浙江大学张秉晟分享 RAM模型下的多方隐私函数评估 (浙江大学张秉坚)
IEEE x ATEC科技思享会是由专业技术学会IEEE与前沿科技探索社区ATEC联合主办的技术沙龙。邀请行业专家学者分享前沿探索和技术实践,助力数字化发展。
在万物互联的大数据时代,数据链接了我们生活的方方面面。一方面,大数据极大便利了我们的工作与生活;另一方面,数据的海量化也增加了诸多隐私信息泄露的风险与挑战。本期科技思享会邀请到了四位重磅嘉宾,共同围绕“隐私保护的前沿技术及应用”这个主题,分别从机器学习算法、通讯协议、APP及操作系统等不同层面,就隐私安全风险及技术创新应用展开讨论。
以下是浙江大学张秉晟研究员的演讲,《RAM模型下的多方隐私函数评估》。

演讲嘉宾 | 张秉晟
浙江大学百人计划研究员、国家级青年人才项目获得者、科技部重大科研项目首席科学家
《RAM模型下的多方隐私函数评估》
大家好,我是浙江大学的张秉晟。今天跟大家分享一个我们组和蚂蚁摩斯最新的合作研究成果《RAM模型下的多方隐私函数评估》。什么是RAM模型,什么是隐私函数评估?在这个Talk中我会慢慢跟大家介绍。
目的与场景

首先是目的和场景。隐私泄露的问题日益严重,也得到了越来越多人的关注,包括国家、政府和各级的地方机关。我国的大部分互联网公司都或多或少有一些需要整改的地方,也收到过国家的整改条令、约束等。上图中列举了一些隐私泄露的相关案例,其他案例在此不再一一列举。

最近,我们国家对数据安全和隐私保护的相关立法加速落地。从2012年开始到现在,我们国家相继出台了网络安全法、个人信息保护法、数据安全法等一系列法律法规。目前这些法律法规还只是比较上层的指导意见。例如在个人安全法里面提到,含有个人敏感信息的数据在通过处理不可以逆推、不可以反推出原始数据的情况下,是不受该法保护的。即它从侧面提供了一个我们对隐私计算、对数据互流互通的一个约束,数据要经过处理是不可以逆推成原始数据的。这些法律法规目前还比较上层,具体的评判标准还在制定当中。但是我们相信在不久的将来,我们这个评判标准也会越来越明确,至少现在去标识化已经有相关的标准。

去年Gartner给出了一个预测,根据预测报告:在2023年底,全球有75%的人口的个人数据将受到隐私法律的保护。到2023年底之前,全球有超过80%的公司将面临至少一项以隐私为重点的数据保护法规。到2024年,全球隐私驱动的数据保护和合规技术将突破150亿美元。到2025年,有60%的大型组织和企业,他们会通过至少一种或者多种隐私增强技术来实现数据的分析、云计算、建模制、数据的智能化处理等等。

隐私保护和数据安全的技术有很多,我们这个工作主要是属于安全多方计算的范畴。那什么是安全多方计算呢?它的英文叫Secure Multiparty Computation,它是密码学的一个重要研究分支。如果你去网上搜索什么是安全多方计算,那么你一般会找到以下这句定义:为解决一组互不信任的参与方之间在保护隐私信息以及没有可信第三方的前提下协同计算问题而提出的密码协议与理论框架。
如果你是学习密码学或者密码协议或者隐私计算的圈内人士,那我们有相关的狭义定义。在狭义定义中,安全多方计算一般可以分为两种主要的实现形式:一种是姚氏混淆电路,它主要是用于两方计算,当然也可以用于多方计算。姚氏混淆电路比较好的特点是它对布尔电路的支持非常好,这也是安全多方计算。姚期智教授是在1982年提出安全多方计算时提出的设想。现在的姚氏混淆电路经过40年的优化和改良,效率已经非常非常高了。第二种是针对布尔电路或者代数电路,我们是以秘密分享的形式来实现两方或者多方的协议。这种实现方式有什么好处?它的通信量会比姚氏混淆电路整体通信量小,但是它的通信轮次会比较多,比较适用于带宽比较小、但是延时比较少的应用场景。如果延时比较高的话还是建议用姚氏混淆电路,当然秘密分享对代数电路的支持肯定是好于姚氏混淆电路。
当然现在也有一些混合的协议,即你在同一个函数中或者同一个计算任务中,既要解决布尔电路,又要解决代数电路如何在它们之间进行转换,比如说ABY系列。广义来说,就我个人理解而言,安全多方计算可以包括密码学的一些原语,比如说全同态加密。
有人问,全同态加密和安全多方计算是什么关系?它们是不是两个不同的技术?
在我看来它们是不对等的一个比较。因为全同态加密只是一个加密的原语,这就相当于在安全多方计算里我可不可以应用例如AES加密,你说可以。在我看来,AES加密和全同态加密都是一种加密算法,而安全多方计算是一种协议、是一个更高维度的东西。安全多方计算的协议如果使用了比如说签名算法、加密算法,这个协议仍然是安全多方计算协议。所以在我个人的理解里面,安全多方计算协议即使使用了同态加密、半同态、全同态,它仍然是安全多方计算协议。在业界,因为一些要求它把基于可信硬件的安全多方计算叫做Confidential Computing(机密计算),又把联邦学习从安全多方计算中分离出来。其实联邦学习提出的时候,它并没有安全的定义。在我看来,联邦学习和安全多方计算其实也是一个不可比较的概念。因为联邦学习里面是可以应用安全多方计算技术去做一些隐私保护的事情。

