为什么能走出一家AI制药公司 北大的这个交叉研究院里 (为什么能走出不同于西方的现代化之路?)
在清华建校110周年庆祝大会上,北京大学校长郝平首次宣布,在人工智能教学和科研上,双方将联手建立通用AI实验班。
这意味着,这两家互为榜样,互相调侃多年的对门邻居,在人工智能上首次选择了并肩站队。
而事实上,在多年时间里,两所高校内部的姚班、图灵班已经先后培养和孵化出众多AI界的顶尖人才和创新企业。
仅以北大为例,先后走出了百度CEO李彦宏、前360首席科学家颜水成、微众银行首席人工智能官杨强等一众顶尖大佬。
在人工智能领域也是领头的北大,2002年成立了智能科学系,该系也是北大在人工智能领域最主要的机构,主要从事智能感知、机器学习、数据智能分析等方向的基础和应用基础研究,侧重于理论、方法以及重大领域应用上。
其曾参加多项国家级重大科研课题和横向应用研究项目,如国家重大科技攻关课题、国家重点基础研究发展规划(973)课题、863重大科研课题等30多项科研项目;先后获得重要科技奖励20多项:
其中指纹自动识别技术先后获得国家科技进步二等奖和教育部科技进步一等奖,以该项成果为基础建立了国内最大的指纹技术产业;人工神经网络说话人识别新方法的研究获得教育部科技进步一等奖;国家空间信息基础设施关键技术研究获得2000年中国高校科学技术二等奖,入选2000年中国高校十大科技进展等。
此外,北大又宣布成立了人工智能研究院。研究方向包括人工智能数理基础和认知科学基础、智能感知、机器学习、类脑计算、人工智能治理以及智能医疗、智能社会等方面。
而在最近爆火的AI制药赛道,也有一家由北大系创立的AI企业,正在逐渐崭露头角。
2021年5月,英飞智药宣布完成由丽珠制药和同创伟业领投的Pre-A 轮融资,此外在新药研发中充分利用并持续发展先进的AI药物发现技术,打造了自主知识产权的AI+新药研发平台——智药大脑TM。智药大脑是集顶级专家人才、一流AI+新药研发平台、前沿药物设计方法一体的药物发现系统。
在这家企业的背后,其创始人裴剑锋博士便是北大前沿交叉学科研究院定量生物学中心的研究员,此外,其联合创始人徐优俊和张伟林也分别是北大前沿交叉学科研究院定量生物学中心的博士和整合生命科学博士。
近日,雷锋网《医健AI掘金志》以“AI制药·下一个现象级赛道”为题,邀请华为云、西湖欧米、英飞智药、宇道生物、燧坤智能五家AI制药新秀,举办了一场线上云峰会。
作为此次活动的演讲嘉宾,英飞智药首席科学家张伟林,以《人工智能与新药研发》为题,对英飞智药的管线布局,以及AI平台做了介绍。
张伟林表示,最近几年,生命科学的一些原创性研究正在加速积累,包括靶标机制、新靶标结构以及检测和表征方法,都取得了突飞猛进的进展;而下游产业端也在愈发成熟,例如CRO,就将许多任务做得非常优秀。
但医药行业目前还存在一个关键性问题,就是“新分子发现与转化效率不足”,也就是当新靶标还处于早期阶段的时候,很少有人真的敢去提前进行布局。
这也导致我们原创药和医药产业整体处于落后地位。一个药物在临床之前,因为化合物结构已经确定,适应症也已经确定,所以药物发现过程,很大程度决定一个药物能否上市,能否创造价值,可以看做是整个行业最重要的命脉之一。
药物设计最重要就是要找到未被满足的临床需求。所谓临床需求,更多是要从患者角度来考虑,做出来的药物才能更有市场,我们目标具体定量来说,就是缩短研发周期,提高研发成功率。
对于分子对接来说,首先需要准备靶蛋白结构。当然生物体也有一个特质,就是同样功能可能会有同样折叠方式,当没有蛋白结构时候,也可以通过同源模建把结构模建出来(alphafold 2可以作到比较准确的从头预测)。
接下来是结合位点确认。在有的项目中,已经有复合物结构,也就明确了小分子结合位置,可以设计一个更好结构。
而有的时候,对于全新蛋白结构,其实并不知道配体是什么,这时就可以运行位点探测程序,例如CavityPlus程序,在表面进行探索。
接下来才是小分子对接,对接之后再对对接构象进行打分评价,进行体外细胞动物实验。
在这里我对计算机辅助药物设计,也就是传统CADD和AIDD简单进行一下比较。
CADD主要特点就是每一个工具和流程目标比较明确,而且通量整体也比较高,底层有物理化学规则支持。
人工智能辅助计算(AIDD)就需要定义一个目标,这个模型或者一套流程究竟要干什么,这需要好好规划,不然就会出现定义目标对选择框架太难的情况,最后导致罢工。
当然AIDD最好特点就是超高通量,我们也曾经做过超高通量实验,以分子对接数据为基础训练机器体系模型,发现这个模型速度能提高一百到二百倍,七八亿量级数据库,大约半天就能完成初步筛选。
以下是演讲全部内容,雷锋网做了不改变原意的整理和编辑:
首先感谢雷锋网给我们提供一个和各位线上朋友进行交流的机会。
首先介绍一下我自己,我本科专业是北京大学化学系,主要做的是物理化学;几年之后,又在北京大学前沿交叉学科研究院完成博士学位,在北京大学化学系做博士后。
2019年,我和几位创始人一起参与创立了英飞智药。
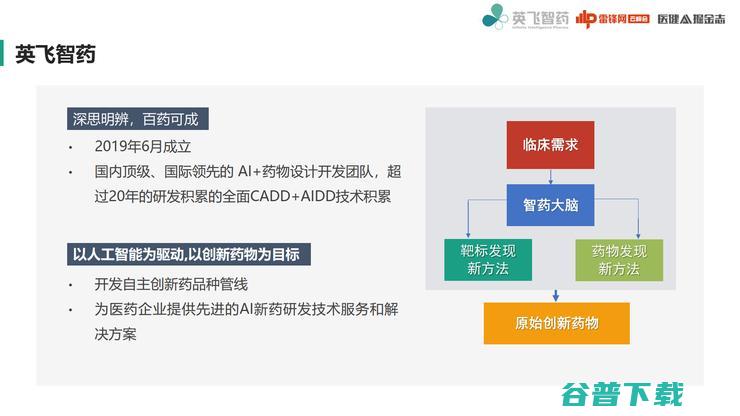
英飞智药拥有国内非常领先的AI+CADD的开发团队,之前做CADD已经有 大概20多年技术积累。我们的团队是由AI驱动,CADD作为支持辅助,一直在为新品种努力,主要是目前针对未满足的临床需求,努力发展靶标发现以及药物发现的新方法。
我们主要就是开发自主创新的药品管线, 争取获得一个原始创新药物,当然我们也会为很多医药企业和研发机构提供先进的AI新药研发技术服务和解决方案。
因为做创新药是一个非常复杂的过程,所以在这个过程中要非常深入和谨慎的思考一些事情,只有这样创新药物才能有可能做出来。
我们公司目前已经完成Pre-A轮融资,内部平台——智药大脑也已经上线,它包括了30多个药物设计的方法模块,以及实用药物设计流程。
同时公司已经开展自研创新候选药研发5项,4项已经完成设计工作,IIP-001A项目获得与上市药物可比的体外生物活性,IIP-003A项目的第一轮化合物体外活性数据,接近或超过阳参活性数据,我们还与多家机构进行早期创新药物研发合作。
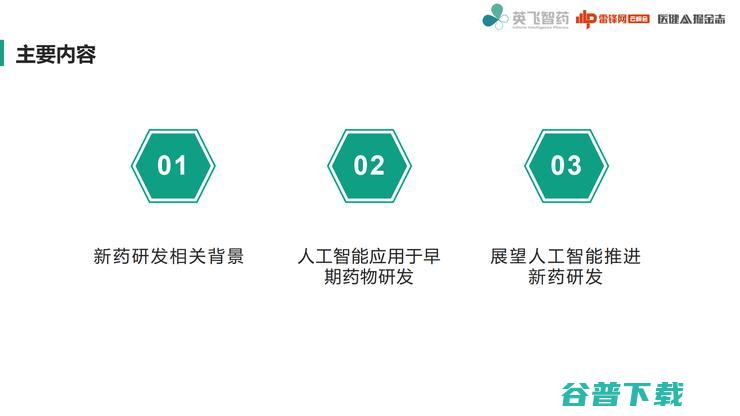
今天晚上的报告大致包括以下内容:
第一部分,新药研发的相关背景;
第二部分,介绍人工智能应用于早期药物研发的方面;
第三部分,对人工智能如何推进新药研发做展望;
首先有一个问题,我们在一个什么样的时代?
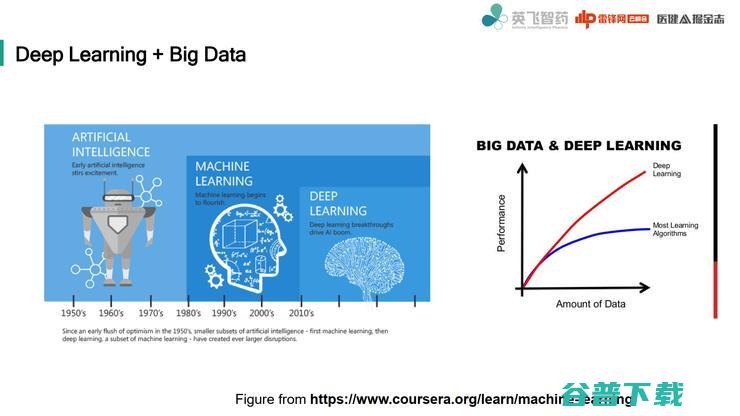
其实我们目前处于一个DeepLearning的时代,当它第一次出现的时候,大家还都会比较迷惑。
自从上世纪1950年提出人工智能这个概念之后,这个概念就一直往前发展,在1980年到2010年这段时间,就变成了机器学习,并且在这个时期提出的许多比较先进的机器学习算法,一直到现在还在使用。
而DeepLearning进入人们的视野是在2010年之后,因为随着计算技术提高,我们有能力做更大规模计算,同时我们也有更多的数据。
在更多数据面前很多以前learning算法的速度达到上限,而DeepLearning因为技术本身的优势,还能够继续往上提高速度,我们目前就处于这个状态。
接下来我们来认真地想一想究竟什么是learning?
对于学习,我们可以很简单认为,学习就是学会在接受刺激的时候该如何正确地产生响应。

