IEEE Fellow 上科大 第四届中国人工智能安防峰会 我眼中的城市元宇宙 虞晶怡 (ieeefellow)

2021年12月11日,由& AI 掘金志主办的第四届中国人工智能安防峰会,在深圳正式召开。
本届峰会以「数字城市的时代突围」为主题,会上代表城市AIoT的14家标杆企业,为现场和线上观众,分享迎接数字城市的经营理念与技术应用方法论。
作为上午场的开场嘉宾,虞晶怡从深度学习的角度,从建模、渲染以及隐私保护三个方面分享了对未来城市元宇宙的理解。
虞晶怡提到,他所研究的计算机视觉领域一个非常重要的任务,就是完成物理世界向数字世界的映射。为了完成这个映射,产生了非常多的概念,比如最早的数字孪生,到现在的元宇宙。但无论是什么概念,归根到底需要解决几个核心问题:
三维建模如何完成?图像分析如何完成?隐私保护如何完成?
虞晶怡教授从四个方面出发阐述了对以上问题的理解:
计算成像、三维重建、智能融合、隐私保护。
2D计算成像。过去几年,编码成像取得了很大的进步。在图像质量方面,利用编码成像可以在高速和离焦的情况下获得更好的图像。
虞晶怡指出,做智慧城市离不开三维重建。计算机视觉界已经做了很多年,其中最为出色的解决方案来自谷歌的“一日建模”。具体有三个步骤:通过针对大量图像进行位置猜测,再通过特征提取获取精确的相机位置,再对图像特征进行匹配和三维确认,最后得到模型,这个方式在大规模城市重建中非常常用。
基于神经网络深度学习的最新方法,即2D+3D融合。因为很多智慧城市模型并不精确,将城市进行三维重建后,把二维的贴图与三维模型融合,可以得到多视角视频。
最后,虞晶怡教授着重分享了隐私保护,他认为重建做得无论多好,最重要的是保护隐私。
以下是虞晶怡演讲全文,AI掘金志作了不改变原意的整理与编辑:
今天给大家分享一个我认为非常有意思的话题,主题叫《The future of MetaCity:Modeling,Rendering,and Privacy Protection》,讲讲我眼里的元城市,我会从深度学习的角度分享如何建模、如何渲染,以及最重要的如何保护个人隐私。
大家讨论的智慧城市是什么?这是一件很有意思的事情。我记得很多年前王坚博士跟我有个讨论,他想要知道智慧城市的一个功能,比如“你能不能告诉我现在马路上有多少辆车在开?”
这个问题听上去好像很简单,其实很复杂,虽然我们已经有大量摄像头,但每个摄像头只能看到城市中很小一部分的车辆,如何统计出它们分别在什么位置,如何计算出有多少车辆是非常大的挑战。
我研究的领域是计算机视觉,其中一个非常重要的任务是完成从物理世界向数字世界的映射。完成了这个映射,大家就可以玩各种概念。而从最早的数字孪生到现在的元宇宙,归根到底,需要解决几个核心问题:
三维建模怎么完成?图像分析怎么完成?隐私保护怎么完成?
今天的演讲主要分为四个部分:计算成像、三维重建、基于神经网络深度学习的最新方法、隐私保护。
计算成像/2D高清图像/智能视觉
第一部分,所谓的2D高清图像,就是传统的计算成像。过去二十年我一直在做计算成像,设计了各种各样的相机系统。
相机系统本身很复杂,有很多组成部分,比如相机的镜头、快门、闪光灯、光圈以及各相机阵列。得益于计算成像,在获取图像之后可以通过各种计算方法对图像进行进一步的分析,基于此,我们已经可以做很有意思的事情了。

2018年上海第一届进博会,我们展示了一个技术,叫“亿万像素的上海”,照片可以进行实时无穷尽地推进。
可能大家都去过上海,但绝大部分的人没有去过东方明珠的塔尖(因为去的话就会被就地拘留)。这幅图片是140亿像素的上海,我可以随时随地做实时渲染,也可以推进到东方明珠的塔尖,你甚至可以看到塔尖上有几根天线。
这个系统是如何完成的?通过光场相机系统,用很多相机拍摄后进行拼接,再进行渲染。我们不希望这个渲染是在集群上进行的,因为云端渲染非常昂贵,而是在手机等便携终端上,比如刚才的示范样片就是在小米电脑上进行实时渲染。

我们当时利用了计算成像的算法技术,其实就是把图像进行分级的分割和存储,最后在存储之后,就能够非常快地索引到每一个部分的模块,这个文章发在TVCG上。
这项技术最近有很多进展,过去一年,有很多基于深度学习的方法,能把整个图像压缩在一个网络之中。
计算成像另一个优势是,不但能做超高清的成像,还能做超高速的成像。