我们研究这个成果的研究目的是什么呢?
我们主要是为了解决两方或者多方在比如说云计算的时候,要保护计算任务、要保护特定的算法。什么意思呢?传统的安全多方计算指你在计算的时候所有的安全多方计算参与方都会知道你要计算的是什么任务,也就是说我的算法是公开给所有的安全多方计算参与方。而我们要保护的只是数据、只是输入,只是这个计算的输入。但是对于一些应用场景,它的算法是非常重要的,比如别人的知识产权,比如DNA精准、靶向制药。例如我有一个算法,我的算法需要应用到你的DNA产生药的配方,但是我的算法不能公开给你,虽然你的DNA也是隐私保护的,但我和你做两方计算的时候你不可以得到我的算法。也就是说我有需求是保护算法,你有需求是保护输入。这个就牵扯到一个分支,这个分支一般我们在Community里面会把它称为Private Function Evaluation,我把它翻译成隐私函数评估,也就是说我们在保护输入的前提下,还要保护我们所计算的函数、我们要计算的任务。我们不可以让计算方知道在计算什么任务,即保护你的计算算法的IP。

显然这是一个安全多方计算的一个分支,也就是说它仍然是属于安全多方计算的领域。据我所知,目前传统的安全多方计算,所有商用的安全多方计算都是基于电路格式。Sort格式什么意思?也就是说你只能顺序执行,你在安全多方计算里面是不可以支持RAM计算模型的。什么叫RAM计算?RAM就是Random Access Machine。我们现在的常规电脑是冯诺依曼结构,在内存里可以随机访问或跳转Random Access。比如说你做一个Binary Search,二分搜索,你不需要scan整个MEMOry,你可以跳到你指定的位置去做读写、做比较,然后再做下一步操作。但是因为一些技术的限制,在安全多方计算里面我们现在不能做这种类似操作,我们现在只能顺序执行。而这种顺序执行会极大程度的限制我们安全多方计算可以使用的场景,比如说有一些我们需要跳转或者跳转比较多的算法就没办法高效的用安全多方计算来实现。
我们这次想要做的一个工作是在RAM模型下去实现一个Private Function Evaluation。也就是说我们这个安全多方计算系统再也不用被编译成电路就能支持RAM的计算结构。如果你有一个死循环,你有一个While Loop,甚至你的While Loop里面的Condition是一个不确定的Condition。比如说一个死循环里面,你有一个基于私密数据的隐私保护数据的条件,那么我们这个模型也能够去支持,并且我们这个模型会保护你的算法。我们的做法大致讲来是把一些高级语言(比如C++语言或者Java等)用编译器(比如用LLVM的编译器)编译成TinyRAM的指令集,为什么是TinyRAM呢?因为我们需要一个精简指令集,如果指令集太复杂了我们整个系统的开销就会非常的大。所以我们就选了一个精简指令集,TinyRAM。当然RISC-V也是可以的,我们对程序和输入都进行隐私保护。具体来说我们都进行秘密分享,我后面会一一和大家解释具体操作。
我们在程序秘密分享和数据秘密分享的前提下进行安全的执行,我们可以密态的执行。
MPC分布式ORAM
先讲一下我们构建的一个前提工作,也就是我们要构建一个分布式的ORAM。
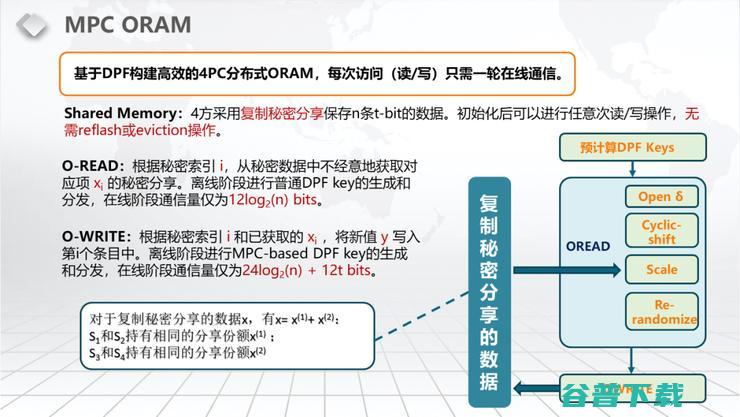
