通义千问继续开源多模态模型 Qwen2
8月13日消息,阿里通义大模型继续开源,Qwen2系列开源家族新增音频语言模型Qwen2-Audio。Qwen2-Audio可以不需文本输入,直接进行语音问答,理解并分析用户输入的音频信号,包括人声、自然音、音乐等。该模型在多个权威测评中都显著超越先前的最佳模型。通义团队还同步推出了一套全新的音频理解模型测评基准,相关论文已入选本周正在举办的国际顶会ACL 2024。
声音是人类以及许多生命体用以进行交互和沟通的重要媒介,声音中蕴含丰富的信息,让大模型学会理解各种音频信号,对于通用人工智能的探索至为重要。Qwen2-Audio是通义团队在音频理解模型上的新一步探索,相比前一代模型Qwen-Audio,新版模型有了更强的声音理解能力和更好的指令跟随能力。

Qwen2-Audio是一款大型音频语言模型(Large Audio-Language MODEL ,LALM),具备语音聊天和音频分析两种使用模式,前者是指用户可以用语音向模型发出指令,模型无需自动语音识别(ASR)模块就可理解用户输入;后者是指模型能够根据用户指令分析音频信息,包括人类声音、自然声音、音乐或者多种信号混杂的音频。Qwen2-Audio能够自动实现两种模式的切换。Qwen2-Audio支持超过8种语言和方言,如中文、英语、法语、意大利语、西班牙语、德语、日语,粤语。
通义团队同步开源了基础模型 Qwen2-Audio-7B 及其指令跟随版本Qwen2-Audio-7B-Instruct,用户可以通过Hugging Face、魔搭社区ModelScope等下载模型,也可以在魔搭社区“创空间”直接体验模型能力。
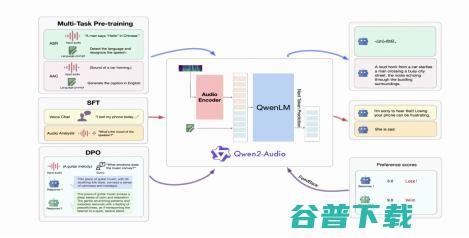
Qwen2-Audio的模型结构与训练方法
根据Qwen2-Audio技术报告,Qwen2-Audio的模型结构包含一个Qwen大语言模型和一个音频编码器。在预训练阶段,依次进行ASR、AAC等多任务预训练以实现音频与语言的对齐,接着通过SFT(监督微调) 强化模型处理下游任务的能力,再通过 DPO(直接偏好优化)方法加强模型与人类偏好的对齐。
研发团队在一系列基准测试集上对模型效果作了评估,包括 LibriSpeech、Common Voice 15、Fleurs、Aishell2、CoVoST2、Meld、Vocalsound 以及通义团队新开发的 AIR-benchmark基准。在所有任务中,Qwen2-Audio 都显著超越了先前的最佳模型和它的前代 Qwen-Audio,成为新的SOTA模型。
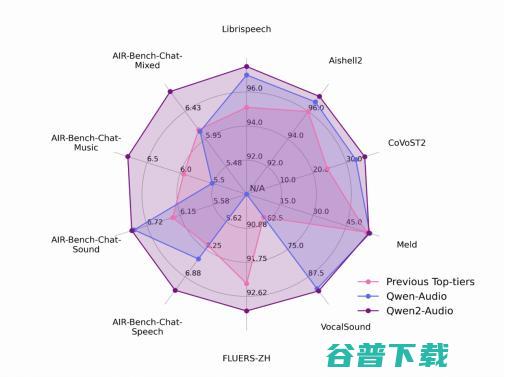
Qwen2-Audio 在多个测评中都显著超越了先前的最佳模型
附:Qwen2-Audio下载或体验地址
魔搭模型页面:
魔搭体验页面:
GitHub:
Hugging Face:
Qwen2-Audio技术报告:
AIR-Benchmark论文地址:
版权文章,未经授权禁止转载。详情见 转载须知 。


一个随时随地都可以亲近的虚拟线上寺庙、大德云集脉络清晰次第分明的学佛平台、免费经论结缘互动法义讨论平台。弘扬佛陀正法,普济天下苍生!

云南佳松新能源科技有限公司于2009年08月14日在官渡区市场监督管理局登记成立,位于云南省昆明市前兴路邦盛新时代电器城5栋附1号,法定代表人姚青松。公司主要经营业务:新能源技术的研究与推广;计算机软硬件的开发及应用;计算机系统集成及综合布线;太阳能设备及配件、空调设备及配件、水净化设备、空气净化设备、环保设备、电子产品、塑料制品(塑料购物袋除外)、五金交电、水暖器材、建筑材的销售;太阳能设备及配件、空调设备及配件、水净化设备、空气净化设备的生产、安装及维修。佳松科技是集保险·太阳能·空气能热水器及建材销售的多元化公司。公司秉承“顾客至上,锐意进取”的经营理念,坚持“客户第一”的原则为广大客户提供优质的服务。业务垂询电话:0871-67211918

【广东领天机电】-【热线电话:13729996265】位于广东东莞,珠三角各大城市设有服务部,专注于东莞柴油发电机出租,深圳柴油发电机出租,惠州柴油发电机出租及发电机维修配套服务!