十年前我做了一项工作,叫“超高速下的编码快门成像”(Coded Shutter Imaging:Ultra-High Speed),我拍摄了高速运动的车辆,试图通过图像的逆问题把图像恢复出来,比如高清恢复车牌。
传统的快门在高速运动下为什么做不了?
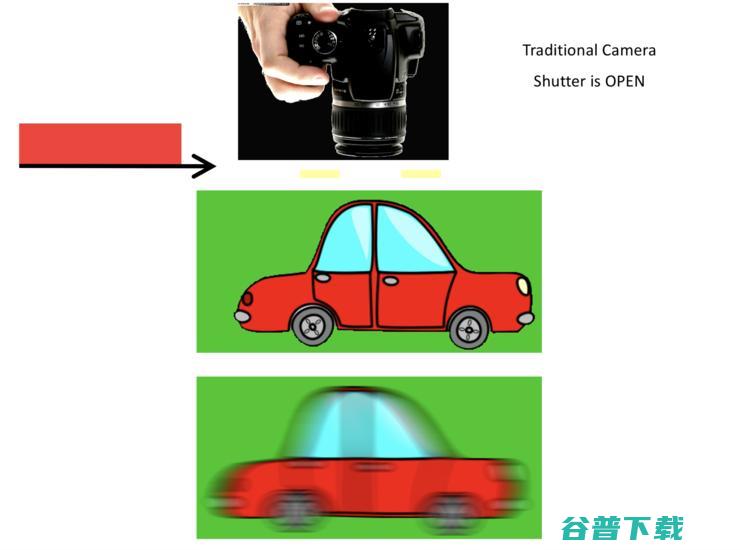
在传统快门高拍摄的过程中,整个快门就是关和开,如果把这个问题映射到傅里叶域,首先面临的是图像卷积的问题,它等于是用模糊的(也就是低频的)卷积核卷积了一张清晰的图像,整个图像的高频成分会被损坏,更糟糕的是逆卷积非常难,因为这是基本的数学问题。
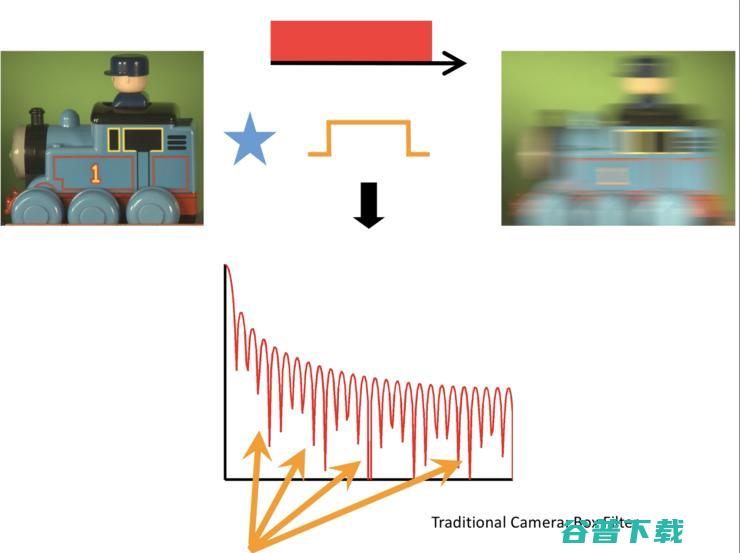
Sinc function有一个弊端,首先它的高频部分会发生非常猛烈的振荡。其次,它会多次切入零点,如此,这个乘积就无法做除法,因为到处都是0点,那怎么求解这个问题?十年前我们就开始想如何解决这个问题。
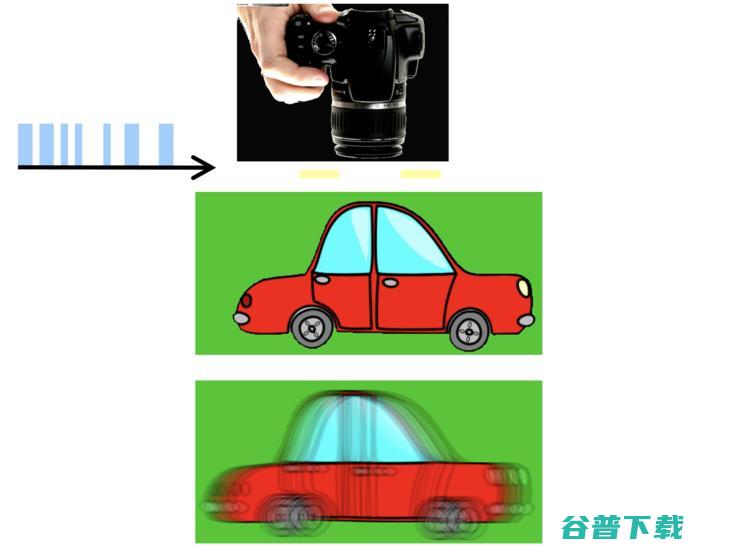
第一种方式是快门随机地开/关,图像同样会被模糊掉。但为什么这个随机的开/关能使得“去模糊”的方法做得更好?因为随机开/关,等价于每次开的时候是sinc 函数,但因为它的位置不一样,等于把不同的sinc 函数在里面叠加,其结果就是这个频谱非常好看,因为同时在这个位置出现0的可能性非常低,我的目标是在频域里不希望出现0点,出现0点没办法除。有了这个频谱之后,用编码成像的方法对图像进行恢复,结果恢复得很好。

