2020挑战中学到了什么 Twitter从Recsys (2020挑战杯承办学校)
译者:AI研习社( 听风1996 )
双语原文链接: What Twitter learned from the Recsys 2020 Challenge
ecommender系统是现代社交网络和电子商务平台的重要组成部分。它们旨在最大限度地提高用户满意度以及其他重要的商业目标。与此同时,在以根据用户兴趣定制内容为目的来建立新模型基准测试时,缺乏供学界研究使用的大规模的公共社交网络数据集。而在过去的一年里,我们努力解决了这个问题。
Twitter与RecSys会议展开合作以支持2020挑战赛。在两周的时间里,我们发布了一个包含推文和用户参与度组成的数据集,其中有1.6亿条公开推文用于训练,4000万条公开推文用于验证和测试。
在这篇文章中,我们描述了数据集以及Nvidia、Learner和Wantely团队提交的三个获奖作品。我们试图对帮助获奖者取得成绩的选择做出一般性的结论,特别是:
以最快的实验速度用于特征选择和模型训练
我们希望这些研究结果对更广泛的研究界有用,并启发推荐系统的未来研究方向。
挑战赛的参与者被要求预测用户参与四种互动中任何一种互动的可能性:赞、回复、转发和引用tweet。我们根据以下两个指标对提交的作品进行评估:相对于我们所提供的简单基准方法的相对交叉熵(RCE),以及Precision-Recall曲线下的面积(PR-AUC)。
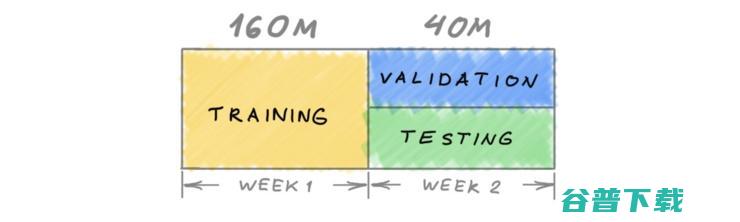
随时间的变化的训练、测试和验证数据集的表示
我们要特别注意(我们所使用的)维持数据集需与Twitter平台同步。数据集反映了平台上的变化,例如,当其中的一条推文被删除,有用户将其个人资料变为私有或完全删除。所以提交的数据就会被重新评估,排行榜也会根据重新计算的指标进行更新[2]。
数据集的特征表示。它们分为用户特征(针对作者和读者)、推文特征和参与度特征。
今年的挑战赛竞争尤为激烈,注册用户超过1000人。在整个挑战过程中,参赛者积极提交解决方案,并在挑战的第一阶段(根据提交指南)修改了他们的团队组成。最后阶段有20个竞争者,平均团队规模为4名成员。此外,各队总计设计了127种不同的方法,来尝试赢得挑战比赛。在整个挑战过程中,参赛者的活跃度很高,在最后几天,参赛者对提交的作品进行了改进,达到了做最优性能。最终的结果出现在排行榜上。
与之相伴的RecSys Challenge 2020研讨会收到了12篇论文,程序委员会对这些论文进行了审阅。其中9篇论文被接受。