建材板材网提供各种建材圆柱模板价格、批发、行情等建材模板供应信息,建材模板图片及圆柱模板厂家信息,为你免费提供建材模板的供求信息、行情报价、行业资讯等内容

厦门南洋职业学院

可米生活KEMElife旗下签约近百位国内外青年艺术家,品牌拥有丰富的艺术品原作和艺术IP资源。在艺术品陈设、潮流设计、家居家饰、消费电子等品类积累了近千款经典产品,成为当代时尚人群生活方式消费的首选品牌

要买滑触线,安全滑触线,安全滑线、滑触线集电器,滑触线指示灯,扁电缆,工字钢滑车,节能滑线,安全滑线滑线导轨等。就来扬州市苏博滑触线有限公司看看吧!我们公司的安全滑触线产品一应俱全,相信一定有您中意的安全滑触线。

微签名网有全面的个性签名大全,包含了电子签名,名字签名,微信签名,qq签名,最后短句签名,签名设计,手写个性签名,2023最火签名,个人签名,找签名就来微签名。

巴洛仕集团专注化工厂拆除,整厂回收,设备回收,二手化工设备,化工装置回收,废设备回收等服务,化工厂废旧设备拆除回收,大型厂房整厂拆除回收就找巴洛仕一站式拆除回收解决方案提供者。

团众家具回收网,我们秉持着诚信经营、全心全意为顾客服务的理念,专业高价回收二手办公家具、回收办公桌椅、回收电子电器、回收二手数码3C产品,帮您解决各类二手闲置物资问题.

交通事故赔偿网是广东国晖律师事务所精心打造的网络交流平台,提供交通事故赔偿、事故处理办法、责任认定、伤残鉴定、诉讼调解、保险理赔、索赔必看等交通事故方面知识。

监理检测网是由施工监测加固、建设监理和试验检测网三大部分组成,主要提供试验检测人员招聘、施工监理人才招聘求职和技术交流、检测考试培训;考试资料下载。

在看动漫的时候每个人都会根据自己喜欢的类型选择合适的作品,在app当中也有很多可以满足漫迷们需求的,拿着手机想什么时候看都是可以的,那么动漫软件有哪些呢,今天小编给大家详细的介绍几款,里面具有丰富的动漫作品,可通过搜索或者是里边所包含的作品就能免费的进行观看,看动漫的时候下载这款应用既能感受好看的动漫以及所带来的乐趣,里面还会介绍很多...。

虽然VR行业的许多人对消费级全景相机不屑一顾,认为它们拍摄的不是真正的VR内容,但我们且先按下关于VR内容定义的讨论,回到用户角度来看,事实上,消费级全景相机生产的内容确实可以用VR头显观看,这类相机也是最亲民的VR拍摄工具,从YouTube、优酷上的360度视频,到各大直播平台推出VR直播产品,再到普通人用360度视频记录自己的生活...。
今日头条董明珠回应落榜世界500强,总比爆雷的世界500强好近日,格力电器董事长兼总裁董明珠在一档访谈节目的视频中,首次就格力电器今年从2023,财富,世界500强的榜单中落榜一事进行了公开回应,当被问,难过吗,时,董明珠说,有什么好难过的,一点都不难过,看到企业,格力电器,这么健康好开心,总比爆雷的世界500强好,世界500强有何意...。

发表在专业问答2020,9,2320,45凸透镜,投影仪镜头采用的是凸透镜,投影仪是要光线经过镜头之后成倒像而且必须是实像,所以要采用凸透镜,因为经过凸透镜之后会成放大、倒立的实像,投影仪的镜头是凸透镜还是凹透镜凸透镜,投影仪镜头采用的是凸透镜,投影仪是要光线经过镜头之后成倒像而且必须是实像,由于经过凹透镜成像的画面为虚像,经过凸透镜...。

下面就为大家带来海信卷曲屏激光电视通过U盘安装第三方软件教程,具体方法如下,一、首先在电脑下载安装当贝市场,点击此处下载二、打开海信卷曲屏激光电视,在,聚好看,里找到,U盘助手,,再选择全部文件,找到当贝市场文件包,然后选择,软件包安装程序,进行安装即可,三、完成安装后,打开当贝市场,就能随意安装第三方应用软件了,比如,葫芦视频,,,...。

