AI在艺术创作中又犯了种族偏见的大忌 奥巴马被强行 后 洗白 (ai在艺术创作中的潜力与局限)
你能识别出哪一幅艺术作品是AI创作的吗?

即使是最有经验的艺术家,有时也无法将AI艺术作品与人类艺术作品区分开。在巴塞尔艺术展上,有53%的观众认为这些作品全部来自人类。
而事实上,它们全部来自罗格斯大学(Rutgers University )艺术与人工智能实验室团队创建的神经网络AI。
AI已经学会识别经典艺术作品的创作风格和手法,并将其融汇贯通创作出全新的艺术作品。以上作品的创作素材来自于15世纪至20世纪1000多个艺术家的80000多幅画作,这些画作涉及印象派绘画,立体派绘画,以及文艺复兴早期绘画等不同风格。
凭借快速、高效且丝毫不逊色于人类的创作能力,AI已经被广泛应用于艺术生成领域。但随着AI作品的日益增多,我们不得不思考一个问题:在其被称为“黑匣子”的艺术创作过程中,AI算法是否存在偏见?
近日,来自美国Fujitsu AI Lab的研究人员发表了一项最新论文:《艺术史视角下的生成艺术偏见》
 他们在论文中明确指出:AI在艺术创作过程中没有考虑到社会伦理的影响,表现出了明显的偏见。
他们在论文中明确指出:AI在艺术创作过程中没有考虑到社会伦理的影响,表现出了明显的偏见。
AI艺术创作背后的三大偏见
在论文中,研究人员通过因果模型DAG,对现有AI艺术创作工具和作品进行了测试,以发现它是否存在偏见。
为了确保研究的准确性,他们调查了学术论文中的AI模型、在线AI平台以及相关应用程序,并选择了艺术风格(文艺复兴艺术、印象主义、表现主义、后印象主义和浪漫主义)、流派(风景画、肖像画、战争画、素描和插图)、材料(木版画、雕刻、绘画)以及艺术家(亨特、玛丽·卡萨特、文森特·梵高、古斯塔夫·多雷、吉诺·塞维里尼)等多个类型的AI艺术作品进行了评估。
在一项测试中,他们发现AI生成艺术工具 Abacus存在明显的性别偏见,如皮耶罗·迪科西莫(Piero di COSimo)的画作《一个年轻人的肖像》是一位留着长发的年轻男性,但它却识别成了女性(iii-iv)。

另外,还有些AI工具可能涉及种族主义偏见。如GoArt,它允许用户以其他艺术家的风格重新绘制图片的平台。在表现主义创作中,GoArt将克莱门汀·亨特(Clementine Hunter)的黑人女族长的脸从黑色变称了红色。

而德西德里奥·达·塞蒂加纳(Desiderio da Settignano)在文艺复兴时期创作的白色雕塑《乔维内托》,在表现主义转换中,面部颜色没有变成红色。
此外,类似于GoArt的一款AI工具Deepart在艺术风格识别方面也存在明显缺陷。如根据下面中心图《玛丽·埃里森小姐》(现实主义风格)转换而来左图,并没有呈现出表现主义的艺术特点。
右图为表现主义作品:恩斯特·路德维希·基什内尔(Ernst Ludwig Kirchner)的《尔纳》。

无论是AI绘画,还是写作,或者创作音乐。其基本原理都是先通过庞大数据集训练,学习相关知识,然后再经过AI模型,完成训练和输出。
研究人员认为,以上输出之所以存在偏见,根本原因应归咎于训练数据集的不平衡。主要体现在两点上:一是数据集的收集受到了人为偏好的影响。例如,他们发现AI应用程序Portraits,其使用的45000幅文艺复兴时期的肖像画大部分是白人。
二是数据集的标记可能存在不一致,或者是模型在学习标签来注释数据集的过程中产生了偏差。不同的注释者有不同的偏好、文化和信仰,这些都可能反映在他们创建的数据标签中。
最后研究人员也警告称,AI研究人员和实践者在检查、设计及应用过程中应充分考虑社会政治背景因素,通过错误地建模或忽略创建数据集的某些细节,AI生成艺术可能会引起人们对社会、文化和政治方面的误解,或引起不必要的争议和冲突。
目前,无论是业界还是学术界,对于AI算法可能存在的偏见已经引起广泛的注意,因为它已经多次挑起种族主义风波。
奥巴马被洗白,AI种族偏见惹争议
近几年,随着研究的不断突破,计算机视觉技术得到突飞猛进的发展。
因此不仅在艺术生成领域,AI在更广泛的图像识别与合成方面均存在潜在的偏见风险,尤其在涉及人脸图像上。例如,今年上半年,杜克大学出品的一款PLUSE算法便被指责存在种族歧视,在社交平台引起了轩然大波。
风波的起因是,PULSE将前美国黑人总统巴拉克·奥巴马(Barack Obama)的图像变成了白人。