数据集的特征表示。它们分为用户特征(针对作者和读者)、推文特征和参与度特征。
今年的挑战赛竞争尤为激烈,注册用户超过1000人。在整个挑战过程中,参赛者积极提交解决方案,并在挑战的第一阶段(根据提交指南)修改了他们的团队组成。最后阶段有20个竞争者,平均团队规模为4名成员。此外,各队总计设计了127种不同的方法,来尝试赢得挑战比赛。在整个挑战过程中,参赛者的活跃度很高,在最后几天,参赛者对提交的作品进行了改进,达到了做最优性能。最终的结果出现在排行榜上。
与之相伴的RecSys Challenge 2020研讨会收到了12篇论文,程序委员会对这些论文进行了审阅。其中9篇论文被接受。
GPU Accelerated Feature Engineering and Training for Recommender Systems.
Nvidia的论文[3]描述了训练xgboost模型来预测每个交互事件。总体的关注点在于为该模型生成有用的特征。文章强调快速提取特征和模型训练是该方法成功的关键。本文在附录中提供了4种模型中每种模型的15个最有用的特征列表。
从数据集中快速提取特征并进行再训练是冠军和亚军的关键区别。特征工程流程和训练流程的运行时间都不到一分钟。除此之外,对不同的分类特征和特征组合采用目标编码(均值编码+加法平滑),包括这些组合的目标均值。作者还从推文的内容中创建了分类特征(如最受欢迎的两个词和最不受欢迎的两个词)。用于特征重要性评估和选择的对抗性验证通过选择更通用的特征来防止过拟合。 采用基于树模型的集成方法用于生成最终模型。
第二名:Learner
Predicting Twitter Engagement With Deep Language Models.
Learner[4]融合了深度学习与梯度提升决策树(GBDT),并专注于不同特征的创建。作者使用启发式方法设计了467个特征,并使用BERT和XLM-R生成了推文的文本表示(同时使用了目标Twitter文本以及最近参与的Twitter文本)。
该条目与其他条目的关键区别在于使用了预训练的自然语言处理(NLP)模型BERT和XLM-R,并进行了微调。第一层的微调是以无监督的方式进行的。接下来,将语言模型与其他特征结合以有监督的方式进行微调。。该模型是一个多层感知机(MLP),有四个头,每个头代表一种参与类。本文还引入注意力机制生成了用户过去十次互动的嵌入向量。以目标推文为关键,利用注意力机制对每个的嵌入向量进行组合。此外,还使用了启发式特征,如参与用户、推文创建者、推文特征和用户与创建者交互特征的不同表示。与其他条目一样,本文使用xgboost进行特征工程和选择,并将Yeo-Johnson transformation应用于分类特征和非标准化连续特征。
第三名:Wantely
A Stacking Ensemble Model for Prediction of Multi-type Tweet Engagements.
上游的通用模型生成下游模型所需的特征。作者认为,通过这样的方式,每种参与类型的下游模型都可以从所有其他参与的数据中受益。除此之外,除此之外,如Nvidia条目所示,本文通过对抗性验证直接评估训练和测试数据集之间的特征分布差异,从而确定了哪些特征是可通用的。
在所有提交的论文中,有许多相同的见解。我们重点介绍以下主题:
胜出模型中使用的有用特征—目标编码是王道。 首先,目标编码(用目标变量的平均值替换分类变量)使问题变得更简单。它同时用于用户和作者id,因此编码了用户的平均参与率。其次,使用了大量特征交叉[6]。
快速实验进行特征选择。 快速检验许多假设的能力一直是数据科学竞赛中不可或缺的一部分,并再次证明在这一挑战中具有决定性作用。Nvidia团队能够在GPU上运行整个流程。这让他们只需2分18秒就能训练出一个模型(包括特征工程),而在CPU上则需花费数小时。
通过对抗性验证来应对过度拟合。 比赛选手常用的一种技术是建立一个判别器来预测训练和测试/验证集之间的差异。根据模型选择特征时使用的重要性分数,通过去除最重要的特征,可以帮助模型更好地泛化。此技术有助于避免训练数据过拟合。
上下文特征的使用。 今年的数据集和之前的数据集的一个重要区别是我们提供的上下文特征。在三篇获奖论文中,有两篇对基于上下文特征的BERT进行了复杂的使用。NLP中的深度学习方法已经证明了它对推荐系统的有用性,尽管我们认为在这个领域还有更多的改进空间。
决策树与深度学习。 梯度增强决策树(GBDT)的一个显著优势是,无需对单个特征的尺度进行归一化和计算。这使得所有胜出论文的迭代速度更快。
在计算机视觉和NLP等领域,深度学习模型已经通过利用CNNs和transfomer展示了令人印象深刻的进展。基于这一挑战的结果,我们仍然不明白在推荐系统中什么构成良好的深度学习架构。我们呼吁研究界共同寻找推荐器系统的最佳深度学习架构。
我们也注意到,虽然我们只对提交的模型的性能进行了评估,但在生产系统中还有许多其他限制。对我们来说,延迟是一个大问题:模型需要在毫秒内对推文进行评分。在这种情况下,需要仔细检查集成方法的使用。集成中每一步的附加延迟都可能会导致它们对我们的目标来说太慢。
我们感谢所有参与者和我们的同事使这得一挑战成为可能。我们相信,发布大规模数据集将有助于解锁推荐系统领域的新进展。Twitter现在比以往任何时候都致力于帮助外部研究,并且最近为学术研究人员发布了新的API端口,以帮助促进进一步的探索和合作。
[1] J. Pan et al.Adversarial validation approach to concept drift problem in user targeting automation systems at Uber(2020) arXiv:2004.03045. Introduces adversarial validation, a powerful technique used by several participants.
[2] L. Belli et al.Privacy-Aware Recommender Systems Challenge on Twitter’s Home Timeline(2020) arXiv:2004.13715 provides the details about the challenge and the>AI研习社是AI学术青年和AI开发者技术交流的在线社区。我们与高校、学术机构和产业界合作,通过提供学习、实战和求职服务,为AI学术青年和开发者的交流互助和职业发展打造一站式平台,致力成为中国最大的科技创新人才聚集地。
如果,你也是位热爱分享的AI爱好者。欢迎与译站一起,学习新知,分享成长。

