研究院王超岳 优必选悉尼 AI 基于生成对抗网络的图像编辑方法 (中科院王越超)
雷锋网 AI科技评论按,近些年来,生成对抗网络在许多图像生成和图像编辑任务上都获得了很大的成功,并受到越来越多的关注。对于图像编辑任务,现在面临的两个重要的挑战分别是:如何指导网络向目标图像学习(以提升图像编辑的效果)和如何感知输入图像内容(以提升图像编辑的精度)。
悉尼科技大学 FEIT 三年级博士生,优必选悉尼AI研究院访问学生,陶大程教授学生王超岳在雷锋网 AI研习社主办的学术青年分享会上结合他的两篇论文 Tag Disentangled Generative Adversarial Networks for Object Image Re-rendering (IJCAI 2017 Best student paper)和 Perceptual Adversarial Networks for Image-to-Image Transformation (arXiv 2017),分享了对图像编辑做出的相应探索。
分享内容如下:
常见的图像编辑有图像去雨(雪)、图像填充、素描到照片、风格转换、图像超分辨率、图像上色、图像旋转、时间变换等,抽象来说就是给定一张图像以及要求,来生成新的图像。即让机器理解图像和生成图像。

生成对抗网络是由Goodfellow在2014年提出的,算是一种新的网络架构,可以做有监督或无监督的学习。

基于GANs的图像编辑框架如下所示:

接下来介绍第一篇论文,用于图像转换任务的感知对抗网络(Perceptual Adversarial Network,PAN)。

近两年基于GANs的框架,有很多不同的优化,下图是对Pixel-wise loss、GANs loss和Perceptual loss的对比工作。


Pixel loss优点是使用简单、训练速度快、稳定,缺点是输出图像模糊,质量低。
GAN loss优点是能提升生成图像质量,更加真实,锐利,缺点是学习整体生成分布,无法单独使用。
Perceptualloss优点是注重图像包含的高维特征,感知效果,缺点是受限于预训练的其他网络。

下面是对提升生成图像质量做出的一些研究,引入不同的loss来生成不同的输出图像。

他们希望有新的loss函数来弥补现有的问题,持续缩小生成图像和真实图像的差距。基于这样的想法提出了感知对抗损失。

使用感知对抗损失的理由如下:
感知:衡量生成图像和真实图像的高维特征的差异,并致力于缩小他们。
对抗:当现有高维特征的差异小于一定数值m ,D网络被更新以寻找新的高维空间,以进一步缩小仍存在的不同。
统一:所有训练统一在一个GAN框架中,无需引入其他预训练网络,且不受任务限制。

他们引入感知对抗loss加GAN loss的结构,在这里引入GAN loss来让生成图像的整体分布符合真实图像的整体分布。

下面是针对于这个网络的相关实验,主要有图像的去雨、从分割后的label的图像到街景的重现、卫星图到谷歌地图的转换、图像补全、素描生成真实图像的任务。

下面是对比图像去雨雪的任务,他们的模型在色差的控制等方面都有所提升。

下面是图像补全任务,对比CVPR 2016的Context Encoder,PAN能得到更加优化的效果。

进行Pixel2pixel实验时与pix2pix做了对比,也可以看到明显提升。

解决图像生成的质量之后,还有一个问题:intERPretable。也就是如何解开神经网络的黑箱,并帮助计算机进一步理解图像。

针对于如何在图像转换过程中理解整个网络,并控制中间层信息的表征,他们提出标签分解生成对抗网络(Tag Disentangled Generative Adversarial Networks, TDGAN),用于进行目标图像的再次渲染(Re-rendering)。

给定输入图像,里面会包含一系列的输入信息,人脑看到之后很容易分理出这些信息,但之前的网络很难理解这些信息,因此很难对输入图像进行精细编辑,现在他们想要让网络能更进一步理解这些信息。


他们提出分解表征法。

解决方案:标签。只要简单的改变标签,就能很容易生成微笑的图像。


基于此,他们提出TDGAN,包括下图四个子网络。

网络的框架图如下:

主要有f1、f2、f3、f4四个约束项:




这四个子网络采用如下交替训练的形式:




下面是工作相应的实验结果,给定单张椅子,给定一些想要的角度,可以生成不同角度的效果,另外可以生成人在不同光线及表情下的效果。

下图是他们在两个数据集下做的一些任务。可以通过给定单张椅子照片,生成不同角度的椅子;也可以控制输入人脸图像的多种性质,如改变其角度,光照,表情等。






总结如下:现有的很多方法都是在GANs的框架下,希望提升现有的图像编辑效果和提升图像编辑的精度,他们做了以下尝试,去让任务表现更好。
第一是从学习的层面,不再只是从像素层面或固定高维空间上去缩小真实图像和转换图像之间的不同,而是利用对抗学习的思想去持续寻找并缩小真实图像和转换图像之间尚存的差异。另一方面,他们希望算法可以更深入的理解图像,并帮助计算机能更加智能,通过提取和分解图像中包含的各种信息,让算法可以更精确的编辑图像,从而得到想要的结果。

Perceptual Adversarial Networks for Image-to-Image Transformation
论文地址:
Tag Disentangled Generative Adversarial Networks for Object Image Re-rendering
论文地址:
本次分享的视频如下:
雷锋网 AI科技评论整理编辑。
原创文章,未经授权禁止转载。详情见 转载须知 。



迷彩虎是一档融合游戏、影视和动漫元素,集专业性与娱乐性于一体的科普节目。

重庆巨宇勘察测绘有限公司

苏州新鑫净化设备有限公司(www.gdzijing.com)主营不锈钢货物风淋室,实验室水平工作台,小型不锈钢除尘器,不锈钢垂直工作台,磨床单机除尘器,车间净化钢质门等产品,公司拥有完整、科学的质量管理体系,欢迎各界朋友莅临参观、指导.


上海手机号码在线选号,上海手机靓号免费申请、上海手机卡选号大厅、电话卡网上申请办理。上海移动、联通、电信无限流量卡、腾讯大王卡、阿里宝卡、移动大王卡,电信星卡申请办理官方入口,打造号码行业生态系统。

炫游攻略网是一个分享网游、手游、单机游戏玩家提供最新/最全的游戏资讯、攻略、活动内容的综合服务平台,内容涵盖手游攻略,游戏攻略,游戏资讯,游戏排行,手游排行耪,热门游戏等内容

纵横智控将传统行业基础设施与物联网、边缘计算、AI等新技术相结合,为行业数字化转型集成商提供边缘计算网关、IOT数据中台、HMI、远程IO、AI边缘盒子等产品及解决方案,提质增效、优化流程,推动行业数字化转型

华西法兰是不锈钢法兰,管件(弯头,三通,大小头),锻件,风电轴的生产厂家。法兰连接有304不锈钢,碳钢,对焊,平焊,螺纹;管件有对焊,弯头,高压,无缝,螺纹,钛管件;锻件有不锈钢,风电轴,环形;弯头有45度,90度,180度,无缝,对焊,合金;三通有异径,焊接,高压,无缝,t型,合金;大小头有偏心,同心,不锈钢等。

求职、招聘选择九一人才网,每天提供真实有效的招聘信息,力求帮助企业与求职者搭建可靠的招聘渠道。

郑州市第十一中学,河南省首批示范性高中。

五粮液防伪官网


利用火柴棒进行各式各样的数学运算,虽然大家看上去比较的简单,但实际上如果想要完成这些关卡还是有很大难度的,热门的火柴棒游戏盘点,小编找到了一些和火柴棒有关系的解谜和推算类型的游戏,大家需要运用自己的智慧,然后尽可能的破解更多的关卡,在这些游戏里面的难度是不一样的,在最开始的关卡难度会比较低,然后后续的关卡难度会大幅度的提升,到后面会越...。

近日,海康威视举行投资者问答会议,海康认为,企业数字化转型的市场空间很难量化,但可以确认的是,但凡希望过得更好,竞争力更强的企业,都需要做数字化转型,EBG市场空间很大,海康此前的判断正在得到验证,另外目前也没有一家公司走在前列,海康正在往这个方向走,一方面,安防竞争会进一步加剧,大量尾部厂商会退出,市场进一步集中,其他产业也符合这个...。

上周,叮当健康成功登陆港交所,发行价为12港元,股,叮当健康,即叮当快药,曾以,28分钟送药上门,的slogan闻名,但从去年6月传出上市消息以来,叮当健康一直不怎么被看好,5年亏损近29亿元的业绩表现是原罪,而最根本的硬伤则在于,巨头扎堆的互联网医疗领域,叮当健康标榜的,快,已不再是拿得出手的优势,缺乏流量支撑的叮当健康,在互联网巨...。