PULSE是一种新型超分辨率算法,其功能是将低分辨率的图像转化为高清图像(生成逼真、且不存在的人),但在其输出结果中产生了明显的肤色偏好。
不仅仅是奥巴马。在网友们的测试中,美国国会议员亚历山大·奥卡西奥·科尔特斯(Lexandria-Ocasio Cortez)、女星刘玉玲(Lucy Liu)等人的肤色也被PULSE变成了白色。


由此不少网友认为,AI存在根深蒂固的种族偏见。
当时,PULSE的创建者也承认,该算法在按比例放大像素化图像时更可能生成具有白种人特征的人脸。而且他说:“这种偏见很可能是StyleGAN从数据集中继承的。”
其实,这个问题在机器学习中极为普遍。其主要原因是用于训练AI的数据集通常是在人口统计学上占优势的白人。如果数据集中不出现或较少出现黑人,会影响AI模型的性能,导致输出结果是白人的几率更高。除此案例外,AI在面部识别算法中也多次引发种族争议。
那么数据集存在偏差,必然会导致算法偏见,那么如何才能有效改善数据集呢?
如何避免数据集偏差?
作为AI研究的基础,如何修正和完整数据集一直是研究人员关注的重点。
其实,除了频发引发争议的种族偏差、性别偏差外,数据集在研究过程中也存在测量偏差、排除偏差以及关联偏差等一系列问题。不过,近几年针对如何解决数据偏见问题,研究人员也开发出了很对应对措施,例如通过少量数据标注,提高模型泛化能力,减少人为标注可能带来的偏差等。
总体来说,防止数据偏差是一个持续的过程,有时很难知道数据或模型何时出现偏差,而且不同数据集也存在不同的标准。不过相关研究人员也总结了以下通用准则,以帮助我们及早发现和减少偏差:
引用链接:
原创文章,未经授权禁止转载。详情见 转载须知 。


更精准的搜索,更流畅的观赏;360图片收录几十亿高清美图,为用户提供壁纸、素材、头像、写真、摄影、风景等最新、最全的高质量图片搜索服务!

飞卢小说网,最热门的免费小说网站,提供都市小说、玄幻小说、穿越小说、言情小说、同人小说等免费小说在线阅读与下载。大神小说齐聚飞卢,每日万字更新。

扎根山东,报道中国。省级媒体速豹新闻网,是根据国家互联网信息办公室管理规定,由山东省互联网信息办公室批准、省委网信办主管的,具有一类新闻采编发布资质的重点新闻网站。

阳煤化工,潞安化工,化工股份,化工销售,有限公司,官网,化工,化肥,商城,农资

河南省智迅精密机械有限公司

嘉兴南洋职业技术学院

青岛路博建业环保科技有限公司(www.qdlubojy.com)是一家专业的烟尘烟气测试仪厂家,有机挥发物检测仪厂家,公司现设立专业的技术服务团队,为客户提供一对一式服务,欢迎来电洽谈。

从江中明珠到十朝都会,从一牛吼地到鹰击长空,从小型公司到规模企业。昨天领跑恒温恒湿行业,赶路、赶路再赶路;今天争做国内一流厂商,跳出、跳远加跳高。

网站描述

佛山市鑫晨照五金制品有限公司佛山五金加工生产设备,发挥外发五金加工的优势,实现可持续发展。

江都人才网提供江都人才市场最新信息,为江都人提供江都人才招聘服务,江都人才网作为江都很好的人才招聘网站将努力打造成更好的江都人才市场,成为更好的江都人才信息发源地。

美颜祛痘网提供祛痘产品排行榜10强,快速祛痘方法,排毒祛痘的好方法,青春期如何祛痘,5-15天除痘痘印方法。


7月11日消息获悉,QQ小程序功能自6月份上线,成为第七个拥有小程序能力的平台,日前,针对其特有的产品基因及未来发展规划,QQ制定了小程序精品化政策,微信小程序第三方平台阿拉丁为本次QQ小程序精品化计划的邀请码官方授权机构,目前,QQ小程序采用定向邀请制,只有获得官方邀请码的小程序才可入驻,在本次合作中,阿拉丁和QQ官方将从小程序运营...。