什么是分布式的ORAM呢?
传统的ORAM是讲你有一个服务器或者有多个服务器,然后有一个Client,这个Client在服务器上面进行读写,它不能让服务器知道你读写的是哪一个位置。分布式ORAM指的是我已经不存在这样的一个Client,我在安全多方计算时我要读写哪一格的位置,其实我要读写的这个数据也是隐私保护的,比如说它是以秘密分享的形式去保护的,然后在服务器上面进行读写,它也是一个分布式的结构。具体我们采用了4个服务器架构。如果你要只读的话,我们也可以做出3PC的格式。这个2PC的格式后面我们会讲,这是一个经典的PIR,但它不是标准的ORAM,它只是一个Private Information Retrieval的实现形式,主要是基于DPF(Distributed Point Function),也就是FSS(Functioning Secret Sharing)。
我们构建的这个分布式有几个特点:第一个特点,它可以进行任意次的读和写,而且读和写之间的转换是不需要Refresh、是不需要Eviction的。即我们看见的一些常见操作,可能它的读会很快,但是读转到写的过程中需要非常多的时间或者它的读写都比较快,但是它经过若干次的读写突然要进行一次Refresh或者进行一次Image,这就极大程度的限制了这些ORAM在我们这个场景中的使用。具体来说,我们的O-READ,它的通信量是12log2(n) bits,这个N就是你这个Memory大概有多少Memory的size。然后你在Memory里面取一个数,不让这个服务器知道你取哪一个数。我们需要的通信量是12倍的log2(n),然后你想oblivious去改写那个Memory,就是你在一个N个size的Memory里面,你在某一条里面想去写入一个数。比如说在i条里面写入一个数,在我们这里All Right的通信量是24倍的log2(n)加12t bits,T其实就是你要写入的这个数据的长度,具体的操作它分Open δ、Cyclic- shift、Scale、Re-randomize,稍后我会一一介绍。
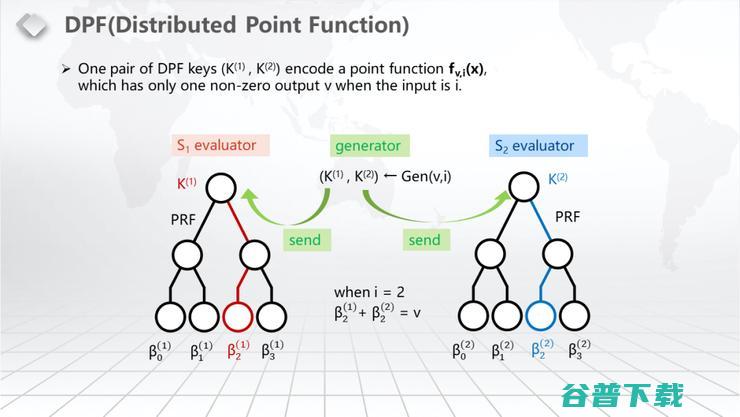
我先简单介绍一下DPF。DPF是Distributed Point Function,它最经典的构造是两方的DPF,就是有个Generate,它会Generate出两个K,这个K一方给左边,一方给右边,两个服务器S1和S2。这两个服务器分别针对这个K做Evaluate,把做出来的最后一行的从β0到β3两个东西全加起来,它其实是一个Unit vector。什么叫Unit vector?它只有一位是non-zero,none-zero位通常在这个应用场景里面会把它取为1,其他每一位都是0,也就是说这其实是一个Compression的过程,把一个Unit vector给compress成一个log2(n) Size的T。因时间问题,具体的做法我在此就不一一讲了,这是一个比较经典的技术,它是用一个Tree的Structure,在每一层会有一个Correction。也就是说它一共有log2(n)层,所以它的K Size会有log2(n)。这个在数据量比较大的时候,这个Tree的Expansion耗时会比较长;但是在数据量比较小的时候,它的操作会非常的快。
