10年内单个集群价值将达万亿美元 出天际 贵 芯片集群 (十年内包括第十年吗)
1958年,德州仪器的杰克.基尔比(Jack Kilby)设计出了带有单个晶体管的硅芯片。1965年,仙童半导体已经掌握了如何制造一块拥有50个晶体管的硅片。正如仙童半导体的联合创始人戈登.摩尔(Gordon Moore)当年观察到的那样,一块硅片上可容纳的晶体管数量几乎每年翻一番。
2023年,苹果发布了iPhone 15 Pro,由A17仿生芯片驱动,这款芯片拥有190亿个晶体管。56年来,晶体管的密度增加了34倍。这种指数级的进步,被粗略地称为摩尔定律,一直是计算机革命的引擎之一。随着晶体管变得越来越小、越来越便宜以及速度越来越快,今天实现了手握“超级计算机”的奇迹。但人工智能时代需要处理的数据数量之多,已经将摩尔定律推向了极限。
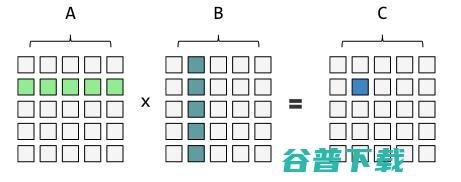
几乎所有现代人工智能中的神经网络都需要经过训练,以确定正确的权重(权重用来衡量输入信号对于神经元的影响程度,即不同输入的重要性权重),从而为其数十亿,有时甚至数万亿的内部连接赋予正确的权重。这些权重以矩阵的形式存储,而训练模型则需要使用数学方法对这些矩阵进行操作。
单层神经网络的本质是矩阵相乘 ,两个按行和列排列的数字矩阵集合被用来生成第三个这样的集合,第三个集合中的每个数字都是通过将第一个集合中某一行的所有数字与第二个集合中某一列的所有数字相乘,然后相加而得到的。如果矩阵很大,有几千或几万行几万列,而且需要随着训练的进行反复相乘,那么单个数字相乘和相加的次数就会变得非常多,这就是人工智能的“思考方式”,通过对输入数据的处理得出答案。
然而,神经网络的训练并不是唯一一种需要高效处理矩阵乘法运算的技术。游戏产业高质量的视觉呈现同样需要这一技术,在25年前,这是一个巨大的市场。为了满足这一需求,英伟达率先设计了一种新型芯片,即图形处理器(GPU),在这种芯片上布置并连接晶体管,使其能够同时进行大量矩阵乘法运算。与大多数中央处理器(CPU)相比,GPU可以更大批量地处理数据,而且能耗更低。
2012年,训练AlexNet(开创 “深度学习 ”时代的模型)需要为6000万个内部连接分配权重。这需要4.7x10^17次浮点运算(flop,算力最基本的计量单位),每次浮点运算大致相当于两个数字的相加或相乘。此前,这么多的计算量是不可能完成的,但当时两个GPU就完成了AlexNet系统的训练。相比之下,如果使用当时最先进的CPU仍需要耗费大量的时间和算力。
乔治城大学安全与新兴技术中心最近发布的一份报告称,在用于训练模型时, GPU的成本效益比CPU高出10-100 倍 ,速度提升1000倍。 正是因为有了GPU,深度学习才得以蓬勃发展。不过,大型语言模型(LLM)进一步推动了对计算的需求。
「Scaling Laws」打破「Moore's Law」
2018年,OpenAI的研究人员亚历克.拉德福德(Alec Radford)利用谷歌研究人员在“Attention Is All You Need”中提出的Transformers(采用注意力机制的深度学习模型),开发了一种生成式预训练变换器,简称GPT。他和同事们发现,通过增加训练数据或算力,可以提高大模型的生成能力,这个定律被称为“Scaling Laws”。
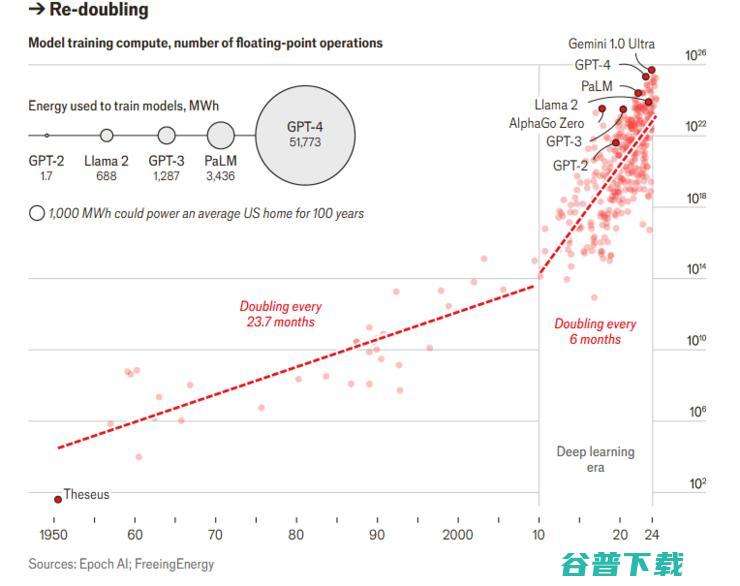
由于行业遵从Scaling Laws定律,大语言模型的训练规模越来越大。据研究机构Epoch ai估计,2022年训练GPT-4 需要2x10^25个 flop,是十年前训练AlexNet所用算力的4000万倍,花费约1亿美元。Gemini-Ultra是谷歌在2024年发布的大的模型,其成本是GPT-4的两倍,Epoch ai估计它可能需要5x10^25个flop。这些总数大得难以置信,堪比可观测宇宙中所有星系的恒星总数,或太平洋中的水滴合集。
