效率提高1000倍 Deepmind语音生成模型WaveNet正式商用 (效率提高10%)
雷锋网消息:2017年10月4日,Deepmind发表博客称,其一年前提出的生成原始音频波形的深层神经网络模型WaveNet已正式商用于Google Assistant中,该模型比起一年前的原始模型效率提高1000倍,且能比目前的方案更好地模拟自然语音。
以下为Deepmind博客所宣布的详细信息,雷锋网摘编如下
一年之前,我们提出了一种用于生成原始音频波形的深层神经网络模型WaveNet,可以产生比目前技术更好和更逼真的语音。当时,这个模型是一个原型,如果用在消费级产品中的计算量就太大了。
在过去12个月中,我们一直在努力大幅度提高这一模型的速度和质量,而今天,我们自豪地宣布,WaveNet的更新版本已被集成到Google Assistant中,用于生成各平台上的所有英语和日语语音。
新的WaveNet模型可以为Google Assistant提供一系列更自然的声音。
为了理解WaveNet如何提升语音生成,我们需要先了解当前文本到语音(Text-to-Speech,
TTS)或语音合成系统的工作原理。
目前的主流做法是基于所谓的拼接TTS,它使用由单个配音演员的高质量录音大数据库,通常有数个小时的数据。这些录音被分割成小块,然后可以将其进行组合以形成完整的话语。然而,这一做法可能导致声音在连接时不自然,并且也难以修改,因为每当需要一整套的改变(例如新的情绪或语调)时需要用到全新的数据库。
另一方案是使用参数TTS,该方案不需要利用诸如语法、嘴型移动的规则和参数来指导计算机生成语音并进行语音拼接。这种方法即便宜又快捷,但这种方法生成的语音不是那么自然。
WaveNet采取完全不同的方法。在原始论文中,我们描述了一个深层的生成模型,可以以每秒处理16000个样本、每次处理一个样本党的方式构建单个波形,实现各个声音之间的无缝转换。

WaveNet使用卷积神经网络构建,在大量语音样本数据集上进行了训练。在训练阶段,网络确定了语音的底层结构,比如哪些音调相互依存,什么样的波形是真实的以及哪些波形是不自然的。训练好的网络每次合成一个样本,每个生成的样本都考虑前一个样本的属性,所产生的声音包含自然语调和如嘴唇形态等参数。它的“口音”取决于它接受训练时的声音口音,而且可以从混合数据集中创建任何独特声音。与TTS系统一样,WaveNet使用文本输入来告诉它应该产生哪些字以响应查询。
原始模型以建立高保真声音为目的,需要大量的计算。这意味着WaveNet在理论上可以做到完美模拟,但难以用于现实商用。在过去12个月里,我们团队一直在努力开发一种能够更快地生成声波的新模型。该模型适合大规模部署,并且是第一个在Google最新的TPU云基础设施上应用的产品。

(新的模型一秒钟能生成20秒的音频信号,比原始方法快1000倍)
WaveNet团队目前正在准备一份能详细介绍新模型背后研究的论文,但我们认为,结果自己会说话。改进版的WaveNet模型仍然生成原始波形,但速度比原始模型快1000倍,每创建一秒钟的语音只需要50毫秒。该模型不仅仅速度更快,而且保真度更高,每秒可以产生24,000个采样波形,同时我们还将每个样本的分辨率从8bit增加到16bit,与光盘中使用的分辨率相同。
这些改进使得新模型在人类听众的测试中显得发声更为自然。新的模型生成的第一组美式英语语音得到的平均意见得分(MOS)为4.347(满分5分),而真实人类语音的评分只有4.667。
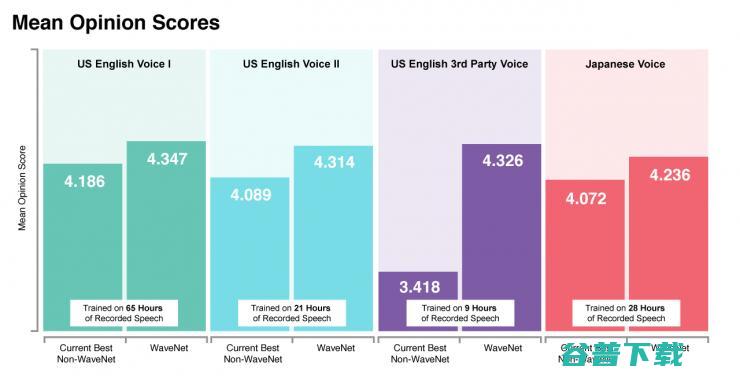
新模式还保留了原始WaveNet的灵活性,使我们能够在训练阶段更好地利用大量数据。具体来说,我们可以使用来自多个语音的数据来训练网络。这可以用于生成高质量和具有细节层次的声音,即使在所需输出语音中几乎没有训练数据可用。
我们相信对于WaveNet来说这只是个开始。我们为所有世界语言的语音界面所能展开的无限可能而兴奋不已。
原创文章,未经授权禁止转载。详情见 转载须知 。