举个例子,这是一幅编码成像的图片,是我的同事在MIT拍摄的。大家可以猜一下这辆红色小轿车是什么型号?是哪个厂出的?绝大部分的人会猜测它是奥迪,也有人说是TOYOTA,但其实这个车通过编码成像,恢复出来的是大众的车牌。在过去这些年,编码成像得到了长足发展,在高速成像、散焦成像上都能通过编码成像得到更好的图像,过去几年很多高质量的图像都是通过编码成像技术获得。

三维重建
做智慧城市避不开三维城市重建,这在计算机视觉界已经研究了很多年,其实最为出色的解决方案是来自谷歌的“一日建罗马”。大家都说“罗马不是一日建成的”,所以他们在罗马这样的城市级别做了大规模重建。他们的想法是拍摄大量城市的图像,把这些城市的图像通过相机位置的标定和三维重建的方法进行三维重现。

具体展开,分为几个步骤:
先是针对大量图像进行位置猜测,有很多方式,对城市级别来说,可以用GPS信号等数据做粗略定位,再通过特征提取获取精确的相机位置,然后再对图像特征进行匹配和三维关联确认,最后得到稀疏的3D点云信息。
对于大规模的城市这个方法非常常用。大家最熟悉的是倾斜摄影,大规模的城市尺度都是利用无人机拍摄然后进行计算,这个方法本身有几个比较严重的问题,最主要的问题是非常昂贵。

凡是做过大规模城市尺度重建的都知道,在集群上运算的时间长达半天,其实半天时间已经非常少见,绝大部分都需要运算几天几夜,而且,运算完后得到的点云依然很差。这是因为点云本身依靠特征来提取,特征本身是稀疏的,所以得到的点云本身是稀疏的三维点云。
如果这样给政府做城市级别的重建,会非常辛苦,你需要找一个非常大的艺术团队帮你修复,因为所有的点云都需要把噪音抹掉,把点云修正成几何形状,这是所有做过智慧城市的人都感同身受的。
智能融合
随着技术的发展,这两步分别都将得到很大的进展。第一个是三维点云的获取,传统三维点云的获取是依靠倾斜摄影和图像,现在可以通过视觉定位、扫描和点云的LiDAR进行补偿。

因为LiDAR系统本身无法做三维空间的定位,你可以把LiDAR系统和视觉相机混合,靠视觉相机进行三维定位。
举个例子,我的学生在上科大创办的岱悟智能,让用户头上顶着LiDAR和RGB相机,RGB相机做定位,LiDAR获取场景里三维稀疏的点云信息,通过不断行走就可以把整个场景呈现出来。
我们上次做了一个尝试,把这个设备装在小车上,15分钟就可以完成一平方公里的地下车库扫描流程,效率非常高。
给大家展示一下我们当时完成的上海科技大学地下车库的数字孪生,人徒步完成还是比较吃力(但对码工来说走一个半小时还是蛮减肥的)大概15-20分钟就可以完全完成数据的采集。三维点云的采集不再需要复杂的计算机视觉系统,而是用比较简单的LiDAR+视觉定位的方式来解决,这将成为未来的大趋势。
同理,这个系统也可以装在无人机上,过程非常快。我们做了一个尝试,在上科大一平方公里的范围内进行边飞边实时产生点云,结果很酷。

几年前我看过一个电影《普罗米修斯》,就是拿三维小球,在三维空间进行扫描,隧道场景很快就出现了,也就是说这个梦想已经成真了,可以非常快地做外部场景的扫描。
有什么用?扫描之后你可以做很有意思的事情。
比如对工地进行监控,看工地是否每日按照图纸的规划进行建设,随着多次的扫描,不但可以获取非常高清的工地三维数字孪生模型,还可以把无人机拍到的视频信息融合。其实也就是把图片和三维几何的模型融合,切入到模型时,瞬间可以切换到高清图片,可以看到每一个图片的高清细节,效果非常酷炫,而且确实有用,上海很多社区都开始使用这个技术进行二纬和三维的融合了。
这对智慧城市有什么用?