发表在哈趣投影仪2023,11,113,172023年双十一第一轮尾款冲刺迎来卫生,作为千元LCD投影仪头部品牌哈趣,全渠道热卖,强势登顶各大平台榜单!哈趣投影在LCD投影仪赛道蓄力,凭借哈趣H2、哈趣K1Pro等多款产品,卖爆全网,为万千用户带去优质画面大屏智能体验,在双十一活动中,哈趣斩获多项荣誉,在天猫渠道LCD投影品牌增速第一...。

撰文丨余晖7月13日晚,唐山市纪委监委延续颁布了4人被查的信息,地下资料显示,谷守军常年在唐山市委组织部上班,曾负责唐山市委组织部部务委员、唐山市委组织部副部长兼考核办主任、市政府参事,往年7月3日,他还地下出面,杜佳,男,汉族,1981年6月出世,河北省唐山市人,地下资料显示,他2004年6月参与中国共产党,18岁,1999年12月...。

网易文娱3月24日报道春日已至,正是少年们的踏青好季节,由爱奇艺出品的春日郊游露营体验综艺,春日酱,的宣传片和主题曲同早春一同如约而至啦!网友们纷繁示意,看完瞬间感遭到了满屏的春日荷尔蒙,开局等候这场春日游览,春天可以怎样过,春日酱,来通知你——骑行兜风、拍摄美景、享受春日美味、沐浴春风、邂逅浪漫,春日少年们一同到来重庆,继续捕...。

Copyright©1996,2021SINACorporationAllRightReserved新浪公司版权一切隐衷包全新浪公司版权一切京ICP证000007违法和不良信息揭发电话,4000520066揭发邮箱,jubao@vip.sina.com京网文,2017,10231,1151号互联网资讯信息服务容许编号,11220180...。

在日语中,,日产,被写成,NISSAN,,而,尼桑,则是其中文音译,实践上,,日产,是中国市场对,NISSAN,的称说,而,NISSAN,是该汽车品牌在中国市场选用的意译,因此,,尼桑,实践上是,日产,的中文音译,NISSAN汽车,NISSAN汽车在中国被称为,尼桑,,其实这是日语中,日产,的中文音译,它的官网解释含意为,以人和汽车的...。
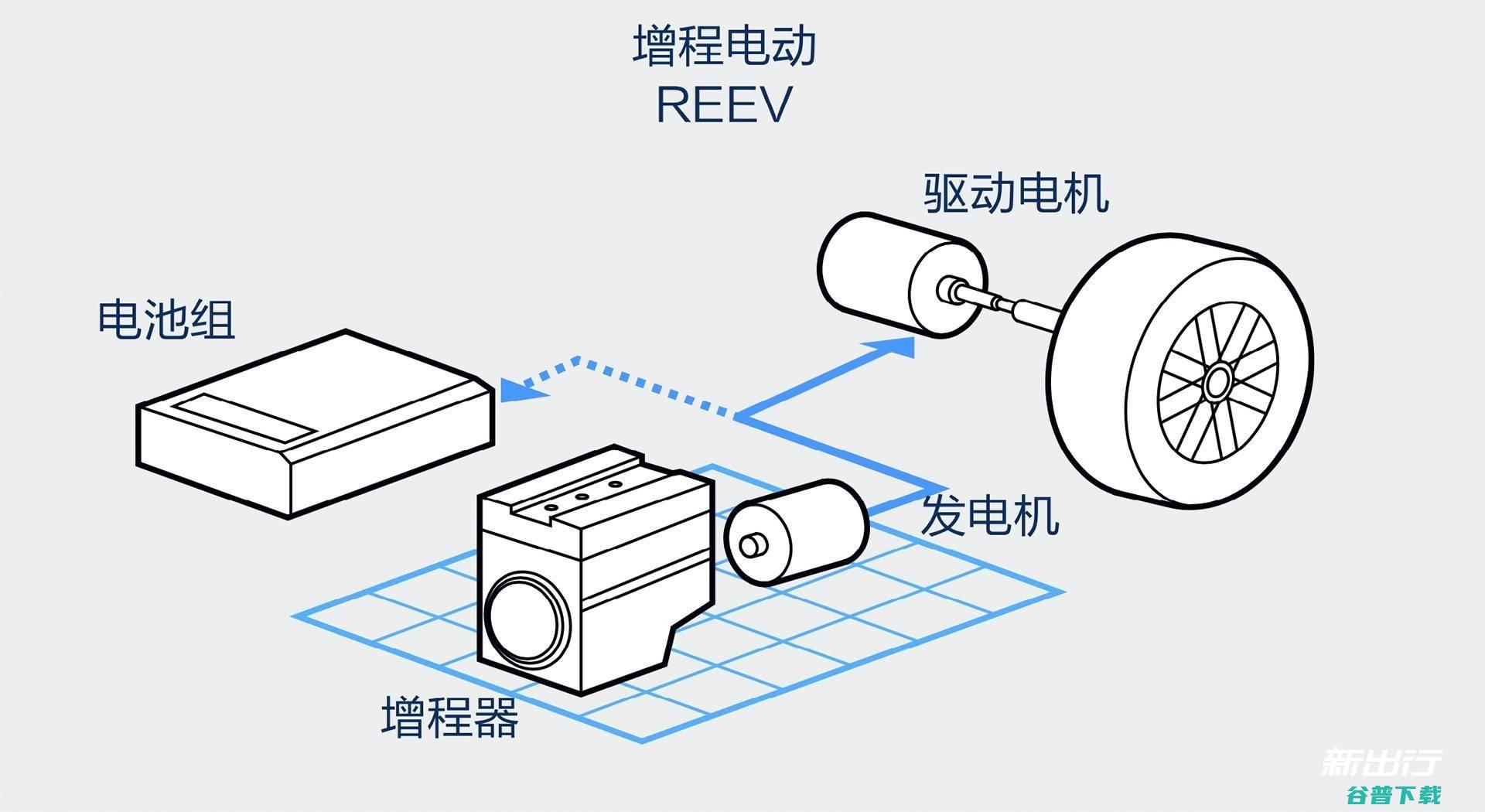
有车以后新车新闻,近日,西风奕派官网发表,eπ007将于3月14日上市,目前新车已开启大定,售价区间15.96,23.46万元,一句话点评eπ007,有一台性能、性能拉满的,六边形兵士,,且提供纯电,增程两种动力打算,不论你是燃油死忠,还是纯电信徒,它都能满足你的需求,长处,1、外型拉风,可选剪刀门,电动尾翼2、轴距近3米,车内空间...。