近年来,中国在科技方面进步神速,隐然已有与当今科技强国并驾齐驱之势,而高铁、支付宝、共享单车和网购更是被并称为中国的新四大发明,成为中国建设成就的一大佐证,并陶醉其中,但,科技日报,总编刘亚东却不以为然,在6月21日,,是什么卡了我们的脖子?亟待攻克的核心技术,科学传播沙龙上,他表示,大国论,为时尚早,中国需要更多反思我们的科技缺的到...。

重庆餐饮企业具备专业化的物流体系、人性化加盟运营支持和火锅口味改进,在国内美食行业中一直都是一个翘楚,签王之王串串小吃的出现,是人们对火锅食品有了全新的概念,原来美食还可以这么吃!凭借着多样化的吃法与健康饮食模式,签王之王串串迅速在市面上聚拢一批又一批美食爱好者,受到大家热烈追捧,那么,签王之王串串味道怎么样,菜品多吗,签王之王串串味...。

排骨中含有丰富的蛋白质成分,经常食用对身体健康有着很大的帮助,因此市场需求量一直都很可观,让创业者们看到了其中的商机,桥头排骨小吃是小吃行业中备受欢迎的品牌之一,自2011年在市场中成立以来,已经在市场中稳定的发展了13年的时间,凭借着不错的美食风味,俘获了广大消费者的青睐,成为了加盟商所关注的品牌,那么桥头排骨小吃有哪些加盟优势,宣...。

威马去年巨亏82亿元,创始人沈晖年薪12亿元是李想800多倍9月25日消息,威马汽车此前披露的招股书近日引发关注,威马在2019,2021年间亏损额持续增加,其中2021年巨亏82亿元,而2021年,威马创始人、董事长兼首席执行官沈晖薪酬总计12.6亿元,占威马同年收入47亿元的近三成,另外两家造车新势力理想汽车与小鹏汽车的当家人李想...。

长久以来,就医排队时间长、检查时间长、交费时间长,一直被老百姓所诟病,再加上看病时间短,被戏称为,三长一短,随着互联网医疗、人工智能、大数据的兴起,不少创业者看到了,AI,数据,在提升医疗行业效率方面的潜力,张超也是其中之一,曾在百度工作五年,担任自然语言处理部资深研发工程师、文本知识挖掘方向负责人,对于,AI,数据,应该如何应用医...。
要闻提示今日头条阿里、雷军退股,车来了,,曾估值百亿,广告泛滥屡被投诉近日,国内实时公交产品,车来了,关联公司武汉元光科技有限公司发生工商变更,阿里巴巴,中国,网络技术有限公司、由雷军控股的北京顺为创业投资有限公司及旗下武汉光谷咖啡创投有限公司等退出股东行列,同时,公司多位董事发生变更,此前有观点认为,国人每次出行人数过亿,公交本身又...。

发表在专业问答2022,11,3017,15展示机型信息,品牌型号,坚果C7系统版本,Android9.0780ANSI流明作为家用投影仪的话是够用的,一般来说,家用投影仪的亮度在150,2500ANSI流明就是足够正常使用的,780ANSI流明的投影,如果在夜晚或者拉上窗帘的室内光线下进行使用,还是能够实现清晰的观影效果的,780A...。

服装,指的是衣服鞋包玩具饰品等的总称,多指衣服,服装在人类社会发展的早期就已出现,古代人把身边能找到的各种材料做成粗陋的,衣服,用以护身,人类初的衣服是用兽皮制成的,包裹身体的早,织物,用麻类纤维和草制等成,...。

国际金价的下跌趋势影响了北京市场的金饰品价格,使得当地商场的金饰价格普遍降至去年10月的水平,上周五,菜百商场和国华商场的千足金价格每克下调了12元,至225元,紧接着,中金黄金旗舰店的千足金饰品价格也从212元每克降至198元,这些商场表示,他们会根据国际金价的变化灵活调整价格,在上海,黄金交易所的Au9999收盘价下跌了6.10元...。

非法,只是在国际是比拟少见的,350Z是尼桑公司旗下车型,NISSANZ,Car系列的第五代,各项体现更为突出,在内外观设计或是能源功能上,都承袭了Z车系一向的设计与功能绝妙平衡的Z,DNA,成为NISSAN在时代最先端的梦境经典跑车,从2002年350Z上市,日产这一代Z系列跑车曾经面市将近10年,面对越来越残暴的竞争,日产开局思考...。