过去,解决算力不足的办法就是耐心等待,因为摩尔定律还在生效,只需要等上一段时间,新一代的芯片就会集成更多更快的晶体管。但摩尔定律已经逐渐失效,因为现在单个晶体管的宽度只有几十纳米(十亿分之一米),要想实现性能的定期跃升已变得非常困难。芯片制造商仍在努力将晶体管做得更小,甚至将它们垂直堆叠起来,以便在芯片上挤出更多的晶体管。但是,性能稳步提升而功耗下降的时代已经过去。
随着摩尔定律放缓,想要建立更大的模型,答案不是生产更快的芯片,而是打造更大的芯片集群。OpenAI内部透露,GPT-4是在25000个英伟达的A100上训练的,这些GPU集群在一起,以减少在芯片间移动数据时造成的时间和能量损失。
Alphabet、亚马逊、Meta和微软计划在2024年投资2000亿美元用于人工智能相关的领域,比去年增长45%,其中大部分将用于打造大规模的芯片集群。据报道,微软和OpenAI正计划在威斯康星州建立一个价值1000亿美元的集群,名为 “星际之门”(Stargate)。硅谷的一些人则认为, 十年内将出现一个价值1万亿美元的集群。 这种超大规模基础设施建设需要消耗大量能源,今年3月,亚马逊在一座核电站隔壁购买了一个数据中心,该核电站可为其提供千兆瓦的电力。
对人工智能领域的投资并不全是在GPU及其功耗上,因为模型一旦训练完成,就必须投入使用。使用人工智能系统所需要消耗的算力,通常约为训练所需算力的平方根,这样的算力需求仍然很大。例如,GPT-3需要3x10^23flop的算力来训练,则推理需要3x10^11flop算力。FPGA和ASIC芯片是专为推理量身定制的,在运行人工智能模型方面,比使用GPU更高效。
不过,在这股热潮中表现最好的还是英伟达。英伟达的主导地位不仅来自其在GPU制造方面积累的技术和投入大量的资金(黄仁勋称,Blackwell的开发成本高达100亿美元)。此外,英伟达还拥有用于芯片编程的软件框架,即近乎已成为行业标准的CUDA。
竞争对手都在寻找英伟达的弱点。AI芯片独角兽企业SambaNova Systems的CEO Rodrigo Liang称,英伟达的芯片有几个缺点,这可以追溯到它们最初在游戏中的用途。其中一个特别大的问题是,在数据存取方面的能力有限(因为一个GPU无法容纳整个模型)。
另一家AI芯片初创公司Cerebras则推出了21.5厘米宽的“晶圆级”处理器。目前的大部分GPU包含大概成千上万个独立内核,可以进行并行计算过,而Cerebras开发的芯片包含近100万个。Cerebras声称,其另外一个优势是,它的能耗仅为英伟达最好芯片的一半。谷歌则推出了自己的张量处理单元(TPU),可用于训练和推理。其Gemini 1.5 ai模型一次摄取的数据量是GPT-4的八倍,部分原因就是采用了定制芯片。
尖端GPU的巨大价值与日俱增,使其成为地缘政治的筹码。虽然芯片产业是全球性的,但只有少数几个国家的技术控制着进入芯片产业高地的通道。英伟达的芯片在美国设计,世界上最先进的光刻机由荷兰公司ASML制造,而只有台积电和英特尔等尖端代工厂才能使用最顶级的光刻机。对于许多其他设备来说,地缘政治因素同样暗流涌动,日本是其中的另一个主要国家。
发展芯片和人工智能技术带来的政治博弈,使各国在这两个技术领域的投入不断增加,美国政府对向中国出口先进芯片实施严厉的管控,而中国正在投资数千亿美元来建立自己的芯片供应链。大多数分析人士认为,中国在这方面与美国仍存在较大的差距,但由于华为等公司的大笔投资,中国应对出口管制的能力比美国预期的要好得多。
美国也在加大投资力度,台积电在亚利桑那州投资约650亿美元建立晶圆厂,并获得约66亿美元的补贴。其他国家同样积极参与到这场竞争中,印度投入100亿美元、德国160亿美元以及日本260亿美元,未来,通过垄断人工智能芯片以阻碍其他国家人工智能产业技术发展的方式或许将会失效。
本文由编译自:


七喜影院网为您提供最新电视剧排行榜,韩国、美国、英国、日本、泰国、香港TVB全新电视剧、好看的电视剧等热播电视剧排行榜,并提供免费高清电视剧在线观看,在线看电视剧尽在七喜影院!

老客网是完全免费发布信息的分类信息网站,涵盖房产、车辆交易、教育培训、二手货、宠物用品、招聘求职、家政服务、装修建材、旅游酒店、招商加盟、医疗健康、餐饮美食、美容美发等分类。是商家免费发布信息、推广产品服务的理想平台。

云转码视频系统提供网页大文件上传+服务器端转码切片软件+流媒体软件+防盗链软件+分发软件,通过简单操作就可以整合到任何网站系统。

美术高考网www.mkao.cn创建于2006年,美考网定位于美术高考信息查询网站,为广大艺考生和家长提供最新的艺术院校招生简章、成绩查询、美术培训班画室、查询美术高考信息就上美考网。

常德物流公司,常德货运公司,常德托运公司

温州市龙湾永兴鑫荣达阀门厂是一家专业生产球阀,闸阀,截止阀的阀门供应商。以质量求生存,以科技为发展。联系电话:0577-887677890577-88757879销售热线:15958706338

瑞典米卡艺术涂料是国际化高端艺术涂料品牌,截至目前,累计为全国120万+家庭提供优质的艺术涂料软装服务,在全国拥有1200+代理商,1300+终端门店。凭借“墙面效果就是好”的品牌主张,“好产品、好工艺、好色彩、好榜样”四大战略配称,为消费者打造环保、高品质的美好生活。

广州软件开发公司,可承接管理软件、网站、WEB系统、微信小程序、H5系统、各类业务软件、各类APP软件等的定制开发、外包、软件人力外包、二次开发等

沂南攀峰骨科医院沂南攀峰骨科医院原为沂南中医整骨医院,始建于1978年,1998年经上级批准扩建为沂南攀峰骨科医院。是以骨科疾病诊疗、康复为主具有中医特色的非营利骨科医院,在骨科疾病治疗、康复等方面有独到之处。医院连续多年被县卫健系统评为优秀先进单位。

安徽世控仪表有限公司主要经营锈钢耐震压力表,不锈钢膜盒压力表,抗震压力表,耐震压力表,隔膜压力表,一体化温度变送器,压力仪表,不锈钢耐震压力表,不锈钢膜盒压力表,温度仪表,液位仪表等,电话:13505509911.