例如开车过程,我们在开车的时候,会收到外界刺激信号,通过眼睛、耳朵以及身体去感受这些刺激信号,通过神经系统进行输出,最后用手和脚进行响应。
再比如自动驾驶技术,实际上是利用技术,利用不同感受器、摄像头、雷达以及定位等,让车子知道自己在哪儿,以及所处的环境,进而用机械来响应。
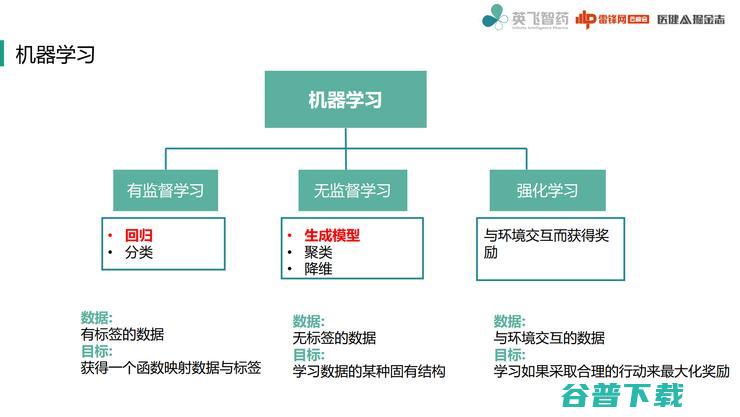
接下来看机器学习,目前主流机器学习有三种分类:
第一种有监督学习, 就是对一个数据进行连续数据映射和分类。
在这种情况下,我们获得的数据一般都是有标签的数据,实际就相当于我们考试题有标准答案一样,需要建立这样一个映射,能够映射数据标签。
第二种无监督学习。 无监督学习在机器学习的时代比较有两个比较著名的概念——聚类和降维。
目前Deep Learning比较火热就是生成模型,实际在无监督学习中,我们的数据是一些无标签数据,需要运用一些概率统计算法,然后对这些数据底层固有结构进行学习,然后基于这样固有结构,进行人为价值观判断。
第三种强化学习。 强化学习最重要的是与环境交互而获得奖励,比如说下棋,通过与人或其他机器进行对弈,然后获得奖励,奖励的标准可以就是这盘棋下赢了。
这里很重要的一点就是与环境交互数据,学习如何采取合理行动来最大化奖励,所以在学习过程中,最重要一个问题就是要好好设定学习目标到底是什么。
如果一个目标不切实际,或者这个目标和真实需求相差太远,学习模型往往只是徒劳而无功。
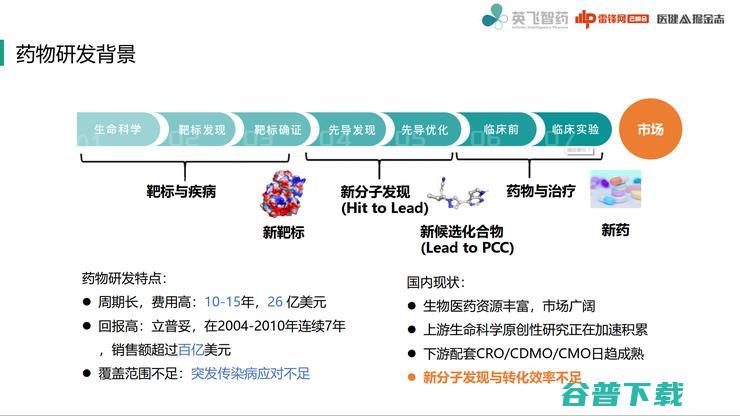
接下来简单说一下药物研发背景。
药物研发从现有研发流程来看,首先是要提出与疾病相关的靶标,再针对这些新靶标开展下一步工作,如果是小分子药物,就进行先导发现过程,发现有潜在活性的小分子化合物,这个时候,是否能够与靶标结合往往是最重要一点。
当把机制搞清楚之后,就可以向下一步候选化合物阶段发展,一般是优化小分子性质,例如生物活性、药代动力学性质、毒性安全性。
当化合物基本比较安全,性质也非常好之后,就可以开始往临床进行推;经过临床实验后,将化合物最终推向市场。
这样一套流程,最大特点就是研发周期长,费用也比较高,回报相对也比较高。
但在许多情况下,这样流程还有一些不足,例如应对突发传染性疾病,在这种情况下,如果没有预先准备,完全按照这一套来做,就会很慢。
我们作为一个国内的公司,自然要看一看国内新药研发的一个现状,目前国家生物医药资源实际上是非常丰富的,市场也是非常广阔的。
这几年,上游生命科学的一些原创性研究正在加速积累,包括一些新靶标、新靶标机制、新靶标结构以及一些非常优秀的检测方法表征方法都在很快的积累,下游工业化工作,例如CRO也日趋成熟,能够将交代的任务做得非常好。
但目前仍有一个关键问题新分子发现与转化效率不足,也就是对于新靶标,还很少有人敢去提前布局,新分子发现和转化效率仍然还是有所欠缺。
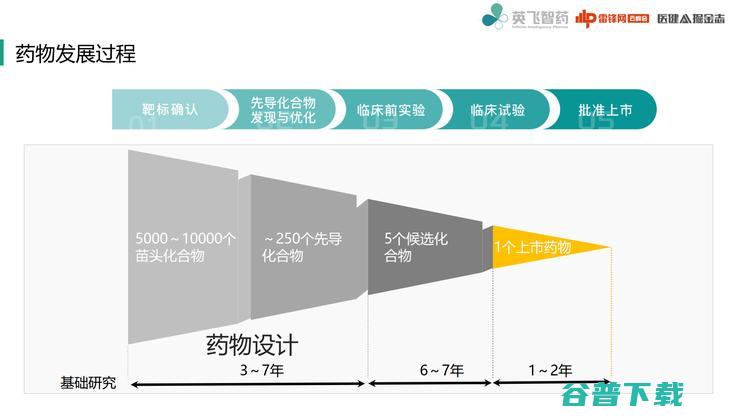
药物发展过程这张图大家都见过,实际是一个漫长的流程,算上生物过程,前期就需要3-7年。
一般得到候选化合物再往下走,从临床前实验到临床试验,都需要漫长的观察期,才能最终上市。
我们的创始人裴剑锋也曾提到过,一个药物在上临床的之前,因为这个化合物结构已经确定,要治的适应症也已经确定了,所以药物发现的过程其实就很大程度上决定了一个药物能否上市,所以精准的药物设计工作是要在非常早期就进行规划。
药物设计最重要就是要找到未被满足的临床需求。所谓临床需求,更多是要从患者角度来考虑,做出来的药物才能更有市场,我们目标具体定量来说,就是缩短研发周期,提高研发成功率。
药物设计有以下的一些主要方向:
第一,要找到创新靶标与创新药物,实际上这是一种对疾病的理解;
第二,作用机理要明确,如果作用机理不明确,很有可能药上了市后,出现意想不到的副作用;
第三,就是获取苗头化合物和先导化合物;
第四,优化先导化合物,这是目前大家都能看到的。
我们的智药大脑,实际是需要结合专家经验与先进人工智能、CADD技术以及各种药物信息技术,来帮助新靶标发现以及药物发现,来最终驱动原始药物。
在这个过程中,要严守物理化学科学规则,并发挥想象力才能更快成功。

