剑桥高级机器学习讲师Ferenc Huszár评马腾宇新作 它改变了我对上下文学习的思考方式 (剑桥gao)

根据 Ferenc Huszár 的介绍,他是在 ICLR 审稿期间阅读到马腾宇等人的这篇工作,觉得该论文所取得的成果十分引人入胜,并进行了深入思考。
ICLR 2022 在去年11月公布初审结果,马腾宇团队有3篇工作入选,《将上下文学习视作隐式贝叶斯推理的阐释》(An Explanation of In-Context Learning as Implicit Bayesian Inference)便是其中之一。

马腾宇与Percy Liang分别为斯坦福大学计算机系的助理教授与副教授,是人工智能领域的著名新秀,都曾获得斯隆研究奖,其研究工作受到同行关注。

的专访介绍,马腾宇主要从事人工智能基础理论的研究工作,课题覆盖非凸优化、深度学习及理论等等。这篇被 ICLR 2022 接收的工作也是从理论出发,研究上下文学习/(In-Context Learning)与隐式贝叶斯推理之间的关系。
当前,gpt-3等大规模预训练语言模型进行上下文学习的表现惊人:模型只需基于由输入—输出示例组成的提示进行训练,学习完成下游任务。在没有明确经过这种预训练的情况下,语言模型会在正向传播过程中学习这些示例,而不会基于“分布外”提示更新参数。
但研究者尚不清楚是什么机制让上下文学习得以实现。
在这篇论文中,马腾宇等人研究了在预训练文本具有远程连贯性的数学设置下,预训练分布对上下文学习的实现所起到的作用。在该研究中,对语言模型进行预训练需要从条件文本中推断出潜在的文档级别概念,以生成有连贯性的下一个标记。在测试时,该机制通过推断提示示例之间共享的潜在概念,并应用该概念对测试示例进行预测,从而实现上下文学习。
他们证明了:当预训练分布是混合隐马尔可夫模型时,上下文学习是通过对潜在概念进行贝叶斯推理隐式地产生的。即便提示和预训练数据之间的分布不匹配,这种情况依旧成立。
与自然语言中用于上下文学习的混乱的大规模预训练数据集不同,他们生成了一系列小规模合成数据集(GINC),在这个过程中,Transformer 和 LSTM 语言模型都使用了上下文学习。除了聚焦预训练分布效果的理论之外,他们还实证发现,当预训练损失相同时,缩放模型的大小能够提高上下文(预测)的准确性。
Ferenc Huszár 是剑桥大学计算机系的高级机器学习讲师,对贝叶斯机器学习有深入的研究。2016年与2017年,他在基于深度学习的图像超分辨率与压缩技术上取得两大突破(如下),谷歌学术引用了超过1万4。

Ferenc Huszár 对马腾宇等人的工作给予了高度评价。AI科技评论对 Ferenc 的点评做了不改原意的整理:
我喜欢这篇论文,因为它与可交换性(exchangeability)相关,这是我最喜欢的概念和想法之一。它让我想起了我在2015年(当时还处于深度学习的发展早期)的想法——利用可交换序列模型实现大规模通用学习机。在那篇旧博文中,我对可交换模型做了如下思考:
老实说,在我读到马腾宇等人发表的这篇论文之前,我从来没有把大型可交换序列模型视作通用学习工具的动机和使用GPT-3进行上下文学习的最新趋势联系起来。事实上,我对后者深表怀疑,认为它本质上就是必然存在根本缺陷的另一种黑客行为。但是这篇论文将这些点都联系起来了,这也是它为什么如此吸引我的原因,因为我永远无法想到“提示黑客行为”和上下文学习竟然完全一样。
1)将可交换序列作为隐式学习机
在探讨这篇论文前,让我们先来温习下关于可交换序列和隐式学习的已有概念。
可交换序列模型是一个序列概率分布

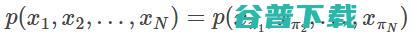 中,对于任意一个置换 π,该分布都是对标记的置换不变量。
中,对于任意一个置换 π,该分布都是对标记的置换不变量。
de Finetti 定理将这些序列模型与贝叶斯推理联系在一起,假设任意分布都可以分解成混合独立同分布(I.I.D.)序列模型:
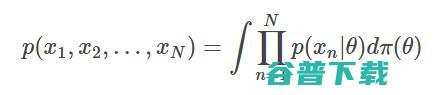
因此,前一步的预测分布(用来预测序列的下一个标记)总能分解成贝叶斯积分:
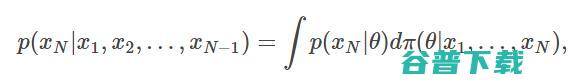