第一,很多智慧城市的模型并不精确,是CG模型,通过我们的技术可以进行点云数据+视频/图像融合。
第二,很重要的点,能解决当时王坚博士的问题:在三维空间里判断有多少辆车。
2018年、2019年我们在徐家汇商圈做了一个很有意思的事情。当时我们用上述方式,把整个徐家汇的商圈进行了三维重建。重建之后,把路灯、楼顶视角的视频融合在一起,现在各位看到的是多个视角融合的视频。
如果我把一个区域内所有的视频融合在三维空间,我就可以告诉你现在路上有多少辆车在跑,有多少人在行走,这对智慧城市来说解决了非常重要的一个问题。有了这套系统,可以做非常多很酷的应用,比如可以做碳排放的检测,因为我知道有多少辆车,耗能是多少。
传统的三维重建,几何是几何、图片是图片,几何和图像是分离的。下面我想讲最为有意思的一部分,《Neural Modeling and Rendering》,用神经网络的办法把几何和图像融合在一起。

这是来自英伟达非常酷的一个demo,是为了游戏而做的。在这个demo里所有的几何都是定死的,但我可以随意地做风格迁徙,比如我希望它是沙漠,它就可以是沙漠,我希望树是真实的,就可以做真实的树。左下角是非常粗略的模型,但是有语义分割。根据语义分割和三维场景的粗略几何,可以变换分割成右上角这样看上去非常真实的三维图像。
换言之,我可以通过学习的方法,把粗略的几何恢复成非常好的三维的模型,从而大幅度降低人工成本。
过去十年里,我最为欣赏的一个项目来自加州大学伯克利分校,他们把几何和外观融合在一起。
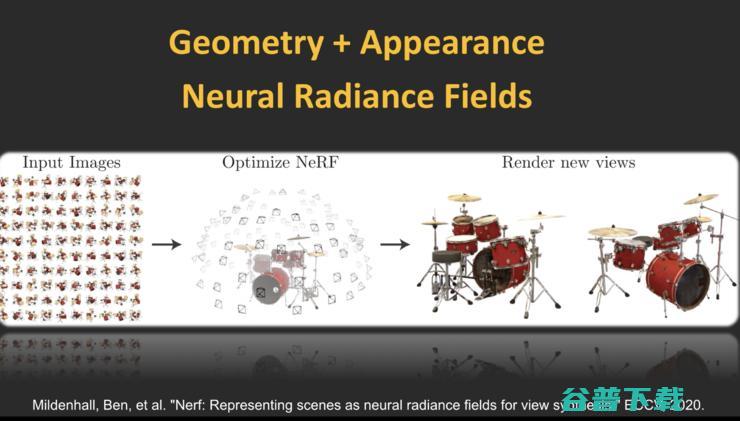
在传统的方式中,要用点云或mesh来表示几何,然后再用贴图的方法构建外观,如果点云或贴图的质量不好,合成效果就很差。
前面讲了,我需要从多视角拍摄图片重建几何,那我不如把所有的图片都输入到一个神经网络NeRF中,训练完之后可以渲染任意视角下的任意图片,这样可以实现无需几何先验的几何重建。
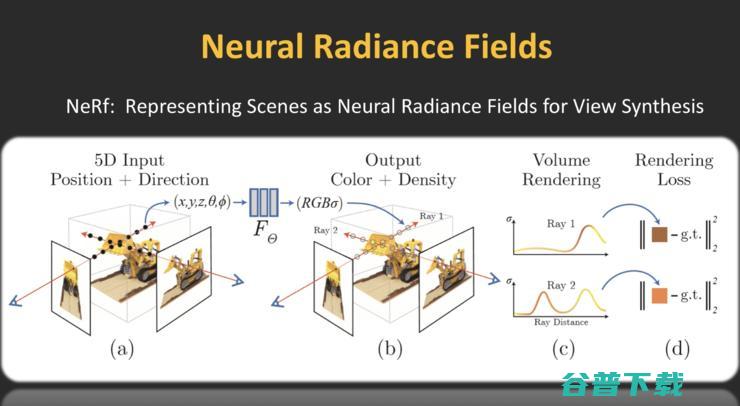
怎样实现这件事?用神经网络完成光线-颜色-深度的映射,每一根光线可以用X、Y、Z,也就是光线的原点以及方向来表述,通过网络可以告诉你沿着这个光线应该看到什么样的RGB颜色,此外网络还会预测一个sigma参数,它代表的是X、Y、Z处的物质密度,如果密度很高说明存在物体,密度很低说明是真空的。
如此一来我就可以做很有意思的东西,也就是说,我们训练网络的时候,可以把几何和纹理的概念抛弃,我拥有的就是神经网络,只需完成利用这个神经网络从光线到颜色到深度的预测,几何和纹理就自然地生成了,这是我过去看到的非常酷的工作。过去几年大家逐渐意识到,原来用NeRF框架,不但能做元宇宙物体的生成,也能做元城市级别的生成。