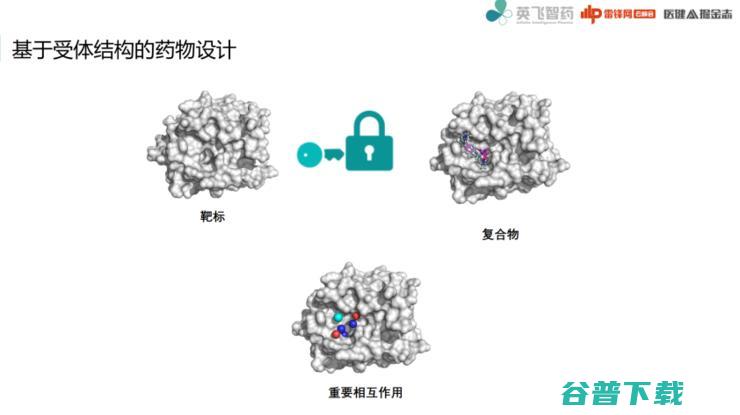
下面来介绍一个常见的例子,即基于受体结构的药物设计。
这里需要提一下锁钥模型概念:锁钥模型就是小分子化合物结合到蛋白表面的一个口袋,它们是一种互补的关系,可以通过晶体结构来获得一个复合物。
这个过程中,我们会抽象出一系列重要相互作用,再依据这些相互作用寻找新分子。这些重要相互作用表征得更好,那么设计效果也就越好。
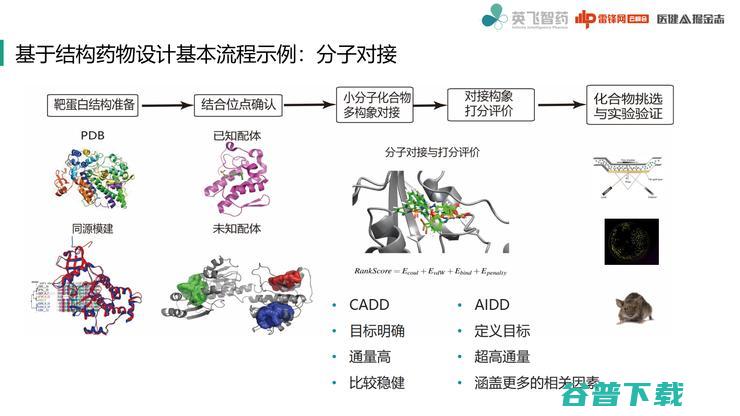
对于分子对接来说,首先需要准备靶蛋白结构。当然生物体也有一个特质,就是同样功能可能会有同样折叠方式,当没有蛋白结构时候,也可以通过同源模建把结构模建出来(alphafold 2可以作到比较准确的从头预测)。
接下来是结合位点确认。在有的项目中,已经有复合物结构,也就明确了小分子结合位置,可以设计一个更好结构。
而有的时候,对于全新蛋白结构,其实并不知道配体是什么,这时就可以运行位点探测程序,例如CavityPlus程序,在表面进行探索。
接下来才是小分子对接,对接之后再对对接构象进行打分评价,进行体外细胞动物实验。
在这里我对计算机辅助药物设计,也就是传统CADD和AIDD简单进行一下比较。
CADD主要特点就是每一个工具和流程目标比较明确,而且通量整体也比较高,底层有物理化学规则支持。
人工智能辅助计算(AIDD)就需要定义一个目标,这个模型或者一套流程究竟要干什么,这需要好好规划,不然就会出现定义目标对选择框架太难的情况,最后导致罢工。
当然AIDD最好特点就是超高通量,我们也曾经做过超高通量实验,以分子对接数据为基础训练机器体系模型,发现这个模型速度能提高一百到二百倍,七八亿量级数据库,大约半天就能完成初步筛选。
AI模型能够涵盖很多其他因素,而这些涵盖的这么多其他因素,如果直接编程,代码量会非常恐怖。所以,现阶段CADD和AIDD基本一起使用,才能够带来更好效果。
接下来介绍一个比较工具,这是多维度配体的虚拟筛选。
我们把这部分放在先导优化步骤,其实本身也是有争议的,因为它应该是介于发现与优化之间的这么一个工具,我们就先简单把它归在先导优化这里来。
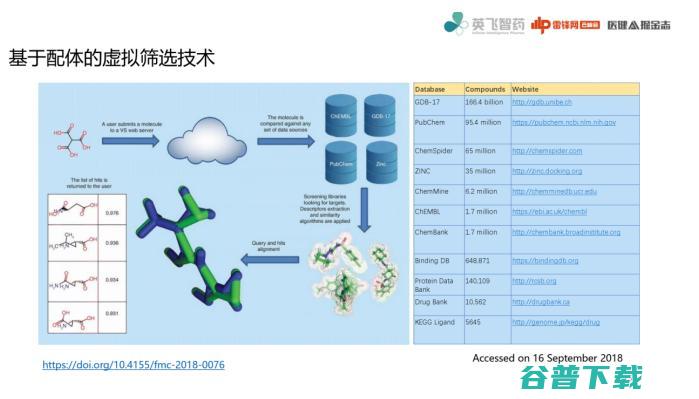
简单说一下基于配体的虚拟技术。
基于配体的虚拟筛选技术和我刚才讲的基于受体结构不太一样,这里实际上有一个假设:就是相似配体可以结合在相似口袋当中,也就是有可能钥匙不是原配钥匙,但也能开这把锁。
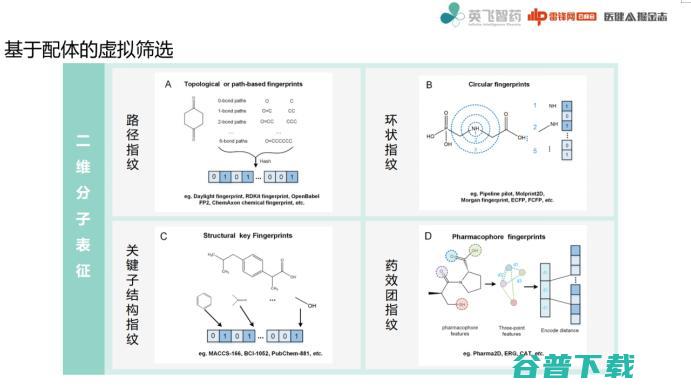
基于配体虚拟筛选技术的一个核心概念就是:相似分子需要相似性质,这涉及分子表征问题,即如何说明两个分子很像。
目前主流技术上会做分子描述符、二维分子表征和三维分子表征,核心就是度量问题。