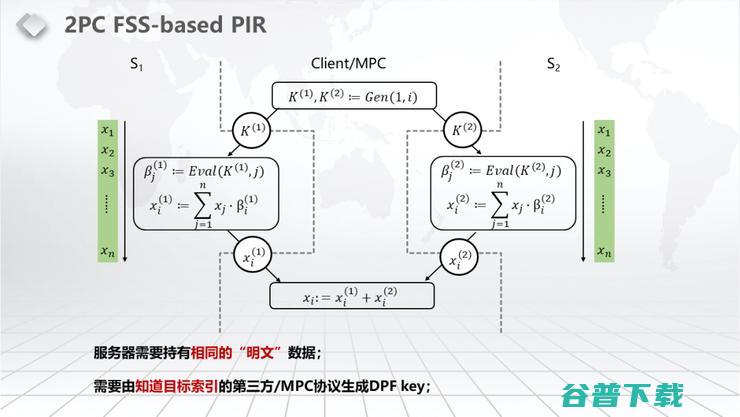
2PC会有一些缺点,2PC的这个FSS,传统的FSS-based PIR:
第一,它不能直接用在我们这里,原因是它需要两个Server两个服务器,看见相同的铭文,它其实是一个多Server的PIR。服务器上面的两个服务器要有一模一样的数据,然后你选取这个数据里面一模一样的PIR的位置,再到自己本地进行合成。
第二是这个Client知道自己要取哪一个数。那我们要做这个分布式的RAM,首先服务器不能知道这个数据的铭文是什么。其次,服务器在我们这个应用场景里面甚至也不可以知道它要取哪一个数。也就是说这两个都必须得秘密分享、必须得保护。
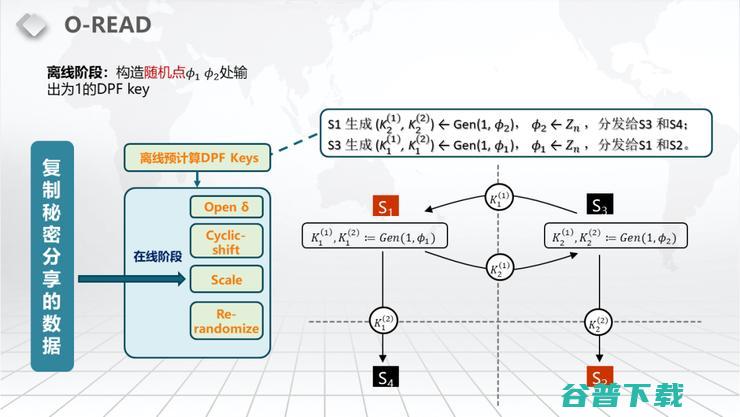
所以我们才会有一个4Server的结构。大概的思路是一个DPF需要两个服务器,有相同的值。在双服务器的情况下,这两个服务器必须存明文。但我们如果有4服务器,我们其实可以把这个数据秘密分享成两份。举个例子,这两份分别由S3和S4去拿同一份秘密分享的Share,S1和S2拿同一份秘密分享的Share,也就是Replicated Share。这两个拿同一份、那两个拿同一份,这样我们可以让S1去生成一个DPF的K分给S3和S4。S3和S4针对他们共有的Share可以做刚才的PIR的Evaluation。同理,这个S1和S2也可以对他们共有的Share去做PIR的Evaluation。
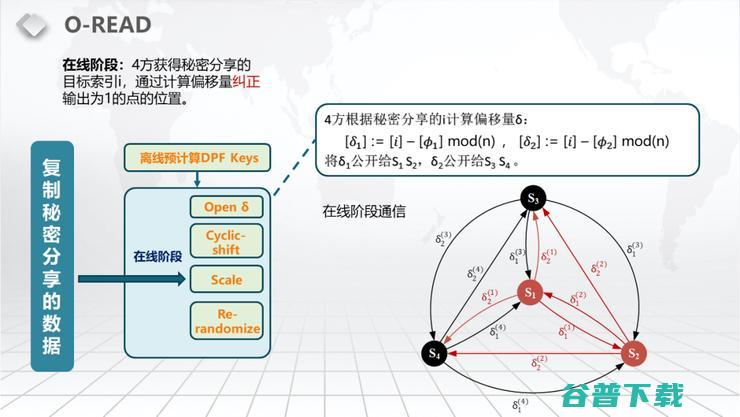
这里还会有一个问题,就是我们要取的这个点也不能透露给别人。要取的这个点不透露给别人,我们的做法就是在offline阶段,可以做一个DPF针对一个随机的点。比如说i是0到N减一里面任意的一个数,等到你实际上你要存取的那个值出来的时候,你把实际要存取的值减掉我们之前prepare的时候随机选的那个值,出来的那个数它其实就是一个offset,就是一个纠正量。我们让所有的服务器对自己的数据shift这个Cyclic的shift,就是去循环的移动偏移量,使得我们做的这个DPF它就相当于是针对一个未知的秘密分享的目标索引做的DPF。具体我在此就不细讲了。
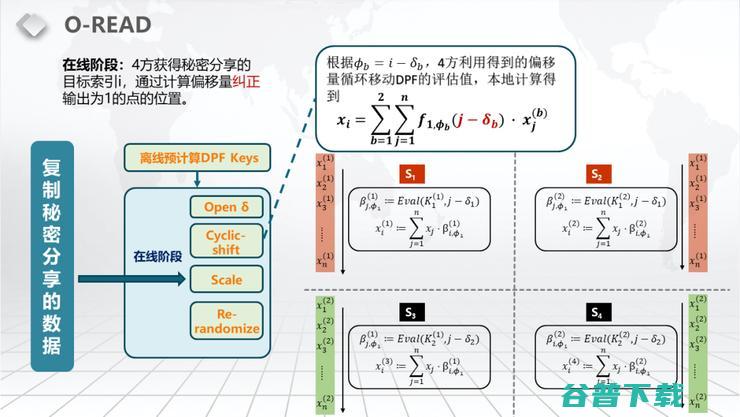
做完了以后,4方各自会做一个linear function,也就是说他们不需要通信就可以以秘密分享的形式去得到要取的数,就比如说你要取第i个数,那么这个数就叫Xi。根据上图的公式,你其实就可以算出这个Xi是什么,即Xi也是一个秘密分享的形式存在的。
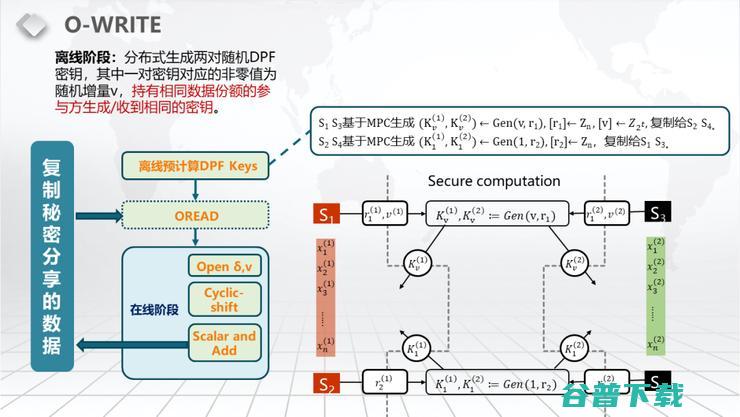
写怎么写呢?写会比读麻烦一点,因为如果只读的话3方也够,我们这个算法有3方的版本。如果你要写的话必须得4方。写,我们其实是有一个限制的。我们的写法大概的原理是你需要知道原始的数据是什么,你需要知道你写进去的这个数据是什么,然后你把写进去的这个数据减掉原始的数据,你就会有一个delta,即有个修改量、偏移量。你需要把原始的数据增加多少量才会变成你现在想要它变成的这个数据。