以上介绍的主要是别人的工作,先说一篇《NeRF in the Wild》的工作,跟前面的工作的思路是一致的:也即是输入很多图片,同时这些图片包含了位置和图像性质,以及一个很有意思的概念——瞬态。瞬态是什么意思呢?比如我在三维空间拍摄了很多图片,因拍摄的视角不同,有的地方有遮挡,比如楼前面有树的遮挡,也有行走的人的遮挡。但因为我拍了很多图片,而且是在不同视角拍的,所以会产生很多不同的视角,唯一不变的就是静态几何,一直在变的是瞬态。然后我们可以将瞬态和静态几何一起重建,最后还可以把瞬态和静态几何进行分离。同样,用NeRF框架,所有一系列的工作,都可以通过一个神经网络的训练而完成。
我们看一下它的结果,非常酷。因为图片是白天和黑夜不同时刻拍摄的,但我能够在不同时刻展现出前景和后景的渲染,没有几何,用NeRF框架、神经网络表征这么大尺度的场景。
我们再看一些更复杂的场景,比如它可以在布拉格的街区用网络成像来做。
这是罗马的喷泉。虽然点云用传统的三维重建会很差,但没关系,用NeRF框架可以产生非常好的三维结构。这个方法不仅能重建外部几何,也可以在重建内部几何,比如在一个建筑的内部拍摄大量图片,然后用神经网络的框架进行重建。
这是在印度做的,通过多视角的图片,其实没有真正显示重建几何,而是隐式地表示三维重建的效果,它是全自动的,不需要人去修,所以大家看到这个结果应该觉得非常惊艳,如果用artist去修是非常大的工作量。
去年有一篇很有意思的论文《Urban Radiance Field》。想法类似,输入很多图片,但跟前面论文不一样的是,它还结合了LiDAR的点云信号。
前者的几何依然需要NeRF训练,但NeRF的训练非常慢,所以他们索性就用LiDAR产生的点云信号作为输入,输出是完整、高清的三维重建,同时还有一个高清的视角渲染,这非常酷,从多视角图片的倾斜摄影技术往点云融合。
但我当时研究还差了一步,用NeRF的框架做渲染,现在大家可以看到神经网络的这个强大功能。
这是一部分渲染的结果,可以看到上面的点云和光斑变化。这是圣保罗的场景,可以在里面走来走去,产生相当不错的渲染效果。
最为重要的是,这里不需要artist去修,否则人力成本太高了,不可能完成元城市(MetaCity)的重建。不同的国家和不同的城市都能使用这个方法,相当大规模的几何重建渲染,全是依靠NeRF的框架实现,所以我觉得它的效果还是非常酷的。
给大家介绍了基于神经网络三维重建的工作,很多是别人的工作,也有一部分是我们的工作。
隐私保护
最后我想讲,重建做得无论多好,最重要的是保护隐私。
给大家讲一个我的故事。2010年,十年前我和林海滨教授做了一个项目,内容是如何在安防系统下进行隐私保护。现在看来这个工作还是非常有意思的,因为2010年并没有想到安防会发展到如此高的地步,隐私保护当时也没有受到重视。

前面提到,可以通过图片快门的控制,把曝光变得模糊。我们在想,能不能故意把图片进行模糊?模糊了图片就可以保护隐私了。
听起来很容易,但问题来了,模糊完了图片,怎么保证捕捉重要的信息?比如我需要知道这个人的行为,但不希望泄露这个人的身份。
当时我们提出一个非常酷的概念。把一个视频用两种不同的模式进行模糊,我们把这两种模式称为互素的,这里借鉴了数学中的素数概念。

这样做有什么好处?如果只是给低权限的人看,只需要给他看模糊线条轮廓,它可以用任何现有的算法,对监控视频进行去模糊,结果看不到脸,但能看到人的行为。但对于高权限的人来说,我可以给到两个已经模糊后线条轮廓,通过互素性质对图像进行去模糊,从而产生非常高清的监控视频,我们的论文发在PAMI上,当时这个想法还是非常酷的。
这个结果很有意思,左上角是一个模糊的图像,你可以通过最好的方法进行去模糊。右上角和左下角的去模糊方法可以恢复人在行走的信息,但无法恢复出人脸的细节。而在右下角,如果是高权限人群,可以同时拿到两个blur stream,利用互素的性质对整个图像进行解码。非常重要的一点是,不需要知道这些图像用什么kernel进行模糊的,就可以对其进行解码。
另外,我们希望通过多闪光灯的方法进行保护。可能大家会觉得很奇怪,为什么多闪光灯能进行隐私保护?