分子描述符分为定量和定性两方面描述一个分子。
其中有很多性质可以来描述两个分子是否相同:例如最基础可以通过实验表征,比如光谱数据比较像不像,然后从结构式上就能看出氢键供体数目,物理化学性质。

对于二维分子表征,二维分子指纹是其关键特征,大概有几种类型:
第一,按照路径把它看成一个图,就像一笔画一样从一个点到另一个点,走怎样路径;
第二,就像剥洋葱一样,以一个点为中心在它周围画圈,再使用哈希方式对它进行指纹化处理;
第三,用一些方式直接找其中关键结构;
第四,药效团,它实际上更多的是把分子性质作为一个散列化处理。
除了二维指纹之外,目前也有人去设计三维分子指纹,三维分子指纹相比二维来说就会复杂一些。因为分子三维构象还比较多变,所以三维指纹目前用的还不如二维指纹多。
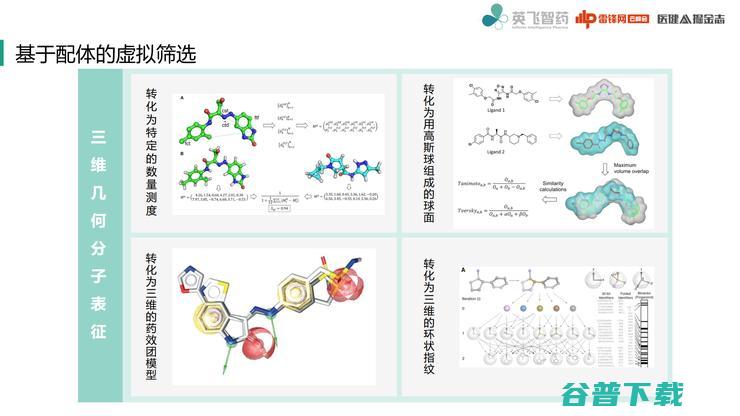
总结来说,AI多维度配体虚拟筛选,其实还有很多应用场景。
例如细胞实验,它可能比分子实验或生化实验更早建立体系,可以进行高通量筛选获得活性小分子,这可能并没有确定靶标或只有假设靶标,对于比较感兴趣的小分子,会进一步在大库里搜索。
这个时候如果用对接搜索,计算量会非常大,所以直接用基于配体搜索,就像我们用搜索引擎一样把它变成字符串搜索,就能很快得到相关度最高分子。

