CVPR 空间 一个降低深度学习时间 经济成本的解决方案 Active 2017 Learning (cvpr空间特征增强)

雷锋网 AI 科技评论按:本文为 CVPR 2017 的论文解读,作者周纵苇(Zongwei Zhou),邮箱:zongweiz@asu.edu,微博:@MrGiovanni。本文首发于 简书 ,经作者授权,雷锋网转载。
下面要介绍的工作发表于,题为「Fine-tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally」。它主要解决了一个深度学习中的重要问题:如何使用尽可能少的标签数据来训练一个效果 promising 的分类器。根据我的判断,当遇到两种情况的时候,这篇论文的可以非常强大的指导意义:
这两个情况发生的条件是完全不同的,Situation A 发生在屌丝公司,没有钱拿到精标记的数据集,却也想做深度学习;Situation B 一般发生在高富帅公司,有海量的精标记数据,但是由于目前即使是最牛逼的计算机也不能用深度学习在短时间内一次性地去处理完这些数据(e.g.,内存溢出,或者算上个几年都算不完)。Anyway,我想我已经说清楚应用背景了,读者可以根据实际情况判断是否往后读下去。

感谢你选择继续往下阅读,那么如果觉得下文所传递的思想和方法对你有帮助,请记得一定引用这篇 CVPR 2017 的文章。 Fine-tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally.
1.为什么会想到去解决这个问题?
现在深度学习很火,做的人也越来越多,那么它的门槛可以说是很低的,Caffe,Keras,Torch 等等框架的出现,让该领域的 programming 的门槛直接拆了。所以深度学习真正的门槛变成了很简单概念——钱。这个钱有两个很重要的流向,一是计算机的运算能力(GPU Power),二是标记数据的数量。这儿就引出一个很重要的问题: 是不是训练数据集越多,深度学习的效果会越好呢? 这个答案凭空想是想不出来的,能回答的人一定是已经拥有了海量的数据,如 Imagenet,Place 等等,他们可以做一系列的实验来回答这个问题。需要呈现的结果很简单,横坐标是训练集的样本数,纵坐标是分类的 performance,如下图所示:
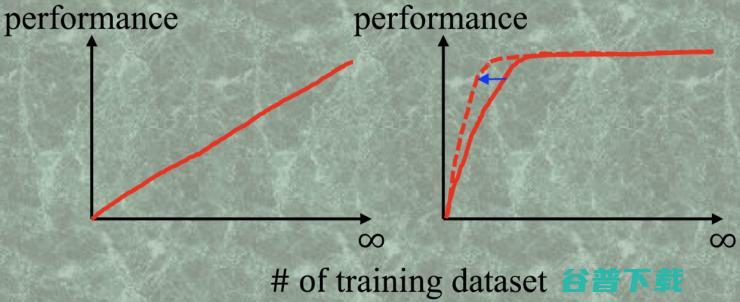
Fig.1 如果答案是左图,那么就没什么可以说的了,去想办法弄到尽可能多的训练数据集就 ok,但是现实结果是右图的红实线,一开始,训练集的样本数增加,分类器的性能快速地在上升,当训练集的样本数达到某一个临界值的时候,就基本不变了,也就是说,当达到了这个临界的数目时,再去标注数据的 ground truth 就是在浪费时间和金钱。有了这个认知,接下来就是想办法让这个临界值变小,也就是用更小的训练集来更快地达到最理想的性能,如右图的红虚线所示。红实线我们认为是在随机地增加训练集,那么红虚线就是用主动学习(Active Learning)的手段来增加训练集,从而找到一个更小的子集来达到最理想的性能。
这里需要说明的一点是,训练样本数的临界点大小和这个分类问题的难度有关,如果这个分类问题非常简单,如黑白图像分类(白色的是 1,黑色的是 0),那么这个临界值就特别小,往往几幅图就可以训练一个精度很高的分类器;如果分类问题很复杂,如判断一个肿瘤的良恶性(良性是 0,恶性是 1),那么这个临界值会很大,因为肿瘤的形状,大小,位置各异,分类器需要学习很多很多的样本,才能达到一个比较稳定的性能。
对于很多从事深度学习的无论是研究员还是企业家都是一个十分有启发性的认知改变。一般来讲,人的惯性思维会引领一个默认的思路,就是训练样本越多越好,如左图所示,这将直接导致许多工作的停滞不前,理由永远是「我们没有足够的数据,怎么训练网络!」进一步的思路是图二的红实线认知:要多少是多啊,先训着再说,慢慢的就会发现即便用自己有的一小部分数据集好像也能达到一个不错的分类性能,这个时候就遇到一个问题: 自己的数据集样本数到底有没有到达临界值呢? 这个问题也很关键,它决定了要不要继续花钱去找人标注数据了。这个问题我会在第三部分去回答它,这里先假设我们知道了它的答案, 接下来的问题就是如何让这个临界值变小?
2. 如何让临界值变小?