中国教师研修网由全国教师教育学会主办,在教育部十五规划重点课题“基于现代信息技术环境下的校本研修的理论与实践”的探索中应运而生,为全国中小学教师搭建研训一体的专业发展平台,实现教师个人、学校、区域教学组织的知识管理,创建全员参与、团队合作、资源共建、可持续发展的网上学习共同体,与各地合作伙伴一起搭建多个区域级教师网上学习社区。

濮阳医院检查男科哪家比较好,濮阳正规的男科医院是哪家,濮阳濮阳可靠的医院男科,濮阳男科医院排行榜,濮阳华龙区男科医院,濮阳东方男科医院咨询,濮阳男科医院东方温馨,濮阳东方医院男科可靠

合肥乐维信息技术有限公司,火车采集器,使用人数最多的网站采集软件,站长必备采集利器。火车浏览器,可视化采集,万能群发。

储罐厂家鑫盛源主产各类储罐,储罐规格型号齐全,鑫盛源也是不锈钢储罐厂家,二手不锈钢储罐交易,主推全自动发酵罐,动物油熬炼设备,不锈钢储油罐等欢迎订购

力翰威自动化设备为您提多种托盘清洗机的产品信息、电话报价、厂家信息、厂家资质等信息,您在这里可以找到全面的托盘清洗机设备型号,以及厂家设备定制服务等。

重庆金玫瑰婚恋是重庆专业的正规靠谱婚介所,高端白领、单身青年、本硕博网上婚恋相亲首选,免费线下同城相亲活动助你大胆去爱,高端婚恋就到金玫瑰交友平台.

广东昌福半导体有限公司是一家从事半导体分立器件研发生产,销售和技术服务的专业制造商,工厂位于经贸发达的江苏连云港,我公司主要销售经营晶粒式、桥式整流器、硅整流二极管、快恢复二极管、肖特基二极管、避雷二极管、TVS管、贴片二极管、管芯及系列产品。

流量如何变现,推啊网-互动式效果广告投放平台,开创互动广告全新形式,日均曝光50亿+,覆盖12亿+在线移动APP用户,兼顾媒体收益、用户体验及广告转化,实现媒体主、广告主、用户多方共赢。

公司注册、公司变更、代理记账、财务咨询、知识产权润锡咨询

Zhtv应用安卓市场官网为安卓手机用户提供最新最全的安卓软件、安卓游戏下载资源,让安卓手机应用、安卓手机游戏丰富多彩,zhtv应用汇是安卓网上最贴心的Android软件应用商店。

南京正武雕塑艺术有限公司是以规划、设计、制作、安装、维护于一体的雕塑文化企业。南京正武雕塑艺术有限公司由专业设计团队和制作团队组成,常年聘请国内知名的雕塑家莅临指导合作.;

弘达手游网为您提供丰富的手机游戏下载资源,涵盖安卓软件、手游排行榜及应用市场。无论您寻找最新的游戏还是经典应用,我们都能满足您的需求。快速、安全的下载体验,让您的手机游戏生活更精彩!