这是我们和合作者在去年发表的一篇综述,里面对一些分子指纹和基于配体的虚拟筛选提供一些总结,大家可以参考一下。
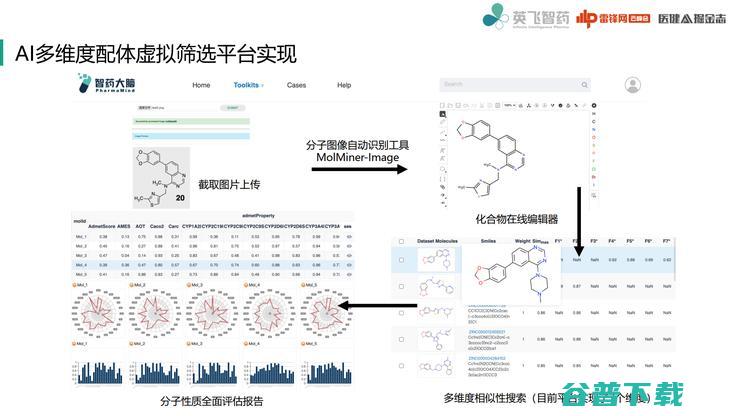
这是在我们平台上做的实现,我简单介绍一下流程。
这是非常常见的场景,例如我们在读文献的时候,发现一个化合物很不错,这时就可以通过截图方式把它用AI方式直接识别成一个计算机可读的分子格式,然后直接提交多维相似性搜索,最后对搜索结果用AI模型进行全面性质评估。
这个过程非常友好,因为我们在读文献的时候突然来了一个灵感,但非常不想打断灵感打开软件一点点画出来,只想赶紧知道究竟有哪些与它相似分子,在这个平台可以得到很快验证。
我们的多维相似性搜索,提供了一共7个维度来做这个事情。
为什么目前提供7个维度呢,因为我们也是做了模型training和调整,让函数整体表示相对比较平滑,不会出现分子指纹断层问题。
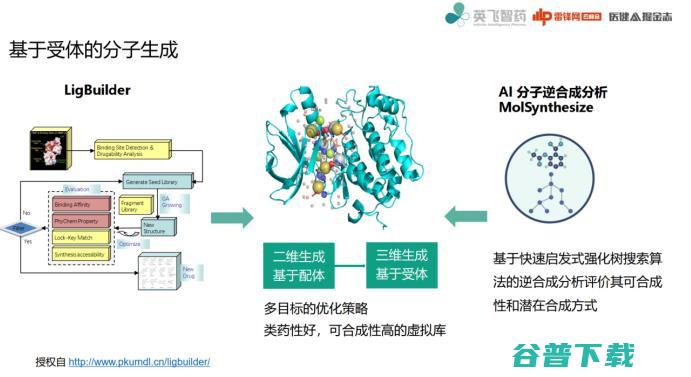
说完了基于配体的虚拟筛选,我们再来讲一下基于受体的分子生成。
分子生成是目前人工智能主要的发力点,不管是有监督和无监督学习还是强化学习,都会在这些上面进行发力。
因为分子生成是基于已有分子结构、已有活性,然后学习它们的性质,在这个空间附近扰动,获得新分子,这种情况下主要利用配体信息,也就是利用钥匙信息。
当然更多情况下,我们也可以利用锁信息,也就是利用受体信息对空间进行限制。
化合物空间实际上可能有10之多,但真正针对到某一个体系肯定不会有那么多,受体信息确定后,空间将被大幅缩小。
左边程序叫LigBuilder,是我们以前做基于片段的全新药物设计程序,它能够在完成全新药物设计以及多目标优化的同时,产生类药性很好,可合成性高的虚拟库。
右边是AI分子逆合成分析,是我们基于AI模型开发的逆合成方法,如果使用AI逆合成方式,结合全新药物设计,它的计算效率会有很好提高。

这个流程我简单说一下,这基本上就是我们分子生成的设计流程。
一般我们会根据项目需求,假设我们选择了进行基于结构靶标生成,就会先进行一轮生成,然后再基于活性进行优化,优化之后还要对它进行综合评估。
就像我们前面说的AI模型对于ADMET药物性质预测以及毒性预测,已经有比较好的效果。
基于现有数据对其中毒性片段会发出一些警示信息;对于某些影响性质片段也能够做一定指示。
总体来说,我们希望能够在项目早期得到性质比较好的分子,对后面一系列实验会有很大帮助。
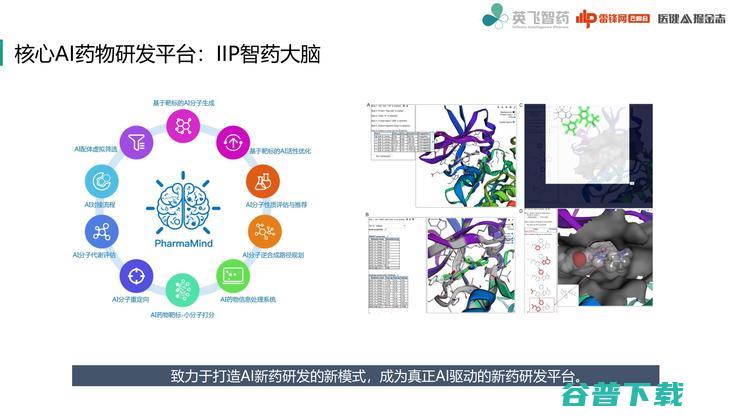
我简单介绍一下我们平台智药大脑。这个平台目前有很多个工具组成,需要CADD、AI、药物化学家、药理,还有生物靶标上游很多知识汇集。智药大脑本身是为大家提供了平台对话工具,是真正用AI来驱动研发。