通过闪光灯,可以产生影子。闪光灯如果在左边,影子就会在右边。如果闪光灯在右边,影子会在左边。随着闪光灯位置的变化,影子也会产生变化。根据影子的变化,我可以分析这些影子是如何变化的,从而获取到一个非常有意思的图像。虽然我没办法精确知道它的深度是什么,但可以提取出它的深度边界。

为什么这件事对隐私保护很重要?这是一款老旧的车,通过多闪光灯的方法,可以非常准确地把边界提取出来。其中一些细节,比如看左上角的图,我知道这个车生锈了,但左下角的图看不出生锈,这是很具体的生锈的纹理,跟深度不相关的信息,会被我们轻易抹去。
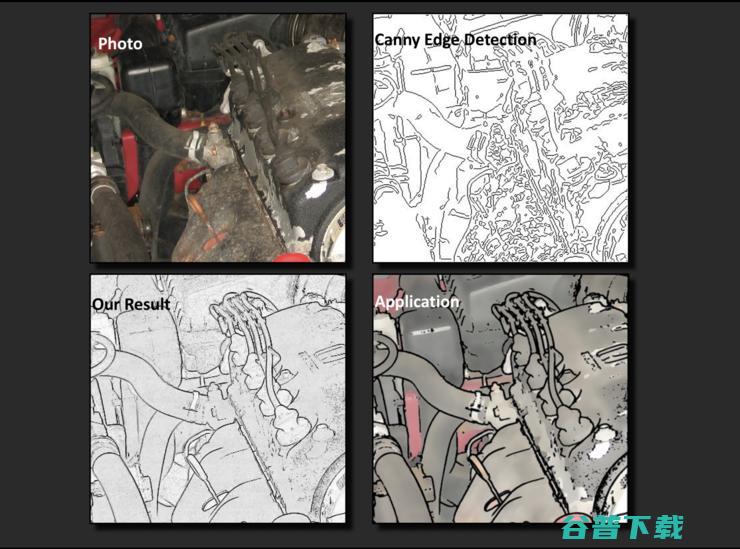 如果我的安防是由多个闪光灯组成的,就可以把多个重要的身份信息隐藏,比如海报上的字,比如衣服上的花纹,都可以被抹掉,从而起到隐私保护的作用。
如果我的安防是由多个闪光灯组成的,就可以把多个重要的身份信息隐藏,比如海报上的字,比如衣服上的花纹,都可以被抹掉,从而起到隐私保护的作用。

再比如人脸上有很多特征,像左图里的痣,是非常明显的身份标志,但痣本身是一个纹理,通过闪光灯的方法,可以把痣去掉,通过边界对图像进行模糊,刻意去掉这个信息。
2010年的时候,美国对隐私保护不够重视,当时我们两人写了一个非常激动人心的项目,但被否定了。我记得非常清楚,其中有一个回复的意见说:隐私保护是已经解决的问题,你们为什么还要再写一个隐私保护的提案。可见大家在做研究的时候,必须先有先知,要意识到这个事情对整个社会的影响。
总结一下。我给大家介绍的最新的MetaCity的工作,包括2D成像、3D重现的技术、用神经网络的建模和渲染方法对整个智慧城市进行建模,它的最大功效,不需要人工参与,就可以对渲染起到增强和去噪作为。隐私保护是重要组成部分,前面讲到两种隐私保护的方法,我今天特别介绍了用神经网络,本身它就具有隐私保护的作用,因为传统方式需要传几何、图片,但几何和图片全都被编码在神经网络中,这个神经网络本身又能起到隐私保护的作用,又能有效地渲染图片。
原创文章,未经授权禁止转载。详情见 转载须知 。


LOL网址导航网是专业的上网导航网站,精心收录各类优质热门网站信息,同时提供天气、快递、违章等各种生活便民查询工具网址,为您提供安全便捷的上网导航服务,现已被众多网友设为上网主页,网址导航大全首选LOL网址导航.

【15年壹起航】深耕于网络推广,专注全网营销,品牌维护,品牌推广,网站推广,企业品牌塑造,一手全网整合营销资源,自研建站系统及短视频系统,百家渠道代理商,3000+企业用户合作,联系壹起航。

精品酒店预订网是国内领先的在线酒店客房搜订平台,凭借现代化的通信系统、在线电子商务技术和完善的客户管理系统,通过一体化的专业呼叫中心,向广大的商旅人士提供集酒店定位搜索、实时房态、在线订房、出行资讯等在内的商旅服务。

东莞市柠檬纸品包装有限公司主营:精品盒,精装盒,礼品盒,手工盒,折叠盒,抽屉盒,翻盖盒,天地盒,书型盒,对开盒,异形盒,首饰盒。工厂占地1.36万平方,员工200+,产能10万+。

山东云唐智能科技有限公司是一家专业生产食品安全检测仪,食品快速检测仪,土壤养分检测仪,土壤肥料养分检测仪,植物生理检测仪器,物联网气象仪器的厂家,检测快速准确,价格实在,欢迎新老客户、供应商来电咨询.