从来没有哪家互联网公司像百度一样,同时身负盛名与骂名,它在中国互联网江湖搏杀二十年,见证了无数的一夜成名,也见证了将军迟暮,美人白首,尽管市值已经不足阿里或腾讯的十分之一,但仍在流传的,BAT,称谓证明了它还有那么一些江湖地位,然而,反过来看,无论在哪个中文互联网社区,,骂百度,似乎成为一种政治正确,,百度有难,八方点赞,百度是什么...。

产后妈妈们对自己的健康一直都非常关注,因此为了快速的恢复到产前的状态,经常会选择到专业的母婴护理中心中调理身体,在市场中随处可以看到不同的母婴护理中心的身影,为消费者们提供了广泛的选择,也为创业者们带来了商机,纤思韵母婴护理中心是一家发源于北京的品牌,自2012年在市场中成立以来,已经在市场中发展了十一年的时间,成为了加盟商眼中的香饽...。
2021年12月11日,由&,AI掘金志主办的第四届中国人工智能安防峰会,在深圳正式召开,本届峰会以,数字城市的时代突围,为主题,会上代表城市AIoT的14家标杆企业,为现场和线上观众,分享迎接数字城市的经营理念与技术应用方法论,在下午场的演讲环节上,灼识咨询合伙人赵晓马为峰会带来了精彩演讲赵晓马指出,从中国、美国、日本城...。

发表在综合交流大区2018,11,1515,59导读,随着时代的发展观影方式的进步,投影仪应运而生,取代电视在家庭中的地位成为观影的主流,消费者在购买投影仪的同时都会查看投影仪的一些参数,但是这些参数对于对投影仪一知半解的消费者来说很难理解的,为了让消费者在购买投影仪时对这款投影仪参数了解的更清楚一点,小编今天写一篇关于,投影仪参数的...。

不少人都会感觉,星盘测进去的消息十分精准,而后在困惑迷茫的时刻会给自己以启发,等预先回头想想会发现,真的准的可怕,星盘为什么准得可怕,咱们一同来看看吧,星盘是什么,星盘,是现代的天文学家和占星师还有航海家罕用的物品,是一种用来测量天文的天文仪器,测量结果十分精准,用途十分宽泛,可以定位和预测不同天体在宇宙里的位置,还可以确定本地期间以...。

圆压平型凸版印刷机,印刷时,圆型的压印滚筒敌对面的印版相接触,印刷速度比平压平的印刷机快,无利于启动大幅面印刷,依照压印滚筒的静止方式,圆压平凸版印刷机又分为一回转和二圆转两种,1.一回转凸版印刷机压印滚筒每旋转一周,版台则往复静止一次性,实现一个上班行程,这种机器当印刷用纸尺寸相反时,其压印滚筒的直径比其它类型的印刷机大得多,这样版...。

沃尔沃s40作为一款小型奢侈轿车,曾是沃尔沃公司的明星产品之一,它于1995年终次颁布,不时消费到2012年,时期共推出三代车型,关于如今想要购置二手车的人来说,选用一辆沃尔沃s40二手车是十分划算的,好处作为一款奢侈车型,沃尔沃s40有着许多杰出的特点,首先就是其温馨性,其座椅温馨度高,而且同时还具有撑持性,其次,沃尔沃s40具有很...。

7月2日,华商报微风资讯报道了,休庭后女律师眼见助理被围堵,拍照取证遭法警粗犷看待倒地,一事,休庭后女律师拍照取证遭法警争夺手机后被推倒,法院上班人员,倡导关注法院后续通报7月3日下午6时30分,华商报微风资讯记者从何智娟律师助理赵某处得知,在被贵阳云岩区法院法警争夺手机近30个小时后,法院被动咨询何智娟律师团队,称关系担任人宿愿何智...。

当天,外交部发言人毛宁掌管例行记者会,有记者就17岁中国羽毛球静止员张志杰在印度尼西亚参与较量后逝世提问,毛宁示意,咱们也据说了这一可怜的信息,得知这个事情的出现之后,中国驻泗水总领馆立刻咨询和协调了印尼方面全力救治,并且派员赶赴事发地展开上班,咱们对当事人可怜离世深表惋惜和哀悼,向他的家人示意慰劳,外交部将继续指点驻泗水总领馆,在职...。

惜亩惜仔是什么意思?最近肯定有很多小伙伴在网上见过这个梗,但是肯定有些不知道这个梗的小伙伴看到后一头雾水,完全不知道是什么意思。下面小编给大家带来抖音惜亩惜仔意思介绍,感兴趣的小伙伴们一起看看吧。惜亩惜仔是什么意思惜亩惜仔也就是息母息子的意思,是指非常珍惜和母亲子女在一起的时候,一般用来指一些顾家的好男人。

EasyCutStudio是一款非常好用且专业的刻绘软件,兼容各种刻字机,绘图仪,为各种切割设备提供了产品设计到切割的一体化应用,有需要的赶快下载吧!