因为在我们的应用场景里面,你在写之前必定是读过那个格子的值的,所以我们这边并不会增加任何额外的开销。即我们这个假设你需要知道原始的数据是什么?现在修改的数据是什么?在我们这个应用场景里面是默认的假设。你会利用DPF针对你内存里面的每一个值都进行增加一个偏移量,就是刚才你算出来的最新的值和以前的值之间的差。
 当然这个增加的时候你会需要乘以一个Point Function,也就是说绝大部分除了一个位置之外,其他所有位置你增加的偏移量都是0。然后到那个位置,你增加的偏移量是Δv,在其他部分都是0。增加完、更新完以后,你的输出结果还是秘密分享,所以可以继续往下走不需要做读和写的转换。
当然这个增加的时候你会需要乘以一个Point Function,也就是说绝大部分除了一个位置之外,其他所有位置你增加的偏移量都是0。然后到那个位置,你增加的偏移量是Δv,在其他部分都是0。增加完、更新完以后,你的输出结果还是秘密分享,所以可以继续往下走不需要做读和写的转换。
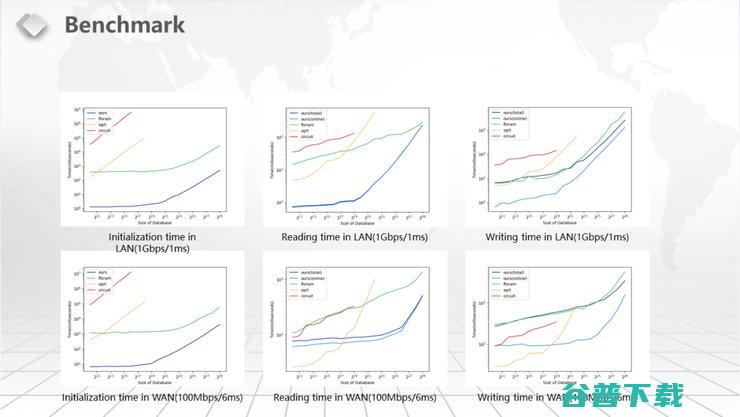
这个是我们具体的一个Benchmark的一个result。我们针对一些常见的或者现在state-of-the-art Distributed ORAM进行比较。比如我分别用红色、黄色和绿色来表示FLORAM ORAM、SQRT ORAM、CIRCUIT ORAM,我用蓝色来表示我们自己的。因为我们自己可以做offline和online的分离,所以在图中我会画两条线,一条线就是直接online的运行时间,一条线是把online和offline合在一起的运行时间。那么我们的初始化时间是显著优于任何其他工作,可以说我们几乎不要初始化。在读的做法里面,我们在绝大多数情况下优于任何其他的工作,只有当这个数据量比较小的时候,比如说数据量在2的20次以下的时候,那么SQRT ORAM会比我们的快一点点。这只是在某一些场景下面,比如说在WAN的场景下面。在写的方面,我们整体的效率和FLORAM ORAM差不了多少。但是因为我们是可以把online和offline分开的,如果你只看online效率,当数据库比较大的时候、超过2的20次的时候,我们的效率明显高于所有已知的Distributed ORAM。
MPC模拟CPU
有了这个非常高效的Distributed ORAM,我们就可以开始模拟这个RAM结构的CPU了。我们模拟的思路是以RAM的形式去管理存储结构,包括所有的存储结构(我们用的是冯诺依曼结构)、包括整体CPU运行时候的你的指针PC值和一些Flag值、一些寄存器值、一些内存的值、一些指令,所有东西都由RAM形式接管。具体来说,我们把普通的代码,也就是任何一些C语言、高级语言的代码,用常规的编译器编译成TinyRAM的指令集。我们会对TinyRAM指令集里面的指令进行解析。解析完以后,我们会进行隐私保护的执行。我们后面会讲具体是怎么执行的。它是密态执行然后密态选择、茫然更新,整体、所有的过程都是Oblivious,都是内存保护的。
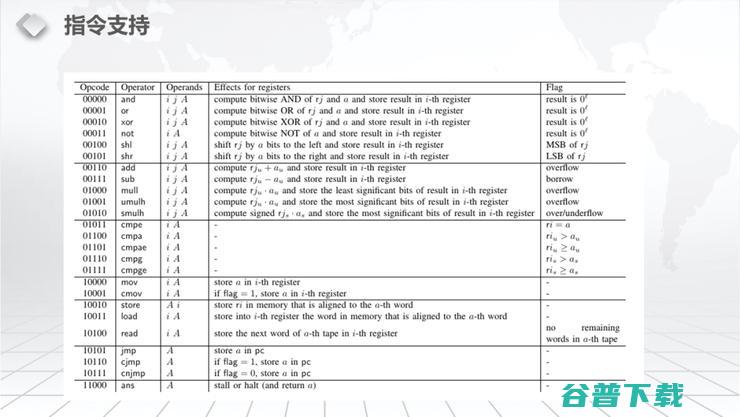
具体的指令集大概有25个左右,前半部分是boolean的指令集,也就是说位操作,比如说AND、OR、XOR、NOT 、Shift等等。中间是一些加减乘除的常规操作,后面第三类是一些各种各样的比较,它的Flag会不一样,然后会有一些mov的操作、存取的操作和跳转的指令。