winscp是什么软件?它是一款在windows系统下使用的sftp客户端,同时支持scp和ssh两种协议。winscp中文绿色版主要功能就是在本地和远程服务器之间进行文件的复制、编辑、删除等操作。软件也可以连接linux系统。使用教程1.此版本为绿色版,无需安装,解压出来后,找到

中望3D2024中文破解版是先进的3D绘图软件,使用旨在为用户带来更加灵活的设计以及快速的加工,更轻松的方式来处理各种复杂的设计

upupoo动态桌面壁纸,upupoo动态桌面是一款电脑动态桌面软件,又译为啊噗啊噗,可以将视频设为桌面壁纸,upupoo软件也收集了动漫、舞蹈、神曲、风景等大量的视频壁纸资源,全视角动态桌面,交互桌面,改变对传统桌面的认知,并且保证永久免费使用。,您可以免费下载。
相信非常多的小伙伴在日常生活中都十分喜欢听歌,今天小编将会为大家带来音乐播放软件哪个最好推荐,在现如今音乐软件越来越多的情况下,想要选择一个好用的音乐软件是十分困难的,无论是软件的使用还是歌曲的版权都是小伙伴们需要考虑的问题,下面就随着雄安边一起来看看都有哪些软件的推荐吧,相信喜欢听歌的小伙伴们对于这款音乐软件都是十分的熟悉,在现在市...。

我想,通过一年时间的积淀,博客应该可以做广告了吧,目前各种联盟广告不是我的博客投放对象,利用自己的关系,去找人拉一些广告应该不是很困难的事情,另外,用我得再次好好研究研究googleAD还能不能给我创造价值!来源,卢松松博客QQ,微信,13340454本文地址,https,lusongsong.com,blog,post,20.h...。

昨天看了王自如的采访视频,这两天刷了很多屏,董小姐在旁边听着,洋溢着少女般的微笑和忧郁的眼神,王自如从一个潮气蓬勃的热血青年,怀揣着理想和信念,短短几年就成了今天这个油腻的形象,不禁让人唏嘘,你们是不是认为王自如虚伪、油腻、可笑呢?我觉得王自如非常清楚自己在做什么?那我告诉你,他现在不需要在更新微博了,也不用更新手机评测了,更不需要看...。