王忠民:统一体制内外退休金,预估可能在5年后会实现,王忠民,养老金,退休金,延迟退休,五险一金,养老保险

安能物流运输中转失误造成货物延误,安能客服一直不处置,还让其下属公司加我微信要身份证和银行卡信息,说没有这些信息就不能抵偿,不时拖到当天,一个星期了,我疑心他们客服实在性,所以没有提供身份证信息,再加上他们运输中转失误,造成货架破损货物散落,到我这边站点上班人员曾经上报货架破损,说我签收,他曾经上报了,有截图记载为证,而后他们安能客服...。

澳门司法警察局15日示意,司警在侦察一宗冒充名表典当案件时期,经对比嫌疑人身份资料,发现其与日前中原男性游泰国遭绑架案件涉案人身份吻合,无关案件已移交中原警方跟进,据悉,涉案男性姓马,34岁,持中国护照,无业,案情显示,涉案人马某于7月10日因涉嫌到某当铺典当假手表,被职员发现后报警,司警接手跟进后,在氹仔客运码头完成截获预备前往香港...。

手机输入腾讯,在外面选用下载软件,而后找到手机QQ,选用自己手机适宜的手机QQ软件,假设找不到婚配的QQ手机QQ,就下载通用版的,下载后间接装置,1、首先在手机中关上阅读器,而后在阅读器地址栏中输入参考资料内给出的,QQ信息,网站,2、关上后,在页面中输入自己的QQ号码自己QQ明码,而后点击,登录,按钮登录自己的QQ,3、登录成功后,...。

山东济宁是一个历史悠久、文明底蕴深沉的城市,领有泛滥的人造景观和人文景点,在春天,自驾游是探求这座城市的绝佳模式,以下是一些适宜春日自驾打卡的路途介绍,曲阜,邹城,微山湖路途,从济宁登程,首先返回曲阜,这里是孔子的故乡,可以观赏孔庙、孔府和孔林,感触儒家文明的博大精湛,随后驱车返回邹城,探望孟子故里,了解另一位儒家圣人的生存和思维,最...。

山川壮美文明悠久民风憨厚这里是塔吉克斯坦共和国塔吉克斯坦位于中亚西北部北邻吉尔吉斯斯坦西邻乌兹别克斯坦南与阿富汗接壤东接中国物品长700公里南北宽350公里面积14.31万平方公里人口1036万首都杜尚别是塔吉克斯坦的政治、经济、迷信及文明教育核心塔吉克斯坦境内多山约占疆土面积的93%群山高耸景色绚丽素有,平地之国,佳誉塔吉克斯坦水资...。

此类股下周大涨_狄琼霏_新浪博客,狄琼霏,

除了通过Windows系统直接升级Windows10之外,中国区用户还可以通过腾讯管家助手和360电脑卫士的渠道升级Windows10,不过通过这两个渠道升级Windows10的多数用户反馈在升级的过程中出现黑屏、死机、无限重启的各种状况,在经过,艰难的决定,后,腾讯和奇虎360都在今天中午相继宣布暂停Windows10的升级服务,腾...。

很多人出门就餐时,都会选择拥有一定知名度的火锅品牌,于是朝天门火锅便成为一些人的好的选择,品牌用美味的食物,向消费者和运营者表明了自己的优势,如今,品牌不仅获得了固定的客源,还收获了很多好的合作伙伴,合作伙伴较为关心朝天门火锅加盟费的问题,今天小编将针对这个问题来进行解答,朝天门现在已经发展形成了较为庞大的运营规模,在国内和海外地区均...。

大疆回应被列入,实体清单,照卖不误美国商务部18日以,违反美国国家安全,为由,宣布将包括大疆公司在内的59家中国实体列入所谓出口管制,实体清单,据路透社20日报道,大疆在给该媒体一份邮件声明中,对被美国政府列入清单做出回应,大疆对美国商务部的决定感到失望,,路透社称,大疆公司在发给路透社的邮件声明中说,,美国的客户可以继续正常购...。

有着深厚历史沉淀的百年药企,在拥抱AI技术这方面,嗅觉丝毫不钝化,最近的一个案例,是阿斯利康,近日,这家药企巨头阿斯利康在一天之内,与两家制药公司——BenevolentAI、ScorpionTherapeutics,达成研发合作,协议称,阿斯利康将利用两者的AI药物开发平台,加快针对系统性红斑狼疮,SLE,和心力衰竭,HF,的新药开...。

6月26日,字节跳动在北京发布了基于豆包大模型打造的智能开发工具,豆包MarsCode,面向国内开发者免费开放,发布会以,用AI激发创造,为主题,在草地露营的轻松氛围中发布了豆包MarsCode并介绍了其主要功能,同时发布开发者及社区共创计划,吸引了众多业界人士、开发者和科技爱好者的关注,豆包MarsCode产品发布会现场AI时代开发...。