广东省粤西机械设备有限公司

全咨数字平台

中山市三易测量仪器有限公司,2009年02月16日成立,经营范围包括生产、销售:仪器、仪表、五金配件等。扎根于在线密度计、浓度计、压力变送器、流量计、液位计、温度等过程控制仪表的研发和生产制造。在线浓、密度检测具有长期深入的研究及现场应用经验。

本地代开工资流水服务商【电/微:186-7711-6696】提供代开入职薪资流水、企业对公流水、银行流水打印,业务覆盖北京、广州、上海、深圳、杭州、南京、济南、成都、昆明、沈阳、武汉、长沙、重庆、天津、郑州、长春、西安、合肥、太原、福州、南宁、南昌、石家庄、青岛、大连、珠海、银川、西宁、哈尔滨、乌鲁木齐、贵阳、兰州等城市.

慧林科技成立于2005年,是一家专为IDC行业提供相关管理系统及各类解决方案的双软高新研发型企业,拥有十多年的各类IDC相关系统开发经验,国内前沿的研发团队,集研发、销售、售后服务为一体,业务覆盖全国各省市。

四川成都埃克森美孚润滑油授权经销商,汽车用油,工业用油。

扬州福达海绵机械有限公司专业生产海绵机械,软木机械,软木旋切机,软木平切机等,咨询0514-87513996,主要产品:聚氨酯抛光片平切机、海绵机械(平切机、旋切机、打孔机、立切机),软木机械(平切机、旋切机)橡胶机械(平切机、旋切机、刨切机)压力机(单缸压力机、双缸压力机)等一些列配套设施,另还有火焰复合机、胶粘复合机、搅拌机等。尤其是生产的软木机械和橡胶机械及聚氨酯平切机,拥有多项发明专利的使用权,在软木和橡胶行业深耕多年,拥有良好的口碑,广泛获得客户的认可。通过不断的积累和进步,逐步开发出新的产品提高竞争力,以适应现在的市场环境。


刚收到@DNSADMIN爆料,网上流露出一份文件,上面显示要求网站进行公安备案,要求做公安备案,落实出现违法内容责任到人,文件显示,根据国家要求,互联网站应当自网络正式联通之日起三十日内,到所在地的省、自治区、直辖市人民政府公安机关的受理机关办理公安备案手续,强化互联网站备案管理,落实网站开办者实名制,公安部十一局研发了,全国公安机关...。

现在餐饮业非常地受欢迎,因为大家在外面吃饭的次数很多,餐饮的市场发展前景可观,而且它的发展很大,今天小编要为大家介绍的是勾馋麻辣烫加盟,勾馋麻辣烫口味非常好,消费者对它的好评如潮,下面一起来了解一下餐饮加盟模式餐饮加盟模式是怎样的呢,像勾馋麻辣烫这个项目是隶属于集团的,实力非常雄厚,属于加盟连锁,勾馋麻辣烫在全国有上千家,在各方面的经...。
对于运营小白,为了学习运营知识,总是在网上搜罗运营的知识点,看了很多也记了很多,真正到了工作中还是无从下手,或者按照网上的知识点行动之后,总觉得偏差有点大,导致小白彷徨,深度怀疑自己不是做运营的料,一度想转行,其实,网上的碎片化的知识点对于做好运营工作帮助不小,而是建立在运营系统之下才会产生较好的效果,所以做好运营工作还是依靠系统化运...。

人人影视字幕组创始人被判刑,官微表态,App可以删了,不可能重启了11月22日消息,上海市第三中级人民法院公开开庭审理了上海市人民检察院第三分院提起公诉的被告人梁永平涉嫌犯侵犯著作权罪一案,并当庭作出一审判决,以侵犯著作权罪判处被告人梁永平有期徒刑三年六个月,并处罚金人民币一百五十万元;违法所得予以追缴,扣押在案的供犯罪所用的本人财物...。

和很多车圈一把手不同,李想在入局车圈之后所推崇的对象并非亨利福特,也不是马斯克,而是从未造过车的苹果公司创始人乔布斯,作为乔布斯的信徒,李想从不讳言理想汽车就是要向苹果学习,对苹果产品逻辑和简洁风格的推崇,在发布会的风格上、在现有的理想SUV车型中都有体现,李想认为,苹果的产品理念有两个核心,一是如何把极致奢侈的东西变成大众买得起的产...。