整个 Oblivious Cycle如上图中的左图所示,你可以想象成它其实就是TinyRAM的一个机器。这个机器的所有状态全部都是以秘密分享密态的形式存储的,它有Private PC (Program Counter)。你每次来一个指令的时候,指令是从哪里读的呢?指令我们专门有内存的Memory,我们这个结构、内存的Memory是可以不区分指令区和数据区的。也就是说如果你的代码的写作方式是在你代码的运行期间动态产生代码、新的代码,我们是可以支持这种形式的。即你不需要把代码定制在这个Memory里面,代码的那部分Memory只读,数据的Memory可以读写,我们不需要这样。代码和数据是可以混在一起的,而且你可以动态的去修改你的代码。有一些病毒就很喜欢并且能做到把自己数据区域的数据变成代码再去运行。
我现在不是以程序安全的角度去讲这件事情,是以功能性的角度去讲这件事情。我们其实可以满足这样的功能需求。我们这个程序会从这个Memory里面、隐私保护里面取一条指令进行解析,解析完毕后,这条指令它会有操作数还有它自己做的是什么操作、要用到什么寄存器。比如说我们会用到什么寄存器,寄存器寻址或者立即数寻址。我们再到内存里去取相关的数,取了相关的数以后我们做操作,做完操作以后再进行选择,就是你实际上的结果。我们再把这个结果存回去,然后根据你的Flag,我们会去update这个Program Counter,就是我们下一条要运行哪条指令。我们基本上是根据这个Program Counter到这个Memory里面再去取下一条指令。
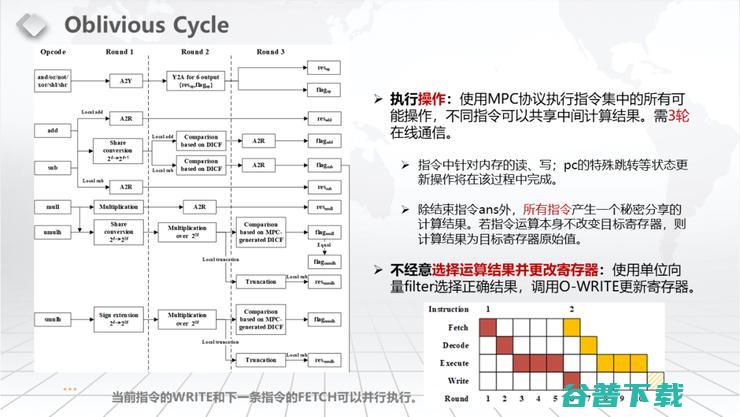
具体来说,其实我们的Oblivious Cycle最大的开销就是我们要支持二十多条的TinyRAM的指令集。我们要做到所有指令集都在同一个步骤里面完成。大致的思路就是如何防止你知道我做的是哪一条指令,我们就把所有的指令都做了,当然不是把每一条指令单独做一遍。观察上图的左边部分你会发现,我们对所有的指令集有机进行组合。
也有前人在工作中把若干的指令集用姚式混淆电路编出来。姚式混淆电路会比较大,我们这里是用ABY的结构,有一些用姚式混淆电路做,有一些用布尔电路做,有一些是用代数电路做,所以我们这个非常高效。对于所有的指令集,我们可以在三轮内完成,包括Compare、一些比较、一些跳转,各种指令在三轮内完成。我们有一些指令做的会比较快,有一些指令做的会比较慢,有一些指令之间是共享一些中间结果的,所以我们是有机的去组合起来。
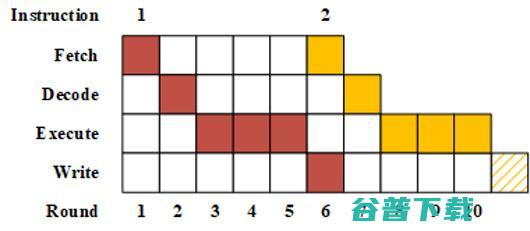
我们整体的MPC的Private Function Evaluation的大概运行结构如上图所示:第一轮要Fetch,就读一条指令。第二轮Decode这个指令,顺便去读取相关的操作数。第三轮是Execute,因为我们需要涵盖指令集里面所有的指令,所以Execute其实需要三轮。第四轮是写,因为写和Fetch可以同时执行,所以它们在同一个pipeline里面可以重叠。基本上我们这个程序就是这样循环。
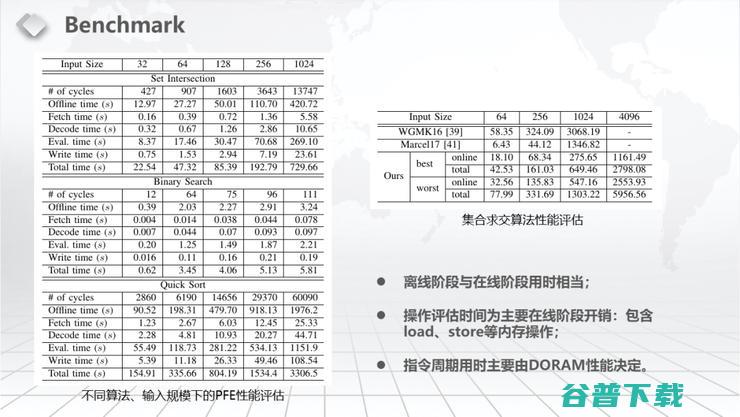
我们为了展示这个程序的效率做了一些相关的RAM结构下比较常见的函数的Evaluation。比如说Binary Search,比如说Set Intersection,比如说Quick Sort。具体我们把Offline、Fetch、Decode、Evaluation、Write的时间都分开测了,也包括Total time。注意,因为我们是保护函数的,所以相比于不保护函数的一些安全多方计算,时间确实慢一点。
有人说这个Binary Search感觉和Linear Scan差不多。注意,我们是保护函数的,你其实根本不知道我是在做Binary Search。为什么这个Binary Search会拿出来单独做呢?因为如果这个不是RAM模型的结构,要做Binary Search是非常难做的,必须要整个Memory scan一遍才能够做到。我们现在基本上你只要做log2(n)步就可以了,也就是说你只要做log2(n)次的比较你就能得出这个结果。
因为时间关系我们今天就分享到这里。如果大家有什么问题,欢迎大家Email,我的邮箱是bingsheng@zju.edu.cn,谢谢大家,再见。
版权文章,未经授权禁止转载。详情见 转载须知 。