爱教书的郑爷爷-123作业

一链通科技依托自主研发运营的“数字化综合物流交易平台”,以内外贸集装箱海运自营产品为核心,为行业、客户及合作伙伴降低成本、提高效率、提升服务、创造价值,共同构建数字物流生态圈。

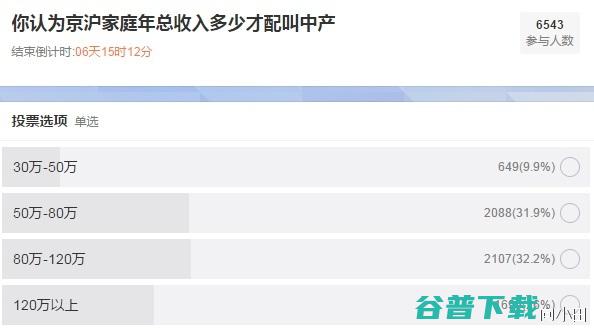
我在微博上发布了一个调查,问大家,你认为在京沪,家庭年总收入达到多少才能叫中产?截至17,10,六千多人参加投票,结果如下,微博问卷调查从这个统计来看,认为80万,120万的人最多,其次是50万,80万,认为30万,50万算中产的,比例不到10%,以我熟悉的几个微博网友的投票结果来看,收入在50,80万左右的,会投第3个选项,收入在3...。

代码说明,本页面的认证代码为橘子CPS联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在橘子CPS联盟网站首页底部或友情链接位置处,普通认证,普通联盟认证标志适用所有类型的广告联盟,能有效提升橘...。

大咖Live,人工智能与芯片专场第三期,我们邀请到了清微智能CTO欧阳鹏,带来了关于,可重构计算芯片的技术原理及实现难点,的主题直播分享,目前,本期分享音频及全文实录已上线,,AI投研邦,会员可进雷锋网,公众号,雷锋网,AI投研邦,页面免费查看,本文对这期分享进行部分要点总结及PPT整理,以帮助大家提前清晰地了解本场分享重点,分享...。

作者丨维克多困在系统中的外卖骑手正在反击,近日国外科技媒体Wired报道,平台公司利用算法迫使外卖骑手更快、更高效工作,导致了相关交通事故增多,为了应对困境,他们正在采取行动,一方面建立沟通信息的渠道分享道路等情况,例如微信群;另一方面对一些明知道不可按时送达的业务,集体拒绝,这篇报道的观点来自两位学者团队,HUANGHUI和Zizh...。

又一互联网技术,大神,投身自动驾驶行业,独家消息,原百度公司技术委员会主席、高德副总裁、美菜CTO廖若雪,加盟自动驾驶公司千挂科技,成为联合创始人之一,技术圈对廖若雪的名字并不陌生,千挂CEO、百度自动驾驶事业部前总经理陶吉更是将其形容为,天花板,级的技术大神,天花板级,技术大神2005年,百度搜索的技术团队还不到20人,北大...。

C位是英文单词center的缩写形式,意思为中央、正中心的,也就是说,站在这个位置的,都是大咖,是对一个人的肯定,在娱乐圈中,经常会有抢,C位,的情况发生,总有那些没颜色的小演员,会站在不属于自己的位置上,给很多的记者盯住,在我们照毕业照的时候,那个位置永远是班主任或是校长的,没有人敢站,也没有人敢抢,在2019年的中央电视台春节联欢...。

宝马535i的发起机参数如下,宝马535i搭载了一台3.0T直列6缸涡轮增压发起机,配合8挡手自一体变速器,最大功率为225KW,最大马力到达306PS,最大扭矩为400N·m,这款发起机在5800,6000rpm时能够到达最大功率,而在1200,5000rpm时则能够输入最大扭矩,值得一提的是,宝马F10535i所经常使用的发起机也...。

宝马1系颜色相对来说是比拟多的,重要有这几个颜色可以供大家启动选用,埃斯托蓝、曙光金、雪山白、矿石白、铂金银、地中海蓝、开士米根、星光棕、墨尔本红、勃垦地红,宝马1系颜色介绍颜色介绍的话,我团体觉得埃斯托蓝十分的大气、好看,而且与车型井水不犯河水,全体视角成果十分不错,另外,这种蓝色还有必定的降平和冷却作用,这种颜色对人的愤怒、恼恨等...。

百家号作为百度旗下的内容创作平台,一直以来都是众多自媒体人的首选。然而,有些用户在申请百家号时,可能会遇到一直处于“认证中”的情况。那么,为什么会出现这样的情况呢?首先,我们需要了解百家号的认证流程。

罗马诺:尽管错失凯恩等人,曼联对签下霍伊伦感到满意,曼联,罗马诺,霍伊伦,奥斯梅恩,英国足球,哈里·凯恩,足球运动员,俄罗斯足球,国际足球赛事

学生用留学生宿舍垃圾桶被保安怒斥

重庆分类目录网站收录外语相关的优秀网站大全分类检索,为上网用户提供外语网站排行榜与您分享、收藏!