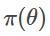 计算得到的贝叶斯后验,计算的贝叶斯公式为:
计算得到的贝叶斯后验,计算的贝叶斯公式为:
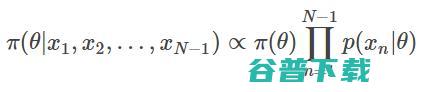
在这种情况下,如果我们有一个可交换序列模型,就可以将这些前一步的预测分布视作隐式执行的贝叶斯推理。关键是,即便我们并不知道θ个 π 是什么,以及可能性
 是什么,也能实现这一操作。我们不必明确指出公式的这些组成部分是什么,de Finetti 定理都能够确保这些组成部分都存在,而只需要让预测
是什么,也能实现这一操作。我们不必明确指出公式的这些组成部分是什么,de Finetti 定理都能够确保这些组成部分都存在,而只需要让预测
 与可交换序列模型保持一致。
与可交换序列模型保持一致。
这一想法驱使我通过构建这一模型,来尝试设计总是能够产生可变换分布的循环神经网络(当时Transformer 还没有出现)。最终证明这种想法很难实现,不过这一想法最后衍生出了 BRUNO(名字取自Bruno de Finetti)这一工作。

BRUNO 是一个用于可交换数据的灵活的元训练模型,拥有小样本概念学习能力。这个想法后来在 Ira Korshunova 的博士论文中得到多种方式的拓展。
2)从可交换序列到混合隐马尔可夫模型(HMM)
但GPT-3是一个语言模型,很明显语言标记是不可交换的,所以两者联系是什么?
伴随着de Finetti 型定理出现了一些引人关注的泛化成果,可交换性的概念也出现了一些有趣的扩展。Diaconis、Freedman(1980)等人定义,偏导可交换性(Partial exchangeability),指的是能确保序列可被分别为混合马尔可夫链的序列分布的不变属性。因此,可以说,使用偏导可交换过程对马尔可夫链进行贝叶斯推理,与使用可交换过程对独立同分布(I.I.D.)数据生成过程进行推理的方式非常相似。
马腾宇等人在这篇论文中,假设使用的序列模型是混合隐马尔可夫模型。这比 Diaconis 和Freedman 提出的偏导可交换混合马尔可夫链更具泛化性。
我不知道是否混合隐马尔可夫模型能用可交换性此类的不变性来表征,但这不打紧。实际上这篇论文根本没有提及可交换性,其关于隐式贝叶斯推理的核心论点是:每当使用由简单分布组成的序列模型时,可以将前一步的预测阐释为“对一些参数隐式地进行贝叶斯推理”。虽然互联网上人类语言的分布不太可能遵循多观察隐马尔可夫模型(Multi Observation Hidden Markov Model,MoHMM)分布,但假设GPT-3输出的序列可能是混合隐马尔可夫模型的某些部分,这种说法就是合理的。并且如果真是这样,预测下一个标记就会对一些参数(作者所指的“概念”)隐式地进行贝叶斯推理。
3)上下文学习和隐式贝叶斯推理
这篇论文的核心思想是,也许上下文推理能够利用这种与语言统计模型密切相关的隐式贝叶斯推理来解决问题。语言模型能够学习隐式地对任何概念进行概率推理,因为要想在预测下一个标记的任务上表现得好,就必须进行这种推理。如果模型具备这种隐式学习能力,那它就能够操纵这种能力去执行其他同样需要这种推理的任务,包括小样本分类等等。
我认为这是一个非常有意思的泛化想法。 但令我稍感遗憾的是,作者聚焦的关键问题是特定性和人为性: 虽然多观察隐马尔可夫模型可以用来“补全”从某个特定的隐马尔可夫模型(混合组成部分的其中一个)中提取的序列,但如果让多观察隐马尔可夫模型补全它们根本无法直接生成的序列,例如一个人为构建的嵌入了小样本分类任务的序列,会发生什么?这就变成了一个分布不匹配的问题。
论文关键的发现在于,即便这种分布不匹配,多观察隐马尔可夫模型中的隐式推理机制也能够识别正确的概念,并且能在小样本任务中使用这种分布来做出正确的预测。
这一分析为嵌入序列中的上下文学习任务与多观察隐马尔可夫模型分布的相关性,做出了强有力的假设(具体细节请阅读原论文)。从某种程度上来说, 作者研究的上下文任务,与其说是一个分类任务,不如说是一个小样本序列补全任务。
总而言之,这是一篇值得思考的、有意思的论文,它显著地改变了我对整个上下文学习以及将语言模型训练成小样本学习工具的研究方向的思考方式。