韩国总统尹锡悦将于11月14日至21日访问秘鲁和巴西,缺席亚太经合组织,APEC,和二十国个人,G20,峰会,韩国国度安保室第一次性长金泰孝在记者会示意,韩方正与美日踊跃展开沟通,努力于促进三国指导人谈判,韩总统室还在推动尹锡悦同美国入选总统特朗普会晤,...。

如题主想要了解的,路虎自在人越野性能怎样样?,关系内容引见有以下,路虎自在人越野性能性能,1、做为紧凑式的suv,带有显著的品牌特征,具备显著的吉普特征-传统的圆形大灯,竖条形的散热器条栅,而且都是七条条栅,与旧吉普一样,但同时又有自己的特征;2、它可装备三款发起机,区分是直4缸2.4升或v6缸3.7升汽油发起机,直4缸2.5升增压式...。

作为国际出名的轻型商用车制造商,华晨金杯的品牌价值和市场影响力不时位居行业前列,面向现代物流、市区快递、游览应酬、校车接送等市场需求,华晨金杯推出的面包车以其稳固性和牢靠性备受用户青眼,上方就为大家引见一下华晨金杯面包车的报价及其图片,1.阁瑞斯CV系列这是一款以宽阔温馨、安保牢靠、经济适用为主打特点的面包车,提供了9座、15座、18...。

7月2日,有律师发文称,在贵阳市云岩区法院闭庭时,遭逢法警暴力执法,当日下午,贵阳市云岩区法院上班人员回应奔腾资讯时称,不分明此事,视频截图北京市汉鼎联结律师事务所何智娟律师发文称,7月1日,郑晓辉、孙健等四人涉嫌巧取豪夺罪一案在贵阳市云岩区法院闭庭,她与多名律师出庭辩护,第一天闭庭,她们就检察机关倡导法庭延期审理补充侦察后,对有无依...。

搭载2.0T发动机东风日产Pathfinder实车曝光,新车,东风日产,suv,日产,pathfinder,翼子板

重庆分类目录网站收录网络设备相关的优秀网站大全分类检索,为上网用户提供网络设备网站排行榜与您分享、收藏!

提供从软著申请应用商店资质账号申请协助到预审截图优化排名优化审核加急被拒修改版本更新全业务流服务覆盖苹果谷歌华为小米魅族百度应用宝等目标商店一门深耕生态服务郑重承诺没上架成功上架服务费全额退款商城上架备案流程商城上架备案是指将商城应用程序提交到应用商店进行审核并通过审核后发布应用程序的流程在应用商店上架备案对于商城应用...

好分数教师版考题得分率差值怎么查看,在好分数教师版上,老师除了可以查看到得分率差值,还有其他的教师权限,那么要在哪查看呢,下面小编就为大家带来了好分数教师版考题得分率差值查看方法,希望能帮助到各位小伙伴哦~...。

环境问题随着GDP的增长,暴露出来的问题越来越多,尤其是在重工业城市,雾霾着实让人难受,还有新的房屋装修好却不能入住,需要一个月左右的空气流通,这都给人们带来烦恼,人们就开始寻找可以使空气净化的好方法,寻找可以加盟的空气净化企业,那么我来为您介绍一下樱立方空气净化加盟怎么样,好不好,北京创天下环保科技有限公司以樱立方产品为市场投放前导...。

从现任施乐全球企业运营高级副总裁MikeSteep在帕洛阿尔托郊狼山的办公室,可以看到硅谷最好的风景,从这个办公室里望出去就是著名的硅谷,这里诞生了惠普、仙童半导体、英特尔、雅达利、网景和谷歌,这里是塑造了现代世界的创新发源地,也是Steep的雇主施乐公司的帕洛阿尔托研究中心,PARC,的所在地,个人计算和关键计算机网络技术就诞生于此...。

雷锋网按,本周,人工智能产、学两界的资深人士纷纷在顶级会议AAAI中亮相,分享了他们在各自研究方向的体会与心得,本期雷锋网AI科技评论周刊整理了清华大学朱小燕教授、麻省理工学院RosalindPicard教授、百度副总裁王海峰、亚马逊AWS机器学习总监AlexSmola的分享,独家,清华大学朱小燕教授做客AI科技评论,分享NLP和AI...。

在刚刚结束的成都大运会闭幕式上,人形机器人,天团,吸引了全球目光,在第三篇章,梦想·致未来,中,优必选自主研发的人形机器人WalkerX骑着平衡车快速行进、急速转圈、高速动作,与舞蹈演员,斗舞,拉开序幕,并触发本次闭幕式的重头戏,WalkerX骑着平衡车环绕舞台,用手指逐一点亮15块移动屏幕,与宋代著名绘画艺术珍品,蜀川胜概图,进行互...。