竞技类游戏最能引发人的肾上腺素,没有人不喜欢胜利的喜悦感,尤其是在高度紧张下获得的,那么竞技游戏手游排行榜前十名2022都有什么,竞技类游戏肯定不缺,但也要认真挑选好玩的,希望小编找的这十款游戏能帮助到你,1、,自由之战,竞技类游戏自然少不了MOBA玩法,带给玩家最纯粹的竞技体验,在自由的战场上为追随而战斗,即时战斗一秒燃爆,快喊上兄...。
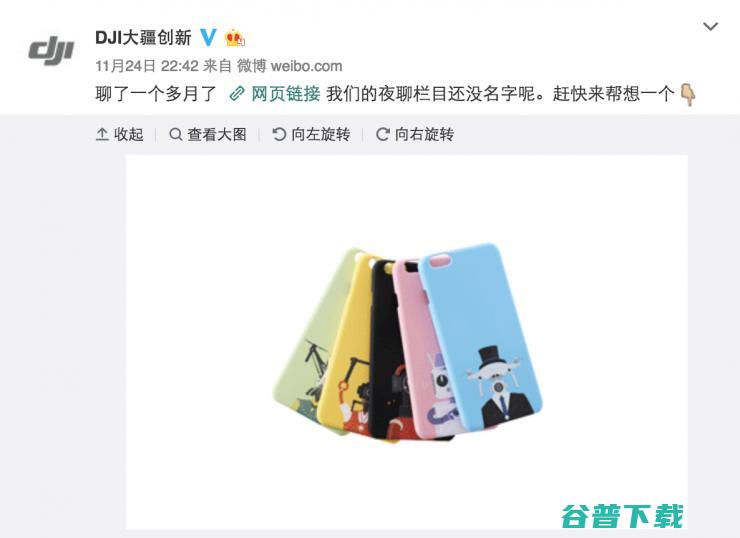
24号晚上,大疆的官微在与网友互动的时候发了一张动图,图片中有五个手机壳,手机壳上分别印了大疆精灵、悟、OSMO、Ronin,MX以及无人机遥控器的艺术形象,不少DJI的粉丝在下面留言问手机壳怎么才能得到,今天大疆给出答案了——去大疆商城买,这确实是一件让人没想到的事儿,大疆居然出周边了,雷锋网到大疆官方商城逛了一圈,发现大疆这次发的...。

1月10日晚,360集团创始人周鸿祎发微博称,1月12日将以直播形式分享,你也可以好口才——如何演讲,成功的企业家几乎都是优秀的演讲者,,周鸿祎表示,自己也有不擅演讲的时候,从马云和张朝阳身上学习了技巧,希望把知识传递下去,周鸿祎发微博称,,未来属于年轻人,特别是年轻的企业家和创业者,但我发现年轻人擅长玩流量,按照既定脚本,用剪辑...。

数字化时代,企业面临的安全威胁更加多样,而企业的安全专业人才却存在大量缺失,即便购买了安全产品,洪水般的安全告警、众多的安全产品孤岛让安全团队苦不堪言,采取怎样的安全威胁检测与响应方案,才能帮助企业提升安全运营能力,抵御潜在的网络安全风险,在此背景下,XDR为何会成为企业安全运营,热门,工具,10月26日,由国内首个XDR落地厂商未来...。

发表在知麻投影仪2023,7,2512,57知麻NEWZ1MINI是Z1MINI的升级版本,主要提升在画质方面,具体知麻NEWZ1MINI投影仪怎么样呢,下面就通过详细的参数配置来了解知麻NEWZ1MINI,看看知麻NEWZ1MINI投影仪有什么特点,是否值得用户入手,知麻NEWZ1MINI投影仪怎么样,1.光学参数在亮度方面,知麻N...。