解决方案就是主动学习(Active Learning),去主动学习那些比较 「难的」,「信息量大的」 样本(hard mining)。关键点是每次都挑当前分类器分类效果不理想的那些样本(hard sample)给它训练,假设是训练这部分 hard sample 对于提升分类器效果最有效而快速。 问题是在不知道真正标签的情况下怎么去定义 HARD sample?或者说怎么去描述当前分类器对于不同样本的分类结果的好坏?
定义: 由于深度学习的输出是属于某一类的概率(0~1),一个很直观的方法就是用「 熵(entropy) 」来刻画信息量,把那些预测值模棱两可的样本挑出来,对于二分类问题,就是预测值越靠近 0.5,它们的信息量越大。还有一个比较直观的方法是用「 多样性(diversity) 」来刻画 labeled target="_blank">「Active batch selection via convex relaxations with guaranteed solution bounds」中被提出。是十分重要的两个 Active Learning 的选择指标。
有了这两个指标来选 hard sample,是比较靠谱了——实验结果表明,这比随机去选已经能更快地达到临界拐点了。
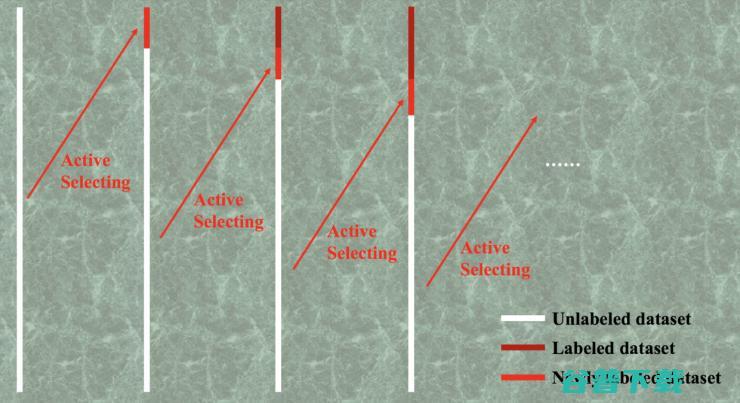
Active Learning 的结构示意图。利用深度学习所带来的优势在于,一开始你可以不需要有标记的数据集。
举例来讲,假设你是一个养狗的大户,你现在想做一个非常偏的(专业化的)分类问题,如 卷毛比雄犬 和 哈瓦那犬 的分类问题,你手头有这两种狗各 50 条,你自己可以很轻松地区分这 100 条狗,现在需要做的是训练一个分类器,给那些不懂狗的人,他们拍了狗的照片然后把照片输入到这个分类器就可以很好地判断这是卷毛比雄犬还是哈瓦那犬。首先你可以给这 100 条狗拍照片,每条狗都有不同形态的 10 张照片,一共拍了 1000 张没有标记的照片。对于这 1000 张照片,你所知道的是哪 10 张对应的是一条狗,其他什么都不知道。
在这个实际分类问题中,你拥有绝对的数据优势,即便是 Google Image 也不能企及,当然一种选择是你把 1000 张图片从头到尾看一遍,标注好,但是你更希望是把大多数简单的分类工作交给分类器,自己尽可能少的做标记工作,并且主要是去标记那些分类器模棱两可的那几张照片来提高分类器的性能。
我们初步提供的解决方案是 (参考或者):
如所示,每次循环都用不断增加的标记数据集去提升分类器的性能,每次都挑对当前分类器比较难的样本来人为标记。
3. 这个过程什么时候可以停?
以上三种情况都可以让这个循环训练过程中断,第一种就很无奈了,没钱找人标记了... 第二种情况和第三种情况的前提共识是如果难的样本都分类正确了,那么我们认为简单的样本肯定也基本上分类正确了,即便不知道标签。第三种情况,举例来说就是黑白图像分类,结果分类器模棱两可的图像是灰的... 也就是说事实上的确分不了,并且当前的分类器居然能把分不了的样本也找出来,这时我们认为这个分类器的性能已经不错的了,所以循环训练结束。
至此,主要讲了传统的 Active Learning 的思想,接下来会讲讲这篇 CVPR2017 论文的几个工作点。
上面我讲到了 Active Learning 的大概思路,如所示,是一个很有意思的概念,说实话很实用,我在 Mayo Clinic 实习的时候,每次遇到新的数据集,都会想着用一用这个方法,来让给数据标注的专家轻松一点...
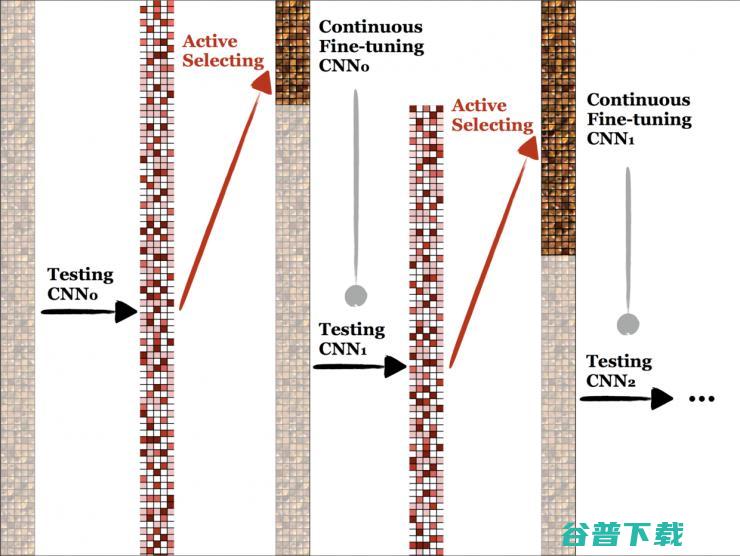
Fig.3 暗的表示 unlabeled 的数据,高亮的表示 labeled 的数据,CNN 的结构可以随便挑 SOTA 的无所谓,CNN0 是拍 retrained from ImageNet,得到的第二列表示每个 image 对应的 importance 指标,越红的说明 entropy 越大,或者 diversity 越大,每次挑这些 important 的 sample 给专家标注,这样 labeled 的数据就变多了,用 labeled 的数据训练 CNN,得到新的更强的分类器了,再在 unlabeled target="_blank">Active batch selection via convex relaxations with guaranteed solution bounds」的描述,Diversity 是计算 labeled>
这样的 diversity 就完美了吗?并没有... 读者可以先猜猜哪儿又出问题啦,我在第五部分会指出来。

