居然能用自创的语言来生成图像 AI模型的可解释性再一次暴露短板 太魔幻了!DALL·E 2 (可以自己创作)
all·E 2 居然能用自创的语言来生成图像,AI模型的可解释性再一次暴露短板" src="http://www.gpxz.com/zdmsl_image/article/20241203222519_35631.jpg" loading="lazy">

来自德克萨斯大学奥斯汀分校的博士生Giannis Daras 和 Alexandros G. Dimakis教授,发现 DALLE-2背后竟然有一套秘密语言,模型内部似乎有一套隐藏的词汇表,从这些隐藏的词汇中,模型会学习一些单词,并创造一些荒谬的文本提示来生成图像。


DALL·E-2 的秘密语言






-它的语言模型是来自CLIP,所以问题一定是来自那个模型。
-我的理解是,它只在图像上进行训练,对吧?它用文本描述对图像进行编码,但它实际上从未 “看到 ”文本描述,除非图像中恰好有文本。
-任何被索引到文本描述的图像文本(或图像文本的插值)都不会只是随机的胡言乱语,这很有道理。有趣的是它如何对语言概念本身进行索引,以及它将它们混合在一起的能力。就像人类对语言的使用一样。
剥其机理




安全性和可解释性的挑战


原创文章,未经授权禁止转载。详情见 转载须知 。



DrugFuture药物在线是广泛、专业的药物信息提供平台。聚焦于全球药物研发信息,提供药物信息资讯、药物科学数据库、药物开发资源共享、专利信息检索下载等。

搜了网(51sole.com)专注于为企业用户提供B2B市场行情,热点采购、加工批发,产品信息,黄金商铺,网上推广等,是企业进行电子商务和网上推广的首选行业门户,聪明的老板上搜了网!

自助游景点攻略网是一个包含各种旅游景点大全、旅游景点排行、旅游攻略游记、游玩路线、景点美食、购物娱乐等全方位的综合旅游网站,以一个旅游者的视角和方式来畅游世界。

灵动AI,超级好用的在线设计工具,商家或者设计小白都能轻松上手快速出图。提供海量精美模板和素材,适用于美妆、快消、3C、家电、家装等产品品类。可以输出电商主图、电商海报、商品视频等营销物料,拥有横版、竖版和方形尺寸,适配各种用途。

公司始创于2016年6月22日,注册资金6000万人民币,专业从事钢丝网骨架塑胶(聚乙烯)复合管的研发、生产、销售、安装服务的现代化高科技术产业。主导产品钢丝网骨架塑胶(聚乙烯)复合管以其特有的防腐蚀、耐磨、耐高温、抗严寒、耐压、抗蠕变、稳定性好、安装方便等特点逐步取代各类金属管道和塑料管道,被广泛应用于石油、化工、燃气、供水、采矿、海水输送等领域。

我爱网是提供专业的花木市场前沿资讯,绿化苗木价格行情,花木技术文摘,花木企业动态,花木品种手册,花木展会,苗木采购,苗木供应,花木人物访谈等,是中国农业百强网站,园艺林业类十强网站,为各大企业提供网上贸易机会。

上海科技成果转化促进会官网|知识产品采购中心--阐释技术转移理念、传递科技成果资讯、搭建投资促进平台、专营知识产权高新技术项目科技成果转化的技术转移与科技中介和招商引资产业集群产业转移信息服务平台

山东耀森照明工程有限公司

【配修之家】在2024年12月9日19时更新,成立于2015年,国内专业的空调维修平台,成立至今已服务数万家电维修客户,深受商家好评,任何人都可搜索“配修之家”进入本站。3Yi

轻量、无广告水印app,拍照自动添加水印,水印包含时间、地点、天气、海拔、经纬度、具体位置、负责人、备注、桩位等等,提供多种水印模板适用于工程行业、物业行业、快消行业、酒店、第三方等等。

科客网,国内首家科技行业资讯重度垂直网站,致力于提供最快捷,最鲜活的IT产业资讯,涵盖品牌,运营商,互联网,IT,电商,数码,APP,手游业等最新信息和商业评论

途途课堂为6-15岁学生提供小学至初中的在线课程,采用双师模式结合直播授课与辅导。利用大数据和人工智能,不断优化课程内容,提升学习效率,致力于普及优质教育。名师出高徒,向上有途途。