接下来我来说一下我的看法。
首先,AI辅助药物设计这件事情,目前肯定是正在开启一个新的时代,它肯定能够让药物的研发更快,成本更低,效率更高,尤其是去年AlphaGo2横空出世,确实也给我们很大震撼,真的觉得AI能够帮到药物研发。
其次,制药工业在我们国家确实是进入换挡提速的过程,我们也紧跟国外创新药先进治疗方法,有些时候甚至是需要提前布局。
但目前AI还有很多问题,对于AI辅助药物设计这种方法以及实用性仍还存在问题。诸多瓶颈问题依然限制着AI方法和技术在创新药物研发中的应用,目前多数AI辅助药物设计方法和系统的实用性仍需努力。
智药大脑最后完成之后,还需要大家一起来评价,不是简单的AI模型堆砌,而是针对实际新药研发问题应用场景,开发和整合多个底层AI药物研发工具和工作流程。
它本身就是集成了很多业界认可的一个药物设计工具,底层很强调基于物理原理的科学解释和对生物学机制的理解。
我们也希望智药大脑能够已经被业界认可的计算机辅助药物设计工具,提供基于物理原理的解释,为医药企业和药物研发机构研发自主知识产权创新药物提供完整实用的解决方案。
 最后是整体总结和展望。
最后是整体总结和展望。
药物研发本身肯定是非常复杂极具挑战的过程,因为周期比较长,所以这个过程中任何一个失败都很难接受。所以AI的技术发展,为整个制药行业提供了一个新的机遇,当然挑战也是有的。
目前来看,主要就是在每一个环节和模块上,都有很高不确定性,对这些不确定性,我们能够提供更多证据链来尽可能降低不确定性, 例如:
Q&A问答环节
Q1:请教一下,您觉得目前做业务的核心壁垒在哪里?
张伟林: 我们国家最近也在做交叉学科的布局,以前我们交叉学科研究院已经有过一些实践。
其实不同领域的人面对的问题难点是不一样的。
比如我以前是做计算模拟,其实到现在还是觉得有些IT问题对我来说是一个问题,但这些问题对于IT专业人员来说觉得不是问题。
Q2:AI发现出来的药物最大的难点是在分子合成砌块?
张伟林: 我觉得这不一定是最大难点,因为可以结合比较简单反应来做,这一点我们和有机化学家如果能够有充分合作,和他们进行交流,有机合成到底应该是怎么做。
以前都是从前往后设计,到最后反馈合成出问题就前功尽弃,对于写算法的人来说,他可能没有专业知识,他没写这些限制,所以最后就会出问题,所以分子合成砌块我觉得并不一定是最大的难点,但确实是一个比较重要的点。
Q3:如何看待AI用于晶型预测剂型这两个环节的价值?
张伟林: 还是非常有价值的,因为晶型预测和剂型预测,以前只能通过实验来做,但目前这个领域可以用AI来进行处理。
晶型其实定义更广泛一些来说,它其实是材料范畴,物理化学规则更严,所以说它能够获得很好数据,也能够很好反馈到上游。
Q4:用AI筛选的药物如何平衡活性与毒性?
张伟林: 这件事情我们可以做这样一个假定,假定靶标本身没那么大毒性。
因为但靶标处在复杂的生物网络中,那么稍微干预一下靶标,可能整个网络系统都坏了,这也就意味这个靶标毒性很高,那治疗窗口就比较窄,这种情况下有可能应该换靶标或者使用靶标组合。
所以如果靶标选的好,它的治疗窗口就会比较宽,活性和毒性平衡也就会比较容易,所以靶标一定要慎重考虑好好选择。
Q5:AI研发到达成熟估计得多久?
张伟林: 这个问题其实很难回答,因为比如初代Alpha fold跟同期一些程序相比优势还不是特别明显,但到下一代集成很多专家、数据以及算力之后,就达到非常高的水平。
这其实是一个迭代过程,所需要用到的资源可能不是一个小单位能够负担得起,当然目前国内一些课题组做得都非常好,也开发出一些非常先进的工具,但我们还需要继续向人学习。
我举个简单例子,虽然Alpha fold2对于一些本身结构比较好的蛋白,它已经能够做一个预测,但要说真的解决结构问题,还需要做实验。
所以AI药物研发达到成熟需要多久,我觉得会一直在路上,因为现在一些算法本身到了一定程度以后就不更新,可能就需要等它成熟以后,五年甚至十年才能知道这件事情,来告诉我们答案。
张伟林: 还是很多数据来源的,例如公开数据来源、自有数据来源等都很重要,但最重要还是如何理解这些数据质量控制,质量控制是最重要保证。
如果一个数据量很大,里面什么数据都有,例如在某一个靶标活性里面,把各种各样东西甚至是没法比较东西都放在一起就会很麻烦。
Q7:AI平台physics-based modeling比较其他模型有什么优势呢?
张伟林:AI平台操作里一个特点就是有物理原理在里面之后,其实可以通过其他物理原理来对它进行检验,也就是可解释性是非常好,这是physics-based modeling本身的一个特质。如果别的AI模型,具有理解这种底层进行划分的话,同样可以很好。
Q8:英飞目前有哪些产品和管线呢?
张伟林: 目前我们的产品主要是智药大脑这个平台,供内部使用,也相当于是不断打磨内测过程;然后还和我们一些合作伙伴进行应用场景探讨。
Q9:请问英飞有大分子药物的管线吗?
张伟林: 我们主要部署管线是抗病毒癌症方向,当然大分子也有很多好处,大分子本身特异性还蛮好的,如果我们经费再高一点,计算资源多一点,大分子药物我们也会考虑去做,但目前我们并没有计划在大分子药物上进行布局。
Q10:我是在校计算化学学生,最近也在自学CS,您介绍基于配体分子筛选-多维度相似性搜索,其中将文献中结构式识别成电脑能懂的语言,是需要通过图像识别算法去实现吗?
张伟林: 觉得广义上主要看你想怎么做,就是具体用什么算法来实现这个目的,而且还是要看算法能不能满足最终目的。
图像识别算法实际上是可以的,就是文献结构中识别为电脑能懂的,图像识别还是个蛮不错的算法,因为可解释性更好。
Q11:请问像英飞这样的AI辅助药物研发公司的商业模式是怎样的?
张伟林: 主要商业模式是这样,我刚才提到我们是以创新药为最终目标,所以我们致力于开发一个用AI技术平台,基于平台驱动开发创新药物产品管线。
但新药研发的流程很长,所以也会和其它单位进行合作,大家一起做确实能够形成优势互补。
Q12:请问在治疗疾病方面,大分子药物与小分子药物哪种应用更广?哪种更有前景?
张伟林: 治疗疾病这件事有时候诊断更重要,因为诊断对了之后,用对了药才会有实际效果,如果诊断不对的话,实际很难讲存活率和效果。
例如癌症5年存活率,例如PD1响应率,这些成功率都还在于对疾病机理的理解,也就是一个疾病还没有清楚原因的时候,很难讲选择什么样的路径。
但大分子本身就是因为本身比较大,性质比较稳定,所以基础性质比较好,小分子好处在于生产比较容易,保存比较方便,所以很难讲哪个更有前景,应该是并重的。
原创文章,未经授权禁止转载。详情见 转载须知 。