5. 这次是 target="_blank">Augmentation Lecture讲到的平移 crop,如果我们将它应用到猫的分类问题中,很有可能得到这样的训练样本:

Fig.4 左图是原始的图像,中间的 9 个 patches 是根据平移变化的扩充得到的,restrictions: region must contain objects or part of the object 详见这里,右图是网络得到的对应 patch 的预测值。
可以看出,在这个实例中,对于一个 candidate,网络预测的一致性很低,套用 Diversity 的公式,Diversity 的值很大,也就是说,应该被认为是 hard sample 挑出来。但是仔细观察一下这九个 patches 就不难看出,即便是很好的分类器,对于中间图中的 1,2,3,也是很难分出这个是猫... could be rat, rabbit, etc. 我们把像这三个 patch 的例子叫做从>

至此,主要讲了这篇论文是怎样成功的将 Diversity 这个重要的指标引入到 Active Learning 中来,所有的 Active Selection 部分结束。
6. 如何训练?
既然用了迁移学习,那么一开始的 CNN 测试的效果肯定是一团糟,因为这个 CNN 是从自然图像中学过来的,没有学习过 CT 这种医学影像,所以这个 loop 的启动阶段,Active Learning 的效果会没有 random selecting 好。不过很快,随着 CNN 慢慢地在 labeled 的 CT 上训练,Active Learning 的效果会一下子超过 random selecting。
接下来讨论 Continuous fine-tuning 的细节,随着 labeled target="_blank">here.
Find poster.
Find author.
祝好,

版权文章,未经授权禁止转载。详情见 转载须知 。



LOL网址导航网是专业的上网导航网站,精心收录各类优质热门网站信息,同时提供天气、快递、违章等各种生活便民查询工具网址,为您提供安全便捷的上网导航服务,现已被众多网友设为上网主页,网址导航大全首选LOL网址导航.