版权文章,未经授权禁止转载。详情见 转载须知 。


有限公司")
快邮供应链管理(深圳)有限公司原名深圳快点国际物流有限公司成立于2015年,注册资金500万,是经国家商务部批准的国际货运代理企业。

宁波代喂宠物,上门铲屎,猫咪寄养,长期接单上门喂养宠物,全程视频安全放心,寻猫寻狗,宁波找猫服务,宁波找狗服务,钟女士13777272074

希子网是国内会计信息,会计相关资讯的信息网站

山西临汾侯马+山西智科信房产地产有限公司+房地产开发+金域蓝湾+金域小区+晋瑞驿都,智科信地产_山西临汾侯马+房地产开发/金域蓝湾/晋瑞驿都,侯马房地产,侯马,侯马世纪广场,侯马优质房源,金域蓝湾,侯马金域蓝湾

象牙白网络营销官网红书短视频推广一站式媒体公关传播服务 提供网络推广服务,包括kol达人推广、素人推广、红书推广、短视频推广等一站式媒体公关传播服务

山东科辰机械有限公司位于全国着名的食品机械生产基地——山东诸城市,东临奥运城市青岛,南靠海城日照,北临风筝之都潍坊。公司拥能为广大企业车间提供工艺设计、安装调试、技术培训、产品开发、技术改造等服务,是一个集科研、制造、销售于一体的不锈钢食品机械生产企业。

一个好听、独特且易于记忆的名字能够让人在第一次听到时就留下深刻的印象,名字往往能够反映出一个人的性格特点和气质。一个好听的名字可以巧妙地传达出个人的独特性和魅力,使人在未见其人时就能对其产生一定的了解和期待。

河南彬豫强夯地基基础工程有限公司经理专线:15039025678公司全国承接,1000KNm—25000KNM强夯施工,强夯置换施工,sddc施工,灰土挤密桩施工,灌注桩施工,CFG施工。

诸城市诚友机械科技有限公司主要以生产食品机械设备为主,业务客户遍布全国各地大中小城市及国外用户。经过多年的发展,现已成为集研发、生产、销售于一体的食品机械实力型生产企业。 我公司开发、制造的蔬菜清洗机、风干机、巴氏杀菌机、真空滚揉机、斩拌机、行星搅拌炒锅、夹层锅、真空包装机等设备。以结构独特、造型美观、制作精良、技术先进等特点,而且公司不断自我技术提升,完善产品的功能和质量,深受广大客户的好评。

引领右脑创立于2008年,是一家以全脑教育思维为核心的教育服务公司。秉承“点亮孩子的智慧之光”为使命,为中国家庭提供科学育儿服务。

重庆典名科技是一家值得信赖的阿里云代理商,专注于提供高质量的阿里云服务器和阿里云数据库解决方案。我们致力于帮助客户搭建可靠、安全、高效的云计算基础设施。

湖南汽车网是湖南省地区的汽车网站,深得车友喜爱。湖南汽车报价栏目实时更新汽车报价、汽车优惠信息、汽车行情。湖南汽车网发布的报价信息是汽车新报价。请您支持湖南汽车网。

新一轮大学英语四六级考试在即,支付宝在今天下午宣布为广大备战大学英语四六级考生准备了一份,英语四六级,保险,只要你安装了新版支付宝,在支付宝主界面banner上点击便可免费领取,支付宝方面表示此项保险为众安保险在支付宝,校园生活里给广大考生限量提供100万份考试险,在新版支付宝,校园生活中认证过的在校生都可以免费领取,领取这份保险的同...。

4月12月,在2018年中国互联网,数字经济峰会上,以,云上政务,普惠民主,为主题的云计算分论坛在下午举行;由此可知,在互联网,的维度下,本次云计算分论坛的核心着力点还是政务领域,在论坛中,腾讯云副总裁谢岳峰表示,腾讯云在智慧政务方面积极推进,致力于,数据多跑路,群众少跑腿,,在多个方面都有进展,目前,目前腾讯云政务云官方用于四川省人...。

发表在综合交流大区2022,5,1611,14小红蜂投影仪是一款拥有可爱外表以及超低价格的微型卧室投影仪,较低的价格也使得这款小红蜂投影仪在市面上的销量也颇高,入门级选手选择较多,大家都想在不花大价钱的基础上去增添生活的情趣,那这款小红蜂投影仪怎么样呢,这么便宜的投影仪究竟好不好用呢,这篇我们就小红蜂投影仪的参数配置一起来看看这款投影...。

发表在当贝投影仪2024,11,1216,59当贝Smart1是当贝最新发布的便携式投影仪,支持调整投影画面亮度,具体当贝Smart1怎么调整画面亮度呢,下面就分享当贝Smart1调整画面亮度的详细方法,看看实际该怎么操作,当贝Smart1怎么调整画面亮度,1.打开投影设置在当贝Smart1的主界面选择设置并点击打开;2.进入图像设置...。

