯文伊斯特曼演员尼古拉斯坎图布雷迪诺恩小...

刚跟一个朋友聊天,她是大公司高管,过完年不出意外还会继续升职,年会上老板差不多算表态了,她跟我吐槽,身边几个平时关系好的平级马上态度就不一样了,虽然已经尽力克制,但是还是免不了要酸一酸,一个说,以后你就是我领导了,可得照顾照顾我呀,需要过年给你送礼不?一个说,怎么偷偷努力啊,闷声不响的就升职,真看不出啊,这些话都藏在玩笑下面,表面上看...。

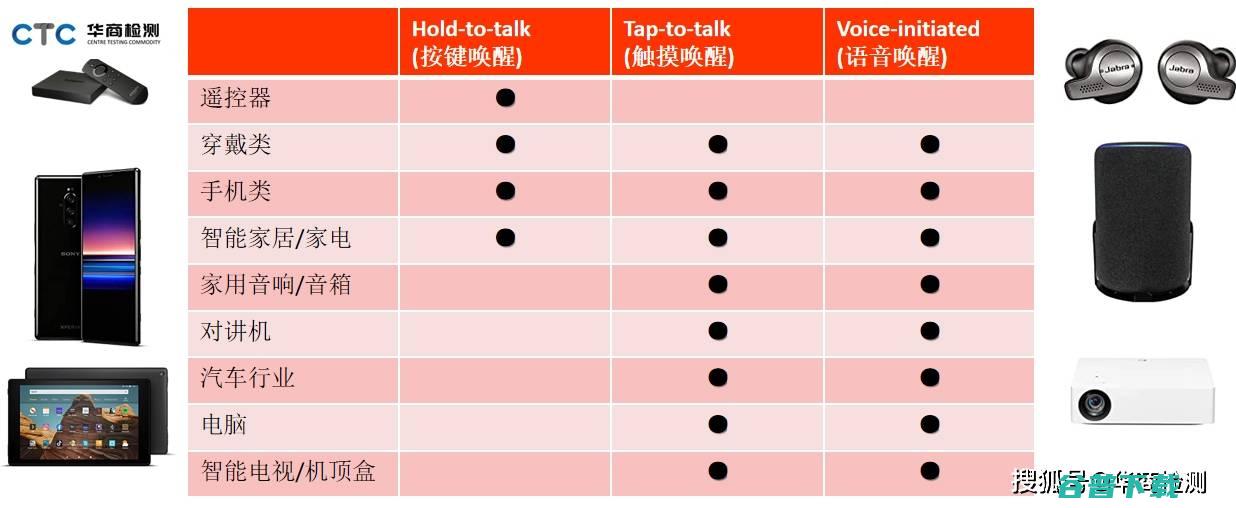
文,丁丁停车CEO申奥在给题目中的智能硬件打标签的时候,除了,共享经济,,本来我还想打一个,O2O,的标签,但最近O2O着实被黑出了翔,并且自己思考了一下似乎共享经济基本都是O2O的玩法,那么就弃掉了这个鸡肋标签,重点来谈共享经济下的智能硬件玩起来有什么不同,我是芯片体系架构的专业出身,最近尘埃落定的Intel收购Altera的两家主...。

清吧,不同于传统喧哗热闹,灯光闪烁的酒吧,清吧以播放轻音乐为主,比较安静,没有热舞女郎,比较适合个人放松休憩,或者和朋友谈天说地,是娱乐休闲的好去处,一些精明的创业者纷纷打算开店,那么,到底开一个小型清吧怎么样呢,不妨看看下面的分析,在这个快节奏时代,年轻人普遍承受着较大的压力,平时解压放松的办法不乏喝喝酒,和朋友聊聊天,传统酒吧太过...。

文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为起点社交广告营销专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在起点社交广告营销网站首页底部或友...。

上汽公众24小时售后客服电话是,上汽公众人工客服电话号码是,这个是上汽公众的官网电话,可提供24小时服务,且全年无休,上汽公众简介上汽公众汽车有限公司是由上汽个人和公众汽车个人合资运营,双方各占50%的股份,是国际历史最悠久的汽车合资企业之一,上汽公众原名叫上海公众,成立于1984年,公司总部位于上海西北郊安亭国际汽车城,并先后在南京...。