北京规范科技类校外培训预收费管理,收费时段不得早于培训开始前一个月,科技类,北京市,培训机构,校外培训,预收费管理
太平洋电脑网论坛要关了,此前知名的天涯社区、机锋论坛均已关闭,有混过的去看看吧太平洋电脑网论坛5月20日关闭入口,8月31日停止运营,无法访问、登录、发布内容、查看已发布内容,@万能的大熊说,之前听说有网友在他们论坛上留了一个片子的下载资源,后来被乐视发现了,告了侵权,赔了五百万,估计是为了安全,彻底关了算了,BBS论坛,曾经是汇聚无...。
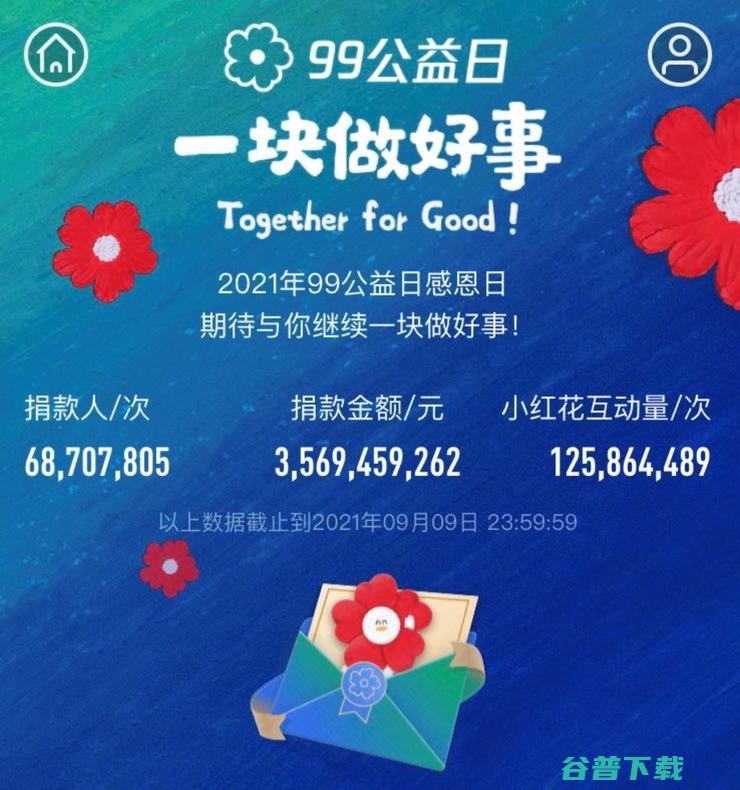
9月10日,为期十天的2021年99公益日暂告一段落,作为腾讯,共同富裕专项计划,的首期落地行动,今年99公益日在配捐机制、产品体系、企业联动、公益基础建设上全面升级,连接数亿网友、近万家慈善组织和爱心企业,将全民公益转化为参与共同富裕的力量,数据显示,今年99公益日的善行动员进一步触达社会各界,小红花互动人次超1.25亿,送小红花、...。

随着共享经济的蓬勃发展,网约车行业已成为城市交通的重要组成部分,然而,开设一家网约车公司并非易事,需要遵循一系列步骤和满足特定条件,本文将为您详细介绍开设网约车公司的全过程,包括关键步骤、必备条件以及相应的图片示例,帮助您更好地理解和规划,步骤概览1.工商局名称核准登记首先,您需要在当地工商局领取名称核准表,填写并申请制作公章,这一步...。

美国当地时间2024年1月9日,一年一届的CES展会在美国内华达州拉斯维加斯的会议中心如期举办,机器人作为2023年最为热门的赛道之一,其受关注程度不言而喻,展会上,割草机、扫地机、泳池机器人、配送机器人等各种产品层出不穷,争奇斗艳,其中,九号机器人首次在海外展示了室内配送机器人产品,九号飞碟,,而在,九号飞碟,的身旁,则是早已销往海...。

原神剧情1、提瓦特大陆上有着三大种族,区分是寓居在天空岛的神族、寓居在提瓦特大地上的人族和寓居在深渊的魔族,在五百多年以前有一个十分,平凡,的炼金术士发现了经过炼金术可以,复苏,某些奇怪的生命,随后他就应用这一技术手腕发明出了泛滥抗争机器,而这些抗争机器也就是起初游览者遇到的那些遗址守卫,2、很快,他就应用这些弱小的抗争机器建设起了一...。