网易文娱3月30日报道由西方卫视打造的全国首档音乐厂牌反抗秀,金曲青春,今天颁布了一封,招集令,,正式官宣首轮介入竞演的六大家族——创家族、醒悟西方家族、酷漾家族、丝芭家族、索尼音乐家族、乐华家族,以及各自的家族担当,他们将以家族反抗的方式,经过对华语盛行金曲的全新改编归结,率领观众在音乐的长河里畅游,见证金曲蓬勃的生命力,六大家族初...。

国足裁员进入倒计时!4人无缘出战日本伊万已有答案,伊万,王雷,韩鹏,日本,刘殿座,颜骏凌,国足名单
荷包plus乱不要钱,忽悠我办机子,说298的秒到费,用3年,结果用完一年,又要收60的流量费,如今市场上那么多机子,就素来没有据说过机子要收钱的,找他们切实,说是秒到费,什么鬼,只不过是变像的收钱,收了298跟我说可以用3年.一年以后又给我收60.这个公司就是遇到生产者,诈骗生产者,需要退机子费298...。

1、影迷大院介绍影迷大院,这款软件有新电影、电视剧、综艺全都是不要钱观看,而且是高清,版权商的防盗链水平也在提高,像此类网站往往就是盛极而衰,2、橙色电视橙色电视是目前十分好用的一款专一于看电视直播的一款手机APP,电视直播的画质十分的好,左右切换可以改换不同类型的频道,是看电视必备的手机APP,3、大象影视大象影视不只可以观看电视直...。

作为一款十分具备竞争力的紧凑型轿车,西风悦达起亚K3车型在市场上备受注目,那么,它的体现又是如何呢,接上去,咱们将会对其启动一番具体评测,首先,咱们来看看西风悦达起亚K3的外观设计,从前脸开局,该车驳回了起亚家族式的设计言语,行进气格栅显得十分粗劣,并配有流线型的大灯组,全体看起来十分时兴,车身正面线条流利,低矮的车顶线条感剧烈,彰显...。

抖音短视频极速版赚钱领现金app是字节跳动推出的刷短视频赚钱软件,还能领红包,用户下载安装后,可以通过app拍摄各种有趣的视频,剪辑配音等一键搞定,秒变大片,使用又方便,记录生活好友活动等多种功能,并且软件也新增了许多新的功能。发布作品,其他用户浏览就

天檀:节后大盘能否迎来小惊喜?_天檀FB_新浪博客,天檀FB,

联想synaptics触摸板驱动是一款功能强大的通用笔记本触摸板驱动程序,支持大多数的笔记本型号,安装了这款驱动能够自定义触摸板的滑动速率、摩擦系数等参数,让设备的使用更加便捷。软件能够丰富联想触摸板的功能,提升用户的使用体验。

315到来之际,2015年曾经曝料在京东上买到烂水果却得不到妥善处理的女作家六六,再次将炮口对准了京东,引发新一轮撕X,六六通过个人微博、微信,公开发表,无赖京东,一文,称在京东全球购平台上购买了美国ComfortU护腰枕,标价人民币1489元,美国官网售价109.95美元,但收到的产品标识却是ContourU,美国官网售价近33.6...。

说到废品处理,特别是厨房废品的处理,现在很多的城市已经实行废品分类了,每次扔废品的时候更是令人头大,剩菜剩饭、瓜果皮屑,分为干废品、湿废品、有害废品、可回收废品等很多种类,真的是每一次扔废品都是一大挑战,今天小编为大家介绍一下,格莱佳厨房废品处理加盟,让品质生活走进千家万户,希望大家能够对于格莱佳厨房废品处理器有一些简单的了解,大家都...。

AI没有走向低潮,而是在催生大量的应用,但大量的AI的应用非常场景化,既需要成熟的CPU和GPU,也需要全新的AI处理器,IPU,IntelligenceProcessingUnit,就是一种为AI计算而生的革命性架构,如今,IPU已经在金融、医疗、电信、机器人、云和互联网等领域取得成效,随着英国初创公司的Graphcore的IPU在...。

医疗AI的商业化,创新技术的应用化,,无疑成为2021年医疗行业的高频词汇,近日,第六届全球人工智能与机器人大会,GAIR2021,在深圳正式启幕,140余位产学领袖、30位Fellow聚首,从AI技术、产品、行业、人文、组织等维度切入,以理性分析与感性洞察为轴,共同攀登人工智能与数字化的浪潮之巅,在医疗科技高峰论坛上,中华医学会放...。

发表在峰米投影仪2021,11,317,18最近有网友在询问,峰米激光电视怎么连接米家App,峰米激光电视和投影仪产品是都可以与小米米家进行连接的,峰米vogue、峰米R1还有小明Q1都可以连接;下面就分享一下峰米激光电视连接米家App的方法,只需要简单四步即可连接成功,峰米激光电视怎么连接米家App1.通过启动台或者菜单键进入设置,...。