版权文章,未经授权禁止转载。详情见 转载须知 。



站长工具ICP备案可通过域名、备案号、公司名称查询备案信息,备案信息有域名、备案主体单位(个人或公司)、备案号等,还展示备案企业工商信息、该单位当前备案、注销备案及备案历史信息。

{{lay.base.description}}

辽宁鑫恒电科技有限公司是一家集发电机组研发、生产、营销服务为一体的大型企业,专业经营10kw-2000kw发电机组、柴油发电机组、上柴发电机组、玉柴发电机组等实力厂家!

广东信与水性涂料有限公司|紫外光固化涂料|油墨|水性工业防护涂料广东信与水性涂料有限公司(以下简称广东信与)成立于2015年,是一家专业从事水性涂料研产销及服务的技术型企业,涉及产品包括紫外光固化涂料、油墨、水性工业防护涂料,目前具备3000吨/年的生产能力。

卫多多,生活用纸,卫生用品,卫生纸,餐巾纸,抽纸,电子商务

浙江宁波辰宁新风系统主要生产除湿机,工业除湿机,除湿设备,冷风机,冷气机,水冷风机等新风除湿设备,公司拥有二千多平方米仓库。

上海栎晖商贸有限公司是一家致力于泵阀、轴承、气动元件、编码器、减速机、以及管路等液压产品和进口机械零部件销售的公司

江苏省新沂市华洋金属制品有限公司成立于2008年8月,注册资金200万元,现有员工150人.

指画游戏平台

山东撒母耳金属制品有限公司主营:防辐射铅门,防辐射铅板,硫酸钡砂,硫酸钡板,手术室气密门,铅房,铅玻璃,铅箱,铅砖,铅棒,铅丝等产品,欢迎来电采购

佛山新固铝业有限公司前身成立于2009年,21年专注,只做好铝材!21载铸造,荣耀与辉煌!是高端家装门窗铝材行业的开拓者之一!2万平方的现代化铝材航母生产制造基地!型材连续多年出口欧美、非洲、中东、东盟等50多个国家和地区!新固铝材是国内较早研发出隔热断桥铝型材、断桥纱窗一体窗铝型材、瞩目全国。作为铝型材行业的杰出品牌,新固一直致力于铝合金门窗的研发,以其出色的开发能力和精湛的工艺技术及优质的服务

工机窝,工程机械租赁网,二手工程机械网,工程机械配件网,工程机械展会,工程机械,挖掘机,推土机,平地机,冷再生机,路拌机,压路机,铲车,强夯机,摊铺机,铣刨机,液压夯


虽然公众号很多人一直在唱衰,但是还是有不少人涌进来做公众号,那为什么他们一直在唱衰呢,其实就是没有掌握好方法,那下面给大家简单地分享一下如何快速起号,我们都知道,公众号是相对比较封闭的,如果没有刻意的去引流,你写了一年估计也才一两百个粉丝,甚至是更少,那很多人会选择利用知乎这个平台去引流,把自己写好的公众号文章,同步到知乎上面,但是知...。

鲜花的用途甚广,它不仅仅可用于各类的节日聚会,也可以用于情侣之间的互表爱意,当然这些仅仅是用于礼品行业,那其实,鲜花亦是室内装修点缀的重要物品,有很多消费者在家居装修的时候会选择一些花卉插花来点缀空间,从而令家居空间变得更具有品质化,更有格调……广阔的用途令创业者产生关注,那么现在鲜花加盟连锁哪个好,鲜花加盟市场大吗,可一起来探究,鲜...。
文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为雅虎广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在雅虎广告联盟网站首页底部或友情链接位...。