神婆运势网是一家包含十二生肖、十二星座、周公解梦等每日运势、每周运势、每月运势解析的网站,欢迎您的到来。

烟台一新专注于生产磁性分离器,纸带过滤机,排屑器,甩干机,刮油机以及切屑综合处理设备,与国内众多机床厂、轴承厂、钢铁厂、汽车零部件和制造厂等保持密切的长期合作。公司以解决客户问题为己任,切合实际的设计刮油机、制造出满足客户需求的机床甩干机

湖北浩嘉工程项目管理有限公司

河北金标建材科技股份有限公司是一家专业从事光伏车棚、太阳能电站系统设计、研发、施工为一体的企业;光伏雨棚、太阳能电站的造价以及方案设计也可以提供,全程跟踪式服务;工厂园区、小区自建等都可以承接,分布式光伏电站和集中式光伏电站;自创建以来,始终坚守真诚做人,用心做事的态度,严格按照合同和客户要求,提供靠谱的太阳能光伏发电系统产品。

赤赤旅游攻略网_提供最齐全的国内外旅游景点大全,您可以在这里找到关于旅游目的地最详细的图文介绍,可信赖的游览路线等等一系列关于旅游的资讯.

四川策文科技有限公司全端云小程序

亳州市花玉颜生物科技有限公司

唐山海森电子股份有限公司主要从事水田智能灌溉控制系统的设计、水资源远程测控管理系统、农田水肥墒药一体化自动化灌溉控制系统、农田机井灌溉控制器、智能大棚自动控制系统的研发、生产、销售、管护,公司从成立之初就确定了“创新引领、客户体验为王”的行业服务理念,全力打造成为农业投建管服一站式服务商,是中国水交所8个创始会员之一,合同节水联盟副理事长单位,水利部华北6省农业水价综合改革定点观摩培训示范基地。

UDIDS.CN提供专业、快速、安全的iOS设备UDID获取服务。支持多语言、暗黑模式,帮助开发者和用户轻松获取设备唯一标识符,确保应用开发和测试的顺利进行。

杭州理想画室官网成立于2003年,是杭州好的画室,在杭州画室,杭州美术培训学校有影响力,教学成熟,管理严谨,杭州画室哪家好选理想杭州美术学校,杭州美术培训学校

天气信息报告


今天将为大家详细讲解一下虚拟资源项目玩法分为几部分来讲解,大家去实操落地,我也不废话,直接上干货,既然大家来了解到这个项目,目的都是为了赚钱,我说的玩法都是我自己实操过的,不知道有没有人混过这个圈子,好多人都是别人的东西,大家心态要平稳,互联网鱼龙混杂,好多人看不到效果就放弃了,三五天就见效果的不建议大家去做,细品,我说的都是长期操作...。

大咖Live,声智专场,声智科技合伙人、副总裁李智勇先生带来了关于,假如人类要打造终极的矩阵,那么一共需要几步,的主题分享,引领我们思考未来AIoT到底会带来什么,分享智能语音交互在终极矩阵中所扮演的角色,目前,本期分享音频及全文实录已上线,,AI投研邦,会员可进,AI投研邦,页面免费查看,本文对本次分享进行要点总结及PPT整理,以...。

近日,知名人工智能专业媒体及产业服务平台机器之心公布了,AI中国,机器之心2020年度榜单,暗物智能科技,以下简称,暗物智能,凭借出色的技术创新能力与优秀的商业落地成果,成功入选,最强人工智能TOP30,依托于公司创始人、全球著名人工智能专家朱松纯教授强认知人工智能的技术理念,暗物智能从一支AI创业新势力到如今登顶,最强人工智...。

20世纪40年代的第一个秋天,西半球人声鼎沸,这正是第二次世界大战结束后,与第三次科技革命而交汇之际,时间定格为1945年,从这一刻开始,原子能、电子计算机、空间技术和生物工程等发明日新月异,如决堤般迅速转化为社会应用,二战的结束,以一股极强的后坐力,极大地推动了第三次科技革命的兴起,其中一所在芝加哥附近的阿贡国家实验室,从核能研究转...。

据彭博社9月6日报道,美国政府将两艘船舶以及相关的两家印度航运公司列入制裁名单,报道称,这是美国阻遏俄罗斯进口液化自然气的最新制裁措施,外地期间9月5日,美国财政部本国资产管理办公室,OFAC,发表,将,木兰,号,Mulan,和,新动力,号,NewEnergy,两艘液化气船列入制裁名单,依据美国财政部颁布的申明,总部位于印度的两家航运...。

微顶跑腿APP外卖订餐帮送帮取帮买帮办不烦恼:)