国家广播电视总局

金正大生态工程集团股份有限公司成立于1998年,主导产品为复合肥、缓控释肥、水溶肥及其它新型肥料,是全球最大的缓控释肥生产基地。现有总资产110亿元,员工10000余人,年生产能力600万吨。2010年,公司在深圳证券交易所上市(股票代码002470)。2014年实现销售收入135.5亿元,同比增长13.03%,利润总额10.53亿元,同比增长29.2%。

换链神器是一款专门针对站长、SEOer开发的友情链接交换、购买交易平台,集友情链接交换、买卖、监控于一体的站长平台;目前友情链接平台入驻超过【20W+】网站,日均在线友情链接交换网站近3万余家;解决了站长友情链接交换过程中资源对接不集中,不及时的问题,大大提升了友情链接交换工作效率。

江西盛炜化工科技有限公司


DESCRIPTION...

TNT121是汇集全网各种分类的优秀内容和网站入口,为大家提供最便捷简单的上网导航服务,让您的网络生活更简单精彩。上网,从TNT121开始。

鑫浪信息科技主要致力于数码防伪技术和企业数字化管理软件的销售和服务,主营产品有一物一码,防伪标签,防伪码,防窜货系统,二维码营销,微商管理系统等产品。在食品、医药、保健品、婴童产品、烟酒、日化、快消品、电子电器、IT、图书、农资、养殖业等众多行业深得客户的青睐与信任,为产品的质量安全提供完美服务和保障。

旅游交易平台,旅游企业,旅行社,酒店宾馆,景区,旅游用品,旅游新闻,旅游商机,旅游营销,旅游人才

云会议,全球高清云视频会议协作工具!轻松起会,便捷入会!可提供安全无缝的视频通信,助力用户实现更多目标。网络参会,电话参会,轻松选择。

香港卓越事務所設立於香港,敝所業務非常國際化,客戶遍及全球各地,我們曾為不同地區的客戶提供法律意見及服務,必是閣下可信賴的選擇。

三星手游网为您提供手机游戏、安卓手机软件下载,通过分类免费下载排行榜前十名游戏软件推荐可以安全装到手机上,所有安卓软件apk和手游均来自官方,是您装机必备的软件下载网站。


在卡通农场游戏中,抓捕青蛙是一个有趣且有策略性的玩法,小编就来介绍一下卡通农场青蛙怎么捉,其实捉青蛙的话还是需要几个小方法法来进行配合的,接下来小编会分享列具体的步骤,帮助大家在游戏中成功捕获这些跳跃的小生物,但是大家一定要保证自身的等级,确保围栏解锁,先来介绍一下青蛙在游戏中的出现机制,青蛙通常会在水域附近出现,所以确保农场有足够的...。

5月15日,追觅科技在苏州举办,满分之选,全球新品发布会,共发布了两大系列六款重磅新品,包括H20系列的H20Pro旋锋版、H20Ultra旋锋版、H20UltraMix、H20UltraStation,以及H30系列的H30Ultra旋锋版、H30UltraMix,此次发布的洗地机新品,搭载了包括,主动式0缠毛系统,100°C沸水...。

发表在专业问答2024,11,1709,00展示机型信息,品牌型号,哈趣Q1系统版本,当贝OS定制版哈趣Q1看电视直播可以通过安装电视直播软件或者通过手机投屏进行观看,下面为哈趣Q1怎么看电视直播的详细步骤做具体说明,哈趣Q1怎么看电视直播方法一,直播软件观看1.安装咪咕视频通过U盘在哈趣Q1上安装咪咕视频手机版;2.切换鼠标模式在哈...。

对于广大上上班族来说,每天工作时间比较忙,无休时间短,只能在工作的地方解决用餐,因此经济实惠,方便快捷的快餐成为人们日常用餐的主要选择,随着市场需求不断地增加,市场中的快餐品牌不断增多,东方快餐是一个历史悠久的连锁快餐品牌,一直专注于快餐领域,凭借先进的餐饮理念,舒适的用餐环境,好的员工服务,赢得广大消费者的认可,同时也赢得不少创业者...。
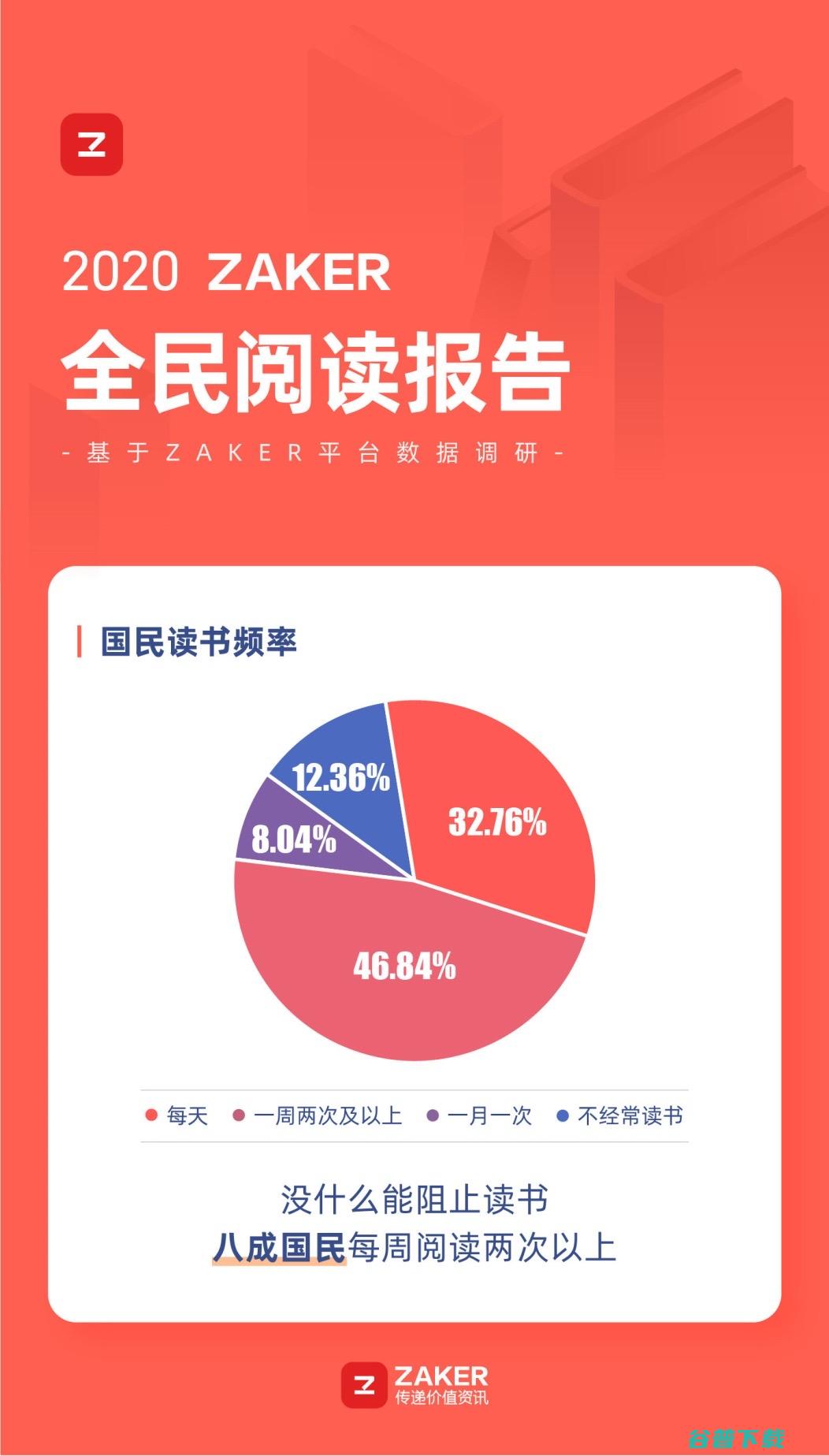
一个人养成了读书的习惯,大概就是给自己营造了一座避难所,在书中可以暂时忘却世界中的痛苦,令生命被无限延长,经历过疫情,读过毛姆的,阅读是一座随身携带的避难所,,大概能真切体会到阅读真正的意义,4月23日世界读书日,ZAKER发布,2020全民阅读报告,以下简称,报告,,并连续推出第三季,领读中国·生命的光辉,全民公益阅读活动,...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。