发表在峰米投影仪2022,10,2113,59峰米S5激光投影仪是峰米最近新上市的限定版家用激光投影仪,它拥有小巧轻薄的机身,流沙金的外形高级而美观,具体来看,峰米S5激光投影仪的各项参数性能怎么样呢,作为家用投影仪是否值得入手,接着我们来一起详细了解一下,1.光学参数在光源方面,峰米S5激光投影仪采用的是ALPD激光显示技术,应用在...。

发表在米家投影仪2023,11,1009,46小米投影仪青春版2S是青春版2的升级版本,在画质和性能配置方面都有所提升,具体小米投影仪青春版2S参数配置怎么样呢,下面就来详细了解一下,看看小米投影仪青春版2S特点有哪些,具体优缺点分别有哪些,小米投影仪青春版2S参数配置,1.画质上在亮度方面,小米投影仪青春版2S的亮度达到500ANS...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。

2017年办副卡时明白通知我,副卡不收取月租,发生的流量费跟通话费,从主卡上扣,结果用了几个月副卡没有经常使用,但从操持副卡至今发现,中国移动每月从我主卡上扣28块钱,我的主卡素来没有收就任何副卡生产信息,包括他们每月收这28块钱,我咨询本地移动营业厅,他通知我,这是套餐费用,经过我查问网上APP下面显示扣的副......。

拜登口误称说泽连斯基为普京财联社7月12日讯,编辑赵昊,外地期间周四,7月11日,,美国总统拜登在一场北约优惠上错将乌克兰总统泽连斯基称为,总统普京,,引发剧烈争议,视频显示,拜登在资讯颁布会上宣布讲话时曾经产生卡顿、声响模糊,并且在引见泽连斯基时说了两次,总统普京,PresidentPutin,过后,优惠现场还响起了难堪的掌声,...。
12星座出世月份如下,1、水瓶座,1月20日,2月18日,2、双鱼座,2月19日,3月20日,3、白羊座,3月21日,4月19日,4、金牛座,4月20日,5月20日,5、双子座,5月21日,6月21日,6、巨蟹座,6月22日,7月22日,7、狮子座,7月23日,8月22日,8、处女座,8月23日,9月22日,9、天秤座...。

一台单梁起重机的多少钱大略两万元左右,在选用购置之前,多方面地启动了解和对比是必要的,电动单梁起重机是一种轻小起重设施,在工字钢轨道上运转,有电动和手动之分,重物挂在其上,比拟便捷,吊车500吨一台多少钱徐工的自08年11月由徐工个人重型机械公司自主研发的500吨全低空起重机成功装配并在上海宝马工程机械博览会上向全国用户亮相后,徐工第...。

山西忻州貂蝉故里自由行_万里游侠客_新浪博客,万里游侠客,

三网免挂码支付系统二维码收款免签支付全开源1.2版本注意:没有搭建教程,注意:没有搭建教程,注意:没有搭建教程这个系统不是很完美,需要自己二开修复,看了下代码有些已经加密了免签CK跟**都是在本地的不是云端的,不...

油炸食品,在市场上很受欢迎,各种食材经过腌制之后,放入油锅中进行油炸,双面金黄色,加入调味料,品尝起来,口感香脆、美味,所以说产品非常热销,炸鸡叉骨相信大家都吃过,味道香脆可口,加上多种口味,可以满足顾客不同口味需求,如此以来,选择加盟这个项目,就可以获得较大市场,那么,炸鸡叉骨加盟费多少,分析如下,炸鸡叉骨加盟费多少炸鸡叉骨属于小本...。

发表在联想投影仪2024,10,1709,16联想LK203是百元价位的投影仪,内置有智能系统,具体联想LK203投影仪怎么样呢,下面就分享联想LK203投影仪的详细参数配置,看看联想LK203投影仪优缺点有哪些,是否值得用户入手,联想LK203投影仪怎么样,1.光学参数在亮度方面,联想LK203的亮度达到800流明,整体亮度表现不高...。

