Adrian 挑战赛亲历者 Kaehler DARPA 自动驾驶时代的计算机视觉 (adrian怎么读)

雷锋网 · 新智驾按:1 月 16 日,由雷锋网 · 新智驾主办的 GAIR 硅谷智能驾驶峰会在美国加州 Palo Alto 如期落地。18 位中美顶尖自动驾驶行业嘉宾到场,7 场主题演讲,2 大圆桌论坛,几乎覆盖了自动驾驶相关的各个话题。 从今天起,我们将陆续放出嘉宾演讲与论坛的精华部分,并将在后续的特辑中送上整场峰会的全部内容。 该系列的第一篇,来自DARPA 挑战赛亲历者、Silicon Valley Deep Learning Group CEO Adrian Kaehler。
作为自动驾驶领域绝对的老兵, Adrian Kaehler 的职业生涯介绍理所自然更长一些,他是 Giant.AI 和非营利组织Silicon Valley Deep Learning Group 的创始人兼 CEO,担任Applied Minds副总裁和机器人与机器学习负责人 8 年,并曾在伊朗和阿富汗战争期间为 JIEDDO开发自动驾驶车辆。 2005 年,斯坦福大学的车队夺得 DARPA 挑战赛冠军,Adrian 便在其中负责计算机视觉系统的开发。
Adrian 的演讲基本以 DARPA 挑战赛为间隔,前半部分,他主要介绍了自动驾驶技术发展的几个重要节点与表现,包括 2005 年和 2007 年的 DARPA 挑战赛,计算机视觉、深度神经网络的发展,之后,Adrian 则重点谈了后DARPA 时期自动驾驶的发展。
DARPA 之前的自动驾驶
关于自动驾驶的发展起源,Adrian 直接追溯到了 15 世纪。1478 年,达·芬奇(Leonardo Da Vinci)设计出了预编程发条马车的草图,如果研发成功,这辆车就可由一个大型螺旋型发条弹簧驱动,按照预定路线实现车辆的自动驾驶。
90 年代,斯坦福的人工智能实验车(Stanford Cart)率先使用人工智能和机器视觉进行了陌生环境的导航。当时,激光雷达非常昂贵,并没有在自动驾驶中发挥突出作用。多数研究者还是倾向于依靠摄像头和计算机视觉方案完成车辆的自动驾驶,而自动驾驶的应用也主要集中在军事领域。
转折点出现在 DARPA 挑战赛之后。

斯坦福大学的参赛车“Stanley”通过视觉进行道路识别,通过激光雷达检测短距离内的道路,并以此预测前方更远距离的路况。当时,一些其它车队也在使用视觉方案,OshkoshDefense 的“TerraMax ”就用了激光雷达和立体视觉进行障碍物识别。
2007 年 DARPA 城市挑战赛中,车辆需要展示停车、路径跟踪和车辆交互等功能,车辆视觉变得更为重要,也更广泛地出现在参赛车辆中。
我们都知道,成立于 1999 年的 Mobileye 主要聚焦于 ADAS 系统的视觉开发。他们的技术被用在了 DARPA 城市挑战赛卡耐基梅隆大学的参赛车上,并且取得了非常好的成绩。Mobileye 的早期系统可以提供车道线检测、车道偏离预警、障碍物识别和车距检测功能。2007 年,他们的产品已经用在很多商用车辆上,包括凯迪拉克的STS 和 DTS。
自动驾驶的第二阶段
2009 年,谷歌开始了自动驾驶研发,他们招揽了 DARPA 挑战赛的很多重要参与者,包括斯坦福的大量人才,而后者不依赖视觉的传统也在谷歌的自动驾驶汽车上得到了延续。不过,在很多任务执行中,摄像头仍是不可或缺的因素。
现在,激光雷达已经成为自动驾驶技术的主流,不过,仍然可以看到很多玩家使用计算机视觉方案。这之中,高昂的成本是很多人对激光雷达望而却步的重要原因。
高校的技术研究已经有了很大发展。DARPA 挑战赛之后这些年,很多研究者整合比赛中的经验,将其中的技术转化成更坚实的理论基础。在计算机视觉方面,类似 Dalal 和 Triggs “HOG”行人检测的重要算法得到改善,新技术发展,车辆识别自行车或其它物体的可靠性也在增加。