微信支付宝扫码支付已经成为常态,尽管这种支付方式有众多便捷性,但在部分场景下安全性难以保证,央行已经下发通知,用支付宝、微信等应用扫码付款将正式迎来额度限制,据央视报道,中国人民银行发布,中国人民银行关于印发的通知,下简称,通知,,配套印发了,条码支付安全技术规范,试行,和,条码支付受理终端技术规范,试行,,自2018年4月1...。

微信小游戏跳一跳持续火爆,马上就要过年了,是不是准备和亲朋好友PK一番?现在,跳一跳又加入了新的玩法,支持多人同时游戏,PK更加方便,点击小游戏,跳一跳,的首页,多人游戏,,并,邀请好友,,发到微信群,而群内好友点击邀请卡片加入,房间,,就能一起跳了,游戏可以选择低、中、高三种难度,支持2,10人同时玩,每次每人跳一步,轮到谁跳谁就开...。

教育项目众多,但是在任何的教育项目发展中,早教是非常重要的一种,但是早教项目的研究和发展,也已经研究出亲子托育教育项目是非常有发展特色的,也是现在行业发展中的重点方向,因为亲子托育可以提高孩子们的学习基础,也可以增加亲子之间的互动,更是让一些年轻的父母们学会如何培养孩子,贝斯缇尔亲子托育是现在行业中有名的托育品牌,所以人们想要知道贝斯...。

便当是现在年轻人喜欢的一道美食,比较节省时间,同时也可以吃的有营养,吃的丰富,很多的门店在销售不同味道的便当,各种的营养都可以展示出来,对现代人的营养需求达到了均衡,好先生便当在当下很有名气,无时无刻为顾客们服务,当然,成功的路上也得到多数创业者的期待,但是,大家更多的还是想了解,好先生便当加盟靠谱吗,下面小编将从几个方面具体分析一下...。

在Facebook与Luxottica的首款智能眼镜合作产品Ray,BanStories发布后,Facebook硬件业务负责人AndrewBosworth周五在与EssilorLuxottica的首席可穿戴设备官RoccoBasilico交谈时表示,拍照功能将在十年内成为智能眼镜的标准配置,显而易见,他想要突出Ray,Ban智能眼镜可...。

2012年的龙年,高通旗舰移动平台Snapdragon系列有了中文名——骁龙,12年后的龙年,骁龙移动平台已经占据了旗舰和高端手机市场的主要份额,全球采用骁龙移动平台的智能手机数已累计达到19亿,进入生成式AI时代,AI性能也已经成为了骁龙移动平台提升的重点,继去年推出第三代骁龙8之后,高通又推出了第三代骁龙8s,骁龙8系旗舰移动平...。

免拆机破解安装第三方软件教程,方法一、固件下载地址,点我打开ZNDS论坛发布很多利用悟空遥控器app,就能给其他的型号的盒子安装过第三方APP,有的人试过,后面发现连接不了盒子的ip地址,但是别忘记了,悟空遥控器是需要,盒子,和,手机,处于同一个,局域网,下面进入主题,1.拔出移动盒子的网线;2.用移动盒子的遥控器,点击设置按钮,进...。
终身收费追剧app大全,哪些软件是咱们想要的呢,上方深空小编就跟您介绍几款比拟适合的软件或许app给您参考,1.美剧追剧软件类型,安卓APP软件引见,美剧追剧app是一款高清字幕影视app,美剧追剧app中有很多精彩纷呈的美剧均是时下受欢迎受欢迎的美剧,领有美剧追剧app不用找各种各样网盘资源,只需美剧追剧app一款手机软件2.追剧大...。

据我了解2023年最新电影有,1、,涉过愤怒的海,是由曹保平执导,黄渤、周迅领衔主演的立功悬疑电影,黄渤在片中的体现值得等候,而这部电影的悬疑剧情也让人对它的票房前景充溢等候,2、,安如泰山,这部电影由张艺谋执导,雷佳音、张国立、于和伟、周冬雨等主演,3、,河边的失误,这部电影改编自余华的同名小说,由魏书钧执导,朱一龙领衔主演,...。