杭州宝盈净化科技有限公司是一家集风淋室,货淋室生产、销售于一体的净化设备公司。风淋室根据尺寸可分为:单人单吹风淋室,单人双吹风淋室,双人双吹风淋室,三人双吹风淋室,多人风淋通道,货淋室;风淋室根据材质可分为:不锈钢风淋室,外冷板内不锈钢风淋室,净化板风淋室;风淋室根据自动化程度不同可分为:智能语音风淋门,自动门风淋门,防爆风淋门,快速卷帘门风淋门,平移门风淋室,转角风淋室。可应用于微电子、光电、半导体、医药、食品、化工、航空、汽车、印刷、医院、实验室等各个行业。风淋室厂家电话:17682313753。

中投网国内知名的投资资讯网站,为股权投资,创业投资,风险投资,私募股权,创业者提供TMT,IT服务,互联网,清洁技术,医疗健康,消费连锁等行业投资融资,上市IPO,收购重组,基金募集等资讯信息的股权投资权,风险投资专业门户。

常州源美金属制品有限公司主要产品为CNC切削液过滤装置,各通讯类、医疗设备类、射频电源、匹配器外壳类、高铁零部件等同时公司对外承接各类钣金加工业务(标准钣金件与非标钣金件)。公司根据客户的需要代为设计方案,尤其对精度、外观要求高的产品有丰富的生产经验。

云商机汇【32743.com】多渠道营销宣传您得产品,支持小程序,移动端,电脑端,支持多个搜索引擎,让您轻松接单,快来注册发布吧。

爱尼丝化妆品是一家集化妆品代加工、面膜OEM、护肤品OEM、精油OEM、原液OEM、身体药油OEM、水乳霜OEM、致力服务电商微商,日化线专业线的广州化妆品代加工厂家。

永航房屋防水维修公司是一家拥有国家贰级资质专业从事防水、补漏工程、施工,室内外防水,防腐,保温的企业。公司拥有一批高、中级技术职称的专业技术人员和管理人员,高素质的施工服务队伍,有二十多年专业从事防水、补漏、施工的工作经验,对新旧屋面、地下室、卫生间、厨房、伸缩缝、裂缝、内外墙等各部位的防水补漏工程施工,多年来积累了丰富的施工经验,总结了一整套传统与现代工艺相结合的防水补漏的方法,能针对不同情况正确选材合理施工。

中国鲜花速递、鲜花店、花店、上海鲜花店、北京鲜花店、重庆鲜花店、广州鲜花店、成都鲜花店、大连花店、天津花店、武汉花店、西按花店、青岛花店、深圳花店、东莞花店、重庆花店、长沙花店、昆明花店、郑州花店、ChineseFlorist、flower

天音移动网上营业厅

奥玛物流仓储联盟是国内首家仓储物流公司同业联盟,成员覆盖全球1059个城市,已有113760多家仓储及3PL企业加盟,为您提供仓库出租、仓库信息发布、仓库托管服务,如需找物流仓库,找第三方仓储物流服务商,这将是您需要的仓储物流服务信息平台!

女鞋加盟网包含10大时尚女鞋加盟店排行榜,女鞋加盟项目500个。网站提供女鞋店连锁加盟、品牌女鞋招商、品牌女鞋代理等内容,深受创业加盟者喜爱。

未来鸟服务平台旗下产品新版知识库


生存建造的游戏在如今游戏市场还是比较火爆的,总会有刺激人心的场面,今天所介绍的几款游戏都只能够利用仅有的资源,然后在游戏中获得更多的生存空间,每一款游戏都拥有着属于自己的特色,可以让玩家朋友们在游戏中能感受到一种真实的荒岛生存模拟体验,有兴趣不要错过以下的这几款,1、,创造与魔法,创造与魔法,是一款拥有较高自由创作程度的游戏,玩家将...。

1、华为华为,作为中国目前最大的通讯设备供应商,华为2017年的净利润为475亿,要知道华为的薪酬福利在同行中属于佼佼者,年薪500万以上的人也大有人在,任正非曾说过这样已经非常有名的话,不上市,华为也可能称霸世界,如今华为真的做到了,华为创始人任正非之女、该公司首席财务官孟晚舟也表示,个人认为,如果华为上市对华为的开放透明肯定...。

以上就是绿色先锋小编整理的notability怎样购买的内容了,希望可以帮助到大家!我们会持续为您更新精彩资讯,欢迎持续关注我们哦!...。

作者丨何思思编辑丨周蕾有句老话叫做,酒香不怕巷子深,,但在市场经济快速发展的今天,这句老话似乎有些失效了,企业对营销手段的重视程度日渐高涨,更试图借助于互联网、通信技术和数字化手段,为营销过程加持,吸引更多消费者,聚焦到行业应用,金融行业的数字化营销要领跑于其他行业,不仅是因为金融业的信息化、数字化进程较快,更因为金融机构在展业过程中...。

iQOONeo10系列在11月29日发布,iQOONeo10是2299元起的骁龙8Gen3,iQOONeo10Pro是3199元起天玑9400——它们都用上了最新的维信诺F1屏幕,现在低亮度频闪控制最好的屏幕,、和iQOO13同款的自研独显芯片Q2、超声波指纹、6100mAh双电芯,120W快充,兼容100WPPS快充,iQOONe...。