发表在专业问答2021,8,518,08展示机型信息,品牌型号,峰米4K激光家庭影院Max系统版本,FengOS峰米激光电视是在广东深圳生产的,峰米科技是由光峰和小米合资创办的,使用的激光光学引擎技术由光峰科技提供,而系统内容资源是由小米提供,公司总部在北京,产品生产在深圳,峰米激光电视是哪里生产的峰米激光电视在广东深圳生产,而峰米科...。
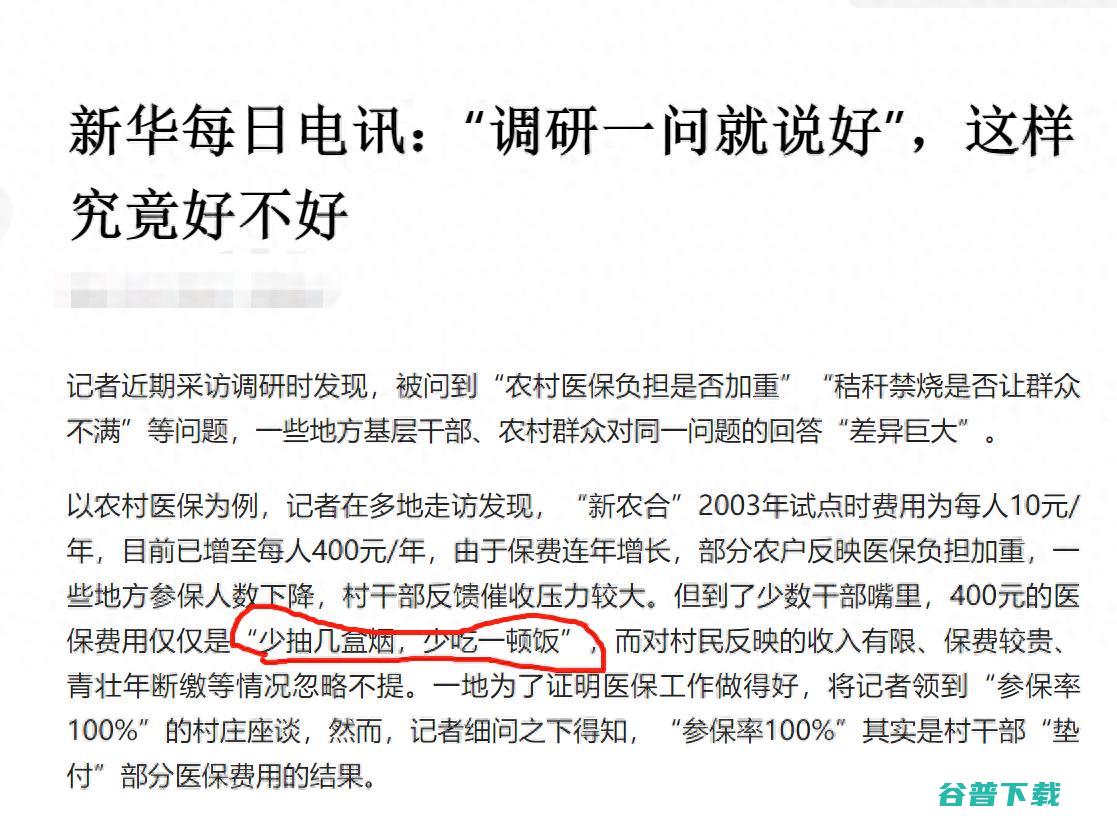
今天,新华每日电讯发了一篇文章,调研一问就说好,,这样究竟好不好,,主要谈的是农民比较关的事,比如农村医保、秸秆禁烧、基层问题反馈等,可以说,所有的内容都说到了农民的心坎上,比如,在谈到农村医保之时提到,新农合,2003年试点时费用为每人10元,年,目前已增至每人400元,年,由于400元的费用对于农民来说还是相当高了,为了筹集费...。

[全球时报记者丁雅栀全球时报特约记者任重]据美国,政治资讯网,报道,随着特朗普在2024年美国总统选举中获胜,拜登政府正在加紧与英特尔、三星电子等芯片公司谈判,敲定,芯片和迷信法,中的最终协定,力争在特朗普入主白宫之前坚固这项拜登任内的标记性产业政策,思考到新旧政府将在明年1月实现交接,关于仍在谈判环节中的20多家公司来说,接上去的两...。