重要的数据集也在发展。2012 年,KITTI 数据集发布,它涵盖了 GPS RTK 惯性导航系统、立体摄像头、激光雷达的探测数据。惯性导航系统和激光雷达可以建立一个地面实况数据集,评估视觉算法的表现。专业的标注者则标定出重要物体(车辆、行人、自行车等)的边界框和目标物等级。这些技术都是发展立体系统、光流、三维重构、三维物体检测、三维目标追踪的重要基础。
KITTI 这类数据集的出现推动新算法更快发展,帮助其进行更高效的比对,现在很多从业者就在努力解决这方面的问题。
2012 年,“AlexNet”在一项重要的计算机视觉基准任务上战胜了其它方法,让神经网络重新回归自动驾驶的版图。并且,深度神经网络几乎打开了解决各种问题的大门,在依赖计算机视觉的年代,这些问题都被认为在几十年之内很难找到解决方案。同时,视觉方案的经济性也开始得到前所未有的重视。一个摄像头最低只要 1 美元,但一个 64 线的激光雷达却要 7 万美金。
计算机视觉和机器学习迅速探索着这项技术的边界,并不断得到新的突破,很多原本认为应该在很多年后才能取得的成果开始定期出现。
下一个主题是 SegNet 分割和Remapping。原始的SegNet 主要被用于分割,深度神经网络从场景中学习,之后再对其进行解释。
YOLO 算法目标识别也是非常重要的技术,可以识别图像中的目标,在分类的同时预测边界框。它应用了深度神经网络与传统的概率统计技术,最新版本YOLO-9k 可以识别 9000 种不同目标物。
视觉的探索没有终点。深度神经网络为很多问题提供了解决方法,Mask R-CNN 的先进算法也在提升,它将对象查找与每个对象的像素标记结合在一起,还可用于人体姿态的评估。
最后,Adrian 表示,虽然自动驾驶的问题很难在短时间内全部克服,但许多重要环节已经得到很好的解决,而这些已足够支撑这项技术投入市场。在其一直关注的计算机视觉方面,他也给出了自己的多项建议,这些建议,以及 Adrian 的 40 分钟演讲全文,雷锋网 · 新智驾都将在后续的特辑中完整送上。
原创文章,未经授权禁止转载。详情见 转载须知 。

")
一帧秒创是基于新壹大模型及秒创AIGC引擎的智能AI内容生成平台,包含AI数字人、AI帮写、AI视频、AI作画等AIGC工具,可将百家号、公众号、头条号、搜狐号、新浪微博、小红书等文章一键转视频,一键生成数字人播报视频,为企业及自媒体提供一站式视频生产,全面提升内容创作效率。

《墨鱼丸》是一款能让您在电脑端看短视频的休闲产品。你可以看到世界各地奇妙有趣的瞬间,享受工作和生活中的每一刻精彩!

台州市创源节能科技有限公司,纳米远红外电热圈,料斗节能发电器台州市创源节能科技有限公司是一家集设计、研发、生产、销售为一体的专业电转热设备生产制造商。以其“高效”节能的显著效果,广泛运用于国内外塑料加工行业。深受广大用户好评!公司地处浙东沿海现代新兴城市,被誉为中国塑胶、模具之乡的台州。地理位置由于,两、台、温高速穿越而过,距路桥机场一箭之遥,无论是贸易往来还是业务合作都十分便利。

抖音电商致力于成为用户发现并获得优价好物的首选平台。同时,抖音电商积极引入优质合作伙伴,为商家变现提供多元的选择。短视频、商家自播、主播带货,满足商家达人多形式变现需求。

成都凝华科技是一家集四川电加工设备销售安装维修于一体的厂家.公司主营四川中走丝机床,四川慢走丝机床,四川快走丝机床以及四川电火花成型机.公司业务遍布四川,重庆,贵州等地,凝华自成立以来一直致力于为用户提供规格齐全,质量优良的机床设备和专业技术指导,想要了解更多详情,欢迎来电来访!

鹰辉瓷砖属于佛山市远景陶瓷科技有限公司旗下鹰辉陶瓷品牌,鹰辉陶瓷主要生产各类瓷砖,经过多年的发展,产品品质优良、远销全国各地,深受广大消费者喜爱;贝多芬密码陶瓷立志于陶瓷市场一颗璀璨的明星,打造陶瓷行业领军先锋……

衡水云立方网络技术有限公司生产合金网兜、石笼网、镀锌覆塑格宾网、格宾笼、固滨笼、格宾石笼、铅丝笼、铅丝石笼、宾格网、宾格笼、雷诺网、雷诺护垫、加筋石笼网、重型六角网、赛克格宾网、金刚水利笼箱,折叠应急金属网箱水利工程用钢丝网及各种护栏网等铁丝网产品。欢迎咨询:19033280365.