和平精英灵敏度怎么调最稳?对于很多新手玩家而言,看到抖音上大神掏枪稳的一匹,是不是格外羡慕;2265小编告诉你,其实别羡慕人家,你也可以的,只需要调整好灵敏度,进入状态,你丝毫不逊色那些所谓的网红!下面2265小编给你带来2020和平精英最稳灵敏度,新手可以

游戏市场百花齐放,而且随着网络的发展,各个国家之间的游戏也开始出现在异国他乡,今天和小编一起来看韩国大型3d手游排行榜前十名合集,这些都是非常受到韩国玩家欢迎的游戏,每一个游戏都是立体的画面设计,这能让整个游戏的质感更强,同时玩家在游戏的过程中也会更有代入感,如果对于这些游戏感兴趣的话,那千万不要错过小编的内容,1、,幻塔,这是一个可...。

庞大的餐饮市场有很多特色餐饮店,每个店铺都能坚持自己的招牌菜系、麻辣香锅菜品大家都很熟悉,这也是很多餐饮店的招牌菜,香锅老师主要以麻辣香锅、麻辣烫美食研究为主,能够在餐饮市场获取更多顾客好评,香锅老师加盟优势有哪些,如果大家对品牌感兴趣,可以了解一下详细优势,香锅老师品牌起源于重庆,能够将川渝地方的特色美食综合起来,根据地方消费者的口...。
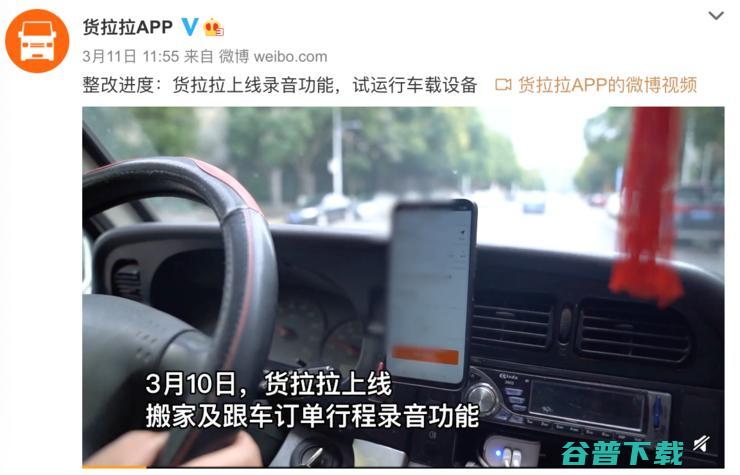
货拉拉公布整改进度,上线行程录音功能3月11日,货拉拉官方微博发布短视频公开其自长沙坠车事件以来的整改进度,并配文,货拉拉上线录音功能,试运行车载设备,视频中,货拉拉风控负责人朱怀宇展示了货拉拉自主研发的,安心拉,智能行驶记录仪,称其通过安装多路摄像头,驾驶室摄像头、路面摄像头、货厢摄像头,、GPS等传感器全方位采集车内环境和货物数...。

由浙江精准学公司,以下简称,精准学,研发的首个原生代AI辅学机Bong系列,将于6月正式发布,精准学已获得阿里巴巴近2亿元投资,将用于产品的研发和推广,AI垂直应用领域的商业化,首战,在教育行业打响2023年是中国庞大资金和技术资源投入AI大模型的集中年,2024年伊始,投入更是日趋白热化,随着中国AI大模型日趋成熟,寻找合适的窗口...。

日料相信现在年轻人都喜爱吃,在没有品尝过这种美食的时候,听着就忍不住想要品尝一下,这种产品吃法新颖,将各种新鲜食材,蘸酱品尝,还有直接生吃,主要是根据个人口味喜好,进行选择,从中西文化结合之后,国内市场上也出现很多特色日料店,由于产品味道突出,得到快速发展,创业者也看到项目未来发展前景,所以想要知道,日本料理店加盟连锁品牌有哪些,近年...。