中年“发福”的女人,穿衣掌握三个套路,轻轻松松摆脱油腻感,腰线,油腻感,层次感

由于全国流感迸发,重庆也越来越重大了,只管咱们说的完了,然而在条款外面有个无法抗要素,还要让咱们在这种弛缓的状况下去!去了有个不好的体验,胆战心惊的嘛!给美团客服打电话也是说没方法不能退,这属于霸王条款,假设说是在反常状况下是由于我自己自己的要素不想去了,钱不退次要,是我的疑问,然而如今是不凡......。

1、在梦中,假设是孕妇梦见下雪,预示着会生一个肥壮可恶的男孩,2、在梦中,假设是少女梦见下雪,预示着将有一段美丽的邂逅,3、在梦中,假设梦见自己一团体在雪中行走,暗示着同性好友增多,4、在梦中,假设梦见很深的积雪,预示着将有烦恼事出现,一旦有了烦恼将不知何去何从,5、在梦中,假设梦见在冰冻的雪路上滑倒,对某件事件要特意小心,感情方面也...。

可以经常使用,快玩游戏盒是一个用于玩游戏的运行程序,只需运行程序在设施上装置没有被官网中止允许或产生严重疑问,都能够继续经常使用来玩游戏,快玩游戏盒V3655官网正版快玩游戏盒V3655官网正版性能简介大家好,对于快玩游戏盒V3.6.5.5官网正版,快玩游戏盒V3.6.5.5官网正版性能简介这个很多人还不知道,如今让咱们一同来看看吧!...。
有手机版的,然而配置没有PC版的那么完整,假设你是一名个别用户,只是宿愿对自己的照片启动便捷的编辑解决和赞美,美图秀秀足够了,然而假设你是从事平面设计之类的设计类上班须要修图工具的话,首选当然是Photoshop,photoshop汉化手机版,手机版,手机可用的平面设计作图软件手机可用的平面设计作图软件有绘画神器手机版、AUTOCAD...。

外地期间6月11日,塞浦路斯西南部帕福斯地域出现野火,邻近三座村庄的村民被疏散,塞方已恳求约旦、希腊,以色列和欧盟援助灭火,约旦和希腊已派出消防直升机和飞机前往塞浦路斯介入灭火,总台记者杨明交,1、塞浦路斯危机爆发的原因,50分,2、欧盟救助塞浦路斯的必要性,50分,总字数不少于1000字,貌似塞浦路斯的危机是由希腊危机引起的...。

.exe,.dll,.sys等xp,win7下的相关系统文件下载,如果文件丢失或者打不开等状态可以来这里查找相关dll文件下载。PC6免费提供.dll文件,.exe文件,系统文件下载

迷宫解谜游戏下载2022,近几年,随着密室大逃脱和明星大侦探等综艺的播出,越来越多的人热爱上这类益智休闲类的游戏了,与此同时,一些带有解谜元素的游戏也开始陆续上线,今天小编就来给大家推荐几款超级好玩的益智休闲类迷宫解谜游戏吧,1、,你好邻居们,你好邻居们,是一款带点惊悚元素的冒险休闲类游戏,这款游戏的互动玩法非常有趣,玩家需要通过解...。

香港,6月12日,香港投资管理有限公司,下称,港投公司,与思谋科技共同举办战略合作协议签约仪式,此次签约仪式得到了香港特区政府的高度重视,香港特别行政区行政长官李家超透过视频致辞,香港特别行政区政府财政司司长陈茂波到场见证签约并在午餐会发表主旨演讲,各界对港投公司与思谋科技在人工智能前沿科技产业化落地的合作,包括在粤港澳大湾区更广泛...。

昨天,著名深度学习开源库Keras通过官方博客正式发布了全新版本,Keras2,根据官方介绍,此次更新的重点有两个,Keras表示,从2015年3月发布第一个版本以来,有数以百计的开发人员对Keras的开源代码做了完善和拓展,数以千计的热心用户在社区对Keras的发展做出了贡献,目前,有大量的AI初创公司在Keras的帮助下挂牌成立,...。

雷锋网AI科技评论编者按,8月24,25日,在北京友谊宾馆举办了第十届国际图象图形学学术会议,ICIG2019,这个会议由中国图象图形学学会,CSIG,主办,清华大学、北京大学和中国科学院自动化研究所承办,ICIG每两年举办一次,也是中国图象图形学学会主办的最高级别的系列国际会议,会议重点关注图像、视频和图形处理的创新技术,是图像图...。

平静了一段时间的即时零售赛道,最近颇为热闹,拉满话题的是各种,仓,山姆的前置仓业务超过了总收入的一半,并实现了盈利,开始反哺线下店,这也正是很多零售商需要的,名创优品在盈利模型跑通后开始规模化,开仓,,目前已经开了500多个,闪电仓,为什么有线下成熟渠道布局的零售商纷纷以,仓业态,加码即时零售,仓,对于它们的意义是什么,为实体店...。