中国当代徽商精英协作网将本着“创新、务实、价值、责任”的原则,以“凝聚一切可以凝聚的徽商精英力量,帮助一切可能帮助的徽商新兴群体”为宗旨,以“广泛传承和弘扬徽商精神,大力宣传徽商名人名企,深度报道江淮风情物产,全面服务安徽经济发展”为己任,积极为广大会员提供尽善尽美的服务,力争将其打造成为一个沟通海内外徽商精英群体的切实平台而奋斗!

产品广泛应用于电子、机械、汽车、医疗器械配件等行业

风云社官方网站

哈弗SUV官网,提供最新的二代哈弗H9,新一代哈弗H6,哈弗H6经典版,2024款哈弗猛龙,新哈弗H5,2024款哈弗大狗,哈弗枭龙MAX,哈弗枭龙,哈弗二代大狗PHEV,哈弗二代大狗,哈弗M6PLUS,哈弗H6国潮版全系车型官方报价,图片,视频,销售商查询,预约试驾,产品说明书等服务。

成都九龙医院-专业呵护如家般感觉在这里让你感受家的温馨和亲人般的关怀,我们营造的,不仅仅是一家医疗场所,更注重营造一种和谐的氛围;因为用心,我们博得挚爱,让我们在爱的世界里徜徉。


不知何时起非对称对抗游戏成为了主流的游戏,游戏中有两种不同的玩家群体,每个群体的玩家都有着特殊的使命,那么好玩的非对称对抗游戏有哪些?非对称对抗游戏是超级流行的,这样的游戏可以锻炼玩家的神经反应速度,没玩过非对称对抗游戏的小伙伴快来看看下文吧,1、,躲猫猫,这款角色可爱的动物类游戏有个非对称的玩法,就是一对三十九的生存类模式,这个生存...。
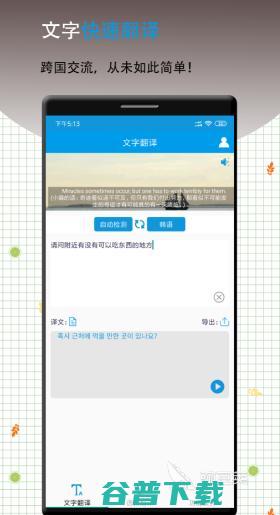
英语翻译软件哪个好用是大家近期比较关注的问题,在看一些外刊或者是生活中经常会遇到一些不认识的英语单词,从前获取还需要我们自己去购买寻找词典进行查询,现在其实利用一些手机软件就能够快速进行翻译,而且还能够运用于多种使用场景中,今天小编精挑细选了几款好用的手机翻译工具,感兴趣的小伙伴不妨接着往下看,1、,中英互译官,带有强大的文本翻译功能...。

同样的食材采用不同的烹饪方式制作,所呈现出来的味道与风味与众不同,迎合不同人群的味蕾,石锅菜是比较有特色的一类菜品,以特色材质的石锅为烹饪工具,烹饪出来的菜品营养丰富,色香味俱全,口感新鲜,赢得广大消费者的喜爱与好评,于记石锅菜是一个专注于石锅菜经营的连锁品牌,凭借优于同行的产品优势,在市场中占有重要的经营位置,随着品牌的热度持续不断...。

近日,中国创业投资机构启明创投宣布正式完成第七期人民币基金的募集,保险机构、知名市场化母基金、领先的上市公司及国有企业、地方政府引导基金等均有出资,基金规模达到65亿人民币,成为2023年迄今为止中国创投市场最大规模的人民币基金募资,回顾历史,启明创投于2006年成立,先后在上海、北京、苏州、香港,西雅图、波士顿和旧金山湾区设立办公室...。

雷锋网消息,苹果将成立一个新的AI,ML团队,将其核心的CoreML和Siri团队合并,由JohnGiannandrea统一领导,并直接向TimCook汇报工作,据TechCrunch报道,合并后,CoreML和Siri团队内部结构仍保持不变,合并后的团队将维持与开发者工具、地图、CoreOS等各个项目互相整合的状态,苹果于美国当地时...。

最新方法怎么看电视台,只需要在电视上装一个当贝市场就可以轻松解决,1、下载当贝市场,http,www.dangbei.com,安装包并拷贝到U盘,2、打开东芝电视,按下遥控器的设置键,打开设置界面,点击,更多设置,3、在设置界面找到,通用,选择,商场模式,,把商场模式改为,开启,状态,4、成功开启以后,把U盘接到电视的USB接口...。