乐教乐学学生版,乐教乐学学生版,乐教乐学帮助你释放才艺,乐教乐学数字校园解决方案集学校管理、教育、教学、测评、校园安全、家校共育等应用功能于一体,以云服务为基础、以软件应用为核心、以智慧硬件为辅助,帮助学校进一步建设更高效、更智能、更有用的数字校园,您可以免费下载。

极速PDF编辑器,极速PDF编辑器是一款简单好用的编辑器。极速pdf编辑器支持一键段落编辑,告别繁琐费时的行间编辑,省时省力,相信会是你需要的那款编辑器哦,您可以免费下载。

抖音PC客户端,万众瞩目的抖音PC版官方已经正式上线了,本站第一时间提供抖音官方PC客户端下载,电脑刷视频大屏更过瘾!抖音电脑版让每一个人看见并连接更大的世界,鼓励表达、沟通和记录,激发创造,快来下载尝鲜抖音PC版吧,您可以免费下载。
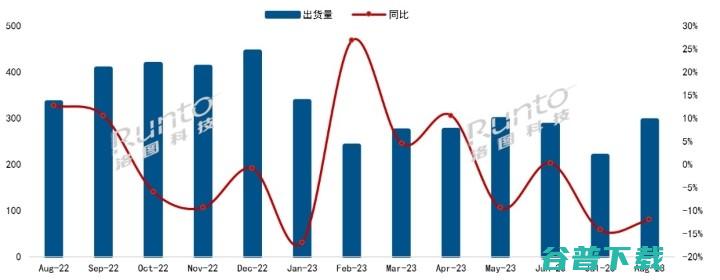
根据洛图科技,RUNTO,发布的,中国电视市场品牌出货月度快报,ChinaTVMarketBrandShipmentMonthlyExpress,数据显示,2023年8月,中国电视市场进入传统备货期,环比大幅增长34.7%;但仍远不及去年,同比下降11.9%,连续13个月中国电视市场品牌出货月度走势数据来源,洛图科技,RUNTO,,...。

美味花甲粉是很多年轻人喜欢吃的小吃,不仅拥有美好的口感,而且还会散发出醇厚的味道,吸引越来越多的人群进店品尝,现如今花甲粉的品牌门店多种多样,每一家都拥有不同的特色,但是一直深受消费者喜爱的就是幸福加贝花甲粉,因为花甲粉的口味比较纯正,同时品牌也在发展连锁加盟,可以很好的帮助创业者快速的实现梦想,那么现在加盟幸福加贝花甲粉创业享受哪些...。

在浩瀚的语言海洋中,有一个小小的后缀,它如同一位魔法师,轻轻一挥魔杖,就能让平凡的词汇焕发出全新的生命力,这个神奇的后缀,就是er,它不仅是英语语法中的常客,更是连接我们日常生活与无限可能的桥梁,今天,就让我们一起踏上一段探索er的奇妙之旅,看看它如何在不同的语境中展现出千变万化的魅力,日常生活中的er想象一下,清晨的第一缕阳光透过窗...。

优势,一是,所队合一,模式解决了以往基层派出所和交警相互推诿的问题,一件交通事故的引发的民事纠纷原来可能踢皮球,现在合并之后,乡镇派出所集合多警种职责,对待群众求助不再推诿扯皮,服务效率可以得到明显提升,二是,所队合一,后,整合资源,统一调度,大大缩短出警时间,避免了在处理一场事故的同时,没有多余的力量再及时赶往另一场事故现场,导致双...。
举办时间,2011,5,26,2011,5,28举办展馆,北京会议中心北京市朝阳区天辰东路7号乘车路线所属行业,绿色环保展会面积,16500平方米主办单位,洗涤用品工业协会国际贸易促进委员会轻工行业分会农业机械工业协会植保与清洗机械分会承办单位,北京创智国际会展有限公司展会规模,预计展览面积15000平方米2011国际清洁产业博览...。