据美国,商业内情,网站10日报道,外地时期7月9日,美国前总统特朗普在其借鉴的社交平台,假相社交,Truthsocial,上发帖称,假设他在往年11月美国总统选举中获胜,那么一些,选举作弊者,将被送入监狱,帖子特意提到了美国社交媒体巨头Meta公司首席口头官马克·扎克伯格,特朗普的帖文写道,他们不知羞耻!我只能说,假设我入选总统,...。

Industry的意思是工业,读音,英[ɪndəstri],美[ɪndəstri]释义,工业;产业;行业;勤勉;勤劳例句,Thetouristtradehasbecomearealindustry.旅行业曾经成为真正的产业,双数,industries短语,wineindustry酿酒工业inindustry在工业方面promotein...。

独活男性的介绍,独活男性的介绍,改编自朝井麻由美的同名随笔作品,是由及川博则执导的电视剧,本剧以,享用独身生存,为主题,江口饰演探求,独身活,的出版社员工五月女恵,,独身活,意为,踊跃地享用团体期间的优惠,在剧中五月将只身一人去到各种中央,享用宝贵的团体期间,演员引见江口纪子,江口のりこ,本名江口徳子,1980年4月28日出世...。

推荐a实名认证Yes直播软件,which软件/No/。未使用实名认证游戏软件未使用实名认证/,有没有直播-0认证宽松手游直播现在几乎没有平台,现在都需要实名-2。1、斗鱼直播必须要身份证吗?您好,很高兴回答您的问题。在浏览了相关文献后,我总结了以下对斗鱼直播的要求,希望对你有所帮助。第一,你要有斗鱼直播的稳定房间,也就是说,你要有斗鱼的房间。你必须年满18岁,这也是一个硬性要求。因为未成年人担心被犯罪分子利用,所以必须是第三个成年人。他们承诺并声明,在向官方斗鱼提供服务时,应遵守法律的规定,不得以履行本协


2月15日,有数码博主曝出了黑鲨5系列新机的参数,而且信息非常丰富。作为新一度热门游戏手机,还是值得期待的,下面一起来看看黑鲨5手机最新消息以及参数配置,黑鲨5手机最新消息黑鲨5手机参数配置信息

在币圈最近Plustoken卷钱跑路到处抛售比特币的消息被闹得沸沸扬扬的,Plustoken这次搞的这个骗局,被骗人数100万,涉及金额超过200亿路,可谓目前在币圈最大的一次是金融骗局了,近几年,随着区块链及比特币的知名度上升,币圈也被认为是一个,风口,,再加上很多人其实根本不懂区块链这玩意,只知道可以赚钱,被人一忽悠,就开干了!因...。

现在我们所使用的手机大部分都是智能手机,在我们的手机上,应该有很多朋友下载了手游软件,在软件商城,有各种各样的手游软件,龙创手游是其中的一款,龙创手游设计的好玩刺激,用户下载量很大,一些对手游感兴趣的创业者想要加盟,但是,龙创手游加盟条件,加盟龙创手游多少钱,龙创手游品牌公司是一个互联网科技品牌公司,品牌公司位于我国的福建,在公司运营...。

雷锋网按,一个新技术从提出到成熟往往要经历多次热潮,当下热门的AI正是如此,纵观整个AI的发展历程,可以分为三个阶段,目前,AI正在从2.0阶段发展到3.0阶段,此时,重要的一环就是神经拟态计算取得的突破性进展,而这又需要在两个方面发力,今天距离人类最初探索外太空已经有51年之久了,1969年,美国宇航员阿姆斯特朗踏上了月球表面,他的...。
索尼A9G系列通过U盘安装软件看电影视频教程,索尼A9G电视当贝UI版安装当贝市场教程1、打开索尼电视A9G找到,设置,菜单,进入选择,应用,功能,找到,安全与限制,,将,安装未知来源,设为允许,2、在电脑下载安装当贝市场,拷贝到U盘,当贝市场下载地址,请点击此处下载,3、将U盘接入电视USB接口,系统会显示U盘已连接,点击,确定,...。

清乾隆时名医家杨开泰我们诸暨古代名医家除了南宋杨文修.明朝戴思恭外,清季有名的还有杨五德和杨开泰,杨开泰,字万新,先后师事萧山谢.沈两治麻名家,杨开泰融合两家之说为一体,辑为<,郁谢麻科合璧>,是书活人无数,后世尊为治疹之宝典,屡经翻印,我于今年间偶得于贵州遵义市区一旧书摊,初或以为是一般医书,细阅后竟发现为我暨邑先人所著,...。