现在很多孩子不喜欢吃饭,可能做的不符合自己胃口,看起来没有食欲,所以在吃饭方面大部分家长都非常烦恼,孩子不好好吃饭对身体就起到很大的影响,不能在食物中获得更多营养,所以家长比较操心,大部分家长为了想方设法让孩子吃饭,经常会带孩子到亲子餐厅内体验,近几年来亲子餐厅就非常受欢迎,也出现了很多品牌,大家如果感兴趣可以来了解一下亲子餐厅加盟店...。

日前,备受瞩目的醉品集团·茶叶品牌战略联盟新品发布,订货,会很好落幕,据了解,这是该联盟以品牌集群的形式亮相并联合发布新品,在此次订货会上,订货金额突破300万元,而这也成为茶界热议的一件大事,本次订货会汇聚了各大品类品牌代表,作为武夷岩茶的标杆品牌,曦瓜大红袍亦是位列其中,一直以来,香江茶业始终坚持,以茶带旅,以旅促茶,,,曦瓜,香...。

文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为骆驼网站联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在骆驼网站联盟网站首页底部或友情链接位...。

总运指数,★★☆☆☆运势动摇大,上半月心情不稳固,阴晴难料,容易因他人话语心生嫌隙,心境抑郁难展颜,下半月运势稍有好转,愤愤不平时能想明确许多事件,但情感方面疑问不小,事件辣手需细心琢磨,爱情指数,★★★☆☆单人爱情际遇,桃花漫天却需细心分辨,上半月独身者同性缘虽好,但却是心意似流水,真正能入你眼的人少之又少,既然缘分未到,就请耐烦期...。

型号是WSSM2C202AA,理论状况下须要每两年或每行驶12万公里改换一次性智能变速箱油,不过也要因车型而定,不同的车型要求是不一样的,智能变速箱油不能经过应用大气压力齐全排放洁净,而只能排放出废油量的1,2左右,剩余的油液会与油泥、杂质等汇集在阀体、变矩器及冷却管路中,形成系统外部油路的梗塞,裁减资料,经过CVVT和,Eco,dr...。

一个专业的数据恢复技术员对于winhex一个并不陌生,winhex是一款专业的十六进制编辑器,它能够解决各种文件数据方面的紧急情况,使用软件可以诊断文件发生的各种错误问题,并且还能恢复用户不小心删除的文件,找回因文件损坏而丢失的数据等,但是
美丽的花朵是我们生活中浪漫的点缀,自然在游戏世界中也会有很多与之相关的类型,这次小编就给大家带来几款2023关于花的游戏分享,这些游戏都以美丽的画面,活泼的色彩吸引着玩家的驻足,而它们也有着各种好玩的关卡任务,让玩家们在享受色彩愉悦的同时也拥有了游戏的乐趣,在这里你可以拥有独属于自己的美丽花园,种上各种各样的花朵,精心的培育它们,浇水...。

12月13日,谷歌透露了其街景车,StreetViewcar,等设备为绘制世界地图所做的工作,目前,谷歌已经捕获了超过1000万英里的街景图像,这个距离相当于绕地球400圈,旗下航空地图服务谷歌地球,GoogleEarth,目前拥有总计3600万平方英里的卫星图像供人们浏览,这些图像让谷歌的地图绘制覆盖了世界人口居住地区的98%,据科...。

细数耳机品牌,为人熟知的几乎全是舶来品,Beats、Sennheiser、MONSTER、铁三角、AKG,不过认知不代表真实的市场,国产耳机用低价拿下了一定份额,利润有限,空间逼仄,这就是Fiil诞生的背景,宏观地说,消费在升级,去年8月,汪峰携Fiil耳机亮相,官方口径是,Fiil的目标是做类似Beats的中国品牌,借鉴小米模式,...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。

梦见自己有意杀人的周公解梦,吉凶指数,92,由佛滔居士数理文明得出,仅供参考,梦见杀人见血,杀人象征着会发财,而梦见血也是凶兆,不用担忧,梦见自己杀人,也象征着自己的仇人太多,不是那么容易就可以化解的,梦见杀人,梦见他人杀人者,主有人送物至,大吉,见他人相杀者,主争财也,梦林玄解,梦见自己有意杀人,情感方面往往自认为是!当天的你,往...。