该机构虚伪宣传,违规运营,超出运营范畴,诱导自己生产,成果和之前承诺的基本不分歧,没有开具发票,存在偷税漏税行为,经过抖音看到的宣传信息,到店后被店长拉到办公室说皮肤疑问,说我的皮肤疑问很重大要快点做名目,让我先充五百八百,我说没有足够的钱,让我去体验祛痘针清环节中,服务技师不时说店内有国庆节活......。

每日星座运程是怎样样的每日星座运程是怎样样的,星座之间不同的磁场也会相互影响,星座之间的性情存在着很大的差异,这是一个不论做什么事情都很热心的星座,以下分享每日星座运程是怎样样的,每日星座运程是怎样样的1其实关于星座运程,大少数的事情上就是要咱们以为,这种星座运程就是一种很显著的人际来往知识,而且要是了解这种知识,很大的水平上并不能让...。

西风日产奇骏被誉为SUV中的,战役机,,其市场表现不时十分杰出,备受公众的青眼,然而,在购置车辆的时刻,最让人关心的还是车辆的多少钱疑问,那么,西风日产奇骏的多少钱终究是多少呢,目前,西风日产奇骏在国际市场的售价是16.98万元起,不过,详细的多少钱还要依据车型以及性能来启动确定,作为SUV车型,西风日产奇骏领有多种车型可供选用,旗舰...。

奔流b50经常使用了两款发起机,一款是1.4升涡轮增压发起机,另一款是1.6升人造吸气发起机,奔流b50是奔流旗下的一款紧凑型轿车,这款车的长宽高区分是4695毫米,1795毫米,1460毫米,轴距为2725毫米,奔流b50的1.4升涡轮增压发起机最大功率为100kw,最大功率转速为4500到5500转每分钟,最大扭矩为220牛米,最...。

4月30日(周二)马前炮_秦国安财经_新浪博客,秦国安财经,

《鬼谷八荒》是一款结合了修仙体系与山海经文化背景的角色扮演游戏,而今天小编要带来的是一个《鬼谷八荒》上古神器存档修改工具下载v0.8.0,更新修改神魂道魂领域,喜欢《鬼谷八荒》游戏工具的就赶紧试试吧。完美下载为您准备了“《鬼谷八荒》上古神器存档修改工具”,欢迎大家前来下载使用

本期将要给大家带来的是有没有好玩的经营类手机游戏的相关介绍内容,你是不是有一个成为富豪的梦想呢,是不是想要从商成为世界首富呢,是不是担心自己没有经商经验而苦恼呢,不用担心,小编将在这里把几款受欢迎的模拟经营类手游带给大家,大家只需要通过游戏就能够完成这个梦想,快来试试吧,在这款游戏中,玩家需要穿越得到古代进行经商,虽然身处古代,但是这...。

拥有近100万粉丝的主播,超级小桀,直播时,号召粉丝帮忙砍价拼多多,结果砍到小数点后六位数都没成功没人工客服还挂了其电话,虽然早知道是骗局,但真砍到后6位我也是第一次见,6万人在线砍都没砍下来一台手机,按照直播时候的统计,有60000,6万,多粉丝帮忙砍价,砍了2个小时,最后竟然还需要0.01元才可以成功,真的只差亿点点,主播他还分享...。
2010年8月前后,陈仙正的朋友刘毅从宁波到安徽玩,陈仙正告诉刘毅,用木马病毒软件盗窃他人的QQ账号可以赚钱,他可以提供木马病毒等软件,刘毅只要出电脑就行,正愁没有发财机会的刘毅一听很是动心,回到宁波后就找了金嘉凯、王铭珺等人入伙,通过购买和租赁的方式凑了400多台电脑,并雇用了贺世达等十来个外来务工人员进行盗号,由于这个盗号团伙的成...。

小鹏汽车回应修改道路救援条款,避免歧义,非质量问题不再提供免费救援近日不少车主在社交平台上爆料称,小鹏汽车偷偷篡改免费救援协议,曝光的图片显示,小鹏汽车此前的,无忧救援,服务显示,全国范围无限次、不限里程道路救援;免费提供拖车救援服务,将车辆拖至小鹏汽车指定的服务中心或超级充电站处,而更改后的服务中,删除了,无限次、不限里程,描述,也...。

5G处理器的竞争,成为了为数不多高手之间的竞赛,这场竞赛,会因为5G技术的难度、AI技术的发展以及手机厂商越来越寻求差异化更加值得期待,并且,这些高手们也将在旗舰以及中高端市场全面竞争,本周,MediaTek发布了中高端5GSoC天玑820,相比年初发布的天玑800进行了三大提升,号称同级最强5G性能,那天玑820能否成为最强5GSo...。