为什么都是用手机拍的抖音,别人就能做出炫酷特效?而你苦思冥想半天,短视频还是平平无奇?其实,一切创意皆有套路,抖音、快手上很多粉丝百万、千万的头部IP账号,绝大部分也是用手机拍摄的,手机拍摄短视频方便、便捷,随用随拍,如果只是制作一个几十秒或者几分钟的短视频,一部手机真的足矣,只要你掌握了正确的手机拍摄短视频技巧,本文将从4个方面来详...。
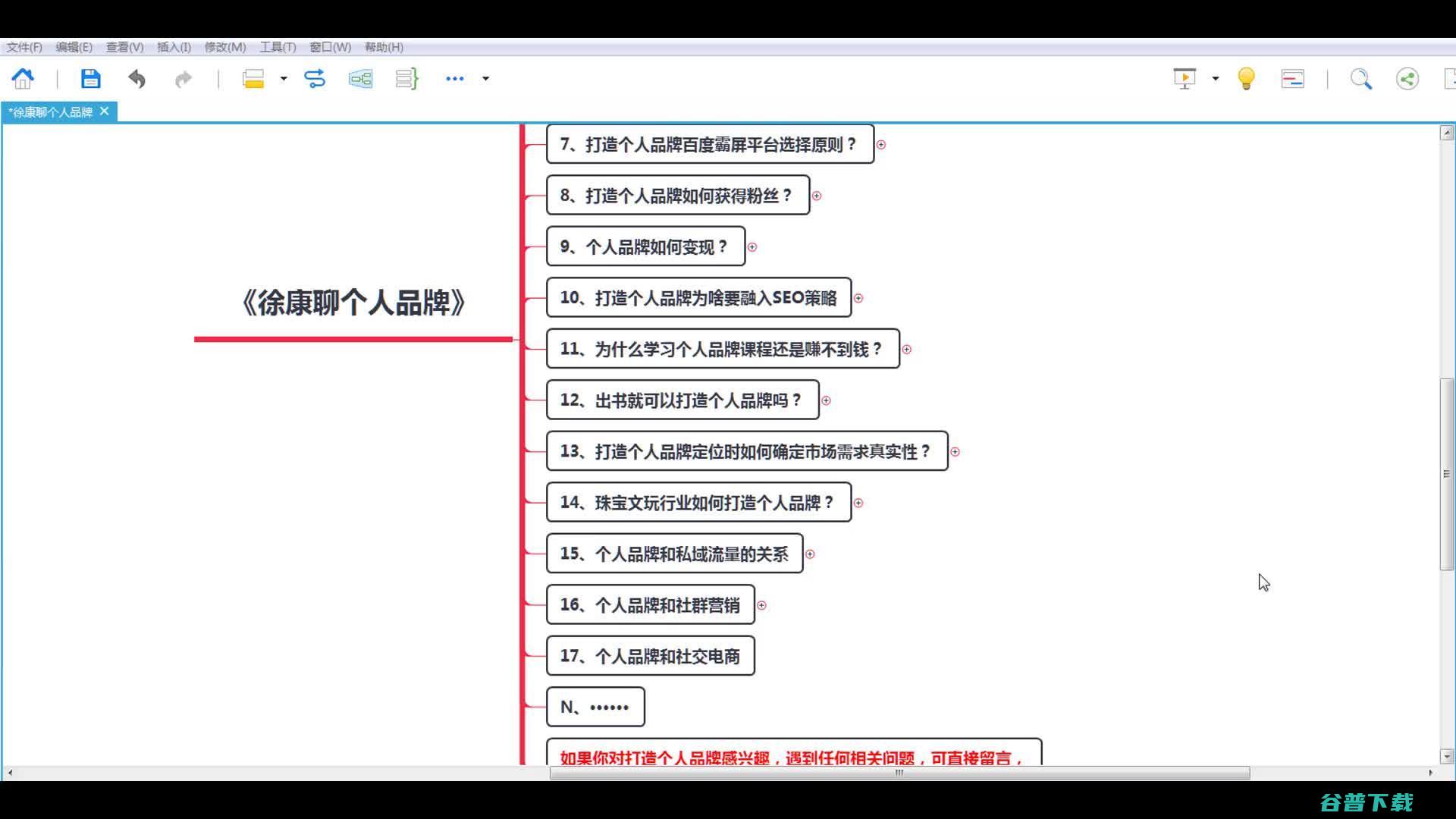
如何让个人品牌IP落到实处,而不是感觉做了没什么用,很多人都会觉得打造个人品牌IP好像没什么用,而且很多人也不懂得个人品牌IP这个东西,跟有些老板讲个人品牌IP的时候,他说品牌倒是知道,IP也听到个人品牌IP就不知道是啥东西了,还有些人觉得那我打造了个人品牌IP真的能赚到钱吗,怎么听着感觉有点虚无缥缈,个人品牌IP说得简单点就是能够让...。
