CNN 内部网络结构区别 一文读懂 RNN DNN (cnn网络)
从广义上来说,NN(或是更美的DNN)确实可以认为包含了CNN、RNN这些具体的变种形式。在实际应用中,所谓的深度神经网络DNN,往往融合了多种已知的结构,包括卷积层或是LSTM单元。但是如果说DNN特指全连接的神经元结构,并不包含卷积单元或是时间上的关联。因此,如果一定要将DNN、CNN、RNN等进行对比,也未尝不可。
其实,如果我们顺着神经网络技术发展的脉络,就很容易弄清这几种网络结构发明的初衷,和他们之间本质的区别。神经网络技术起源于上世纪五、六十年代,当时叫 感知机 (perceptron),拥有输入层、输出层和一个隐含层。输入的特征向量通过隐含层变换达到输出层,在输出层得到分类结果。
早期感知机的推动者是Rosenblatt。(扯一个不相关的:由于计算技术的落后,当时感知器传输函数是用线拉动变阻器改变电阻的方法机械实现的,脑补一下科学家们扯着密密麻麻的导线的样子…),但是,Rosenblatt的单层感知机有一个严重得不能再严重的问题,即它对稍复杂一些的函数都无能为力(比如最为典型的“异或”操作)。
连异或都不能拟合,你还能指望这货有什么实际用途么o(╯□╰)o 随着数学的发展,这个缺点直到上世纪八十年代才被Rumelhart、Williams、Hinton、lecun等人(反正就是一票大牛)发明的 多层感知机 (multilayer perceptron)克服。多层感知机,顾名思义,就是有多个隐含层的感知机。我们看一下多层感知机的结构:

图1 上下层神经元全部相连的神经网络——多层感知机
多层感知机可以摆脱早期离散传输函数的束缚,使用sigmoid或tanh等连续函数模拟神经元对激励的响应,在训练算法上则使用Werbos发明的反向传播BP算法。
对,这货就是我们现在所说的 神经网络NN ——神经网络听起来不知道比感知机高端到哪里去了!这再次告诉我们起一个好听的名字对于研(zhuang)究(bi)很重要! 多层感知机解决了之前无法模拟异或逻辑的缺陷,同时更多的层数也让网络更能够刻画现实世界中的复杂情形。
相信年轻如Hinton当时一定是春风得意。多层感知机给我们带来的启示是, 神经网络的层数直接决定了它对现实的刻画能力 ——利用每层更少的神经元拟合更加复杂的函数。(Bengio如是说:functions that can be compactly represented by a depth k architecture might require an exponential number of computational elements to be represented by a depth k − 1 architecture.)
即便大牛们早就预料到神经网络需要变得更深,但是有一个梦魇总是萦绕左右。随着神经网络层数的加深, 优化函数越来越容易陷入局部最优解 ,并且这个“陷阱”越来越偏离真正的全局最优。利用有限数据训练的深层网络,性能还不如较浅层网络。
同时,另一个不可忽略的问题是随着网络层数增加, “梯度消失”现象更加严重 。具体来说,我们常常使用sigmoid作为神经元的输入输出函数。对于幅度为1的信号,在BP反向传播梯度时,每传递一层,梯度衰减为原来的0.25。层数一多,梯度指数衰减后低层基本上接受不到有效的训练信号。
2006年,Hinton利用预训练方法缓解了局部最优解问题,将隐含层推动到了7层,神经网络真正意义上有了“深度”,由此揭开了深度学习的热潮。这里的“深度”并没有固定的定义——在语音识别中4层网络就能够被认为是“较深的”,而在图像识别中20层以上的网络屡见不鲜。
为了克服梯度消失,ReLU、maxout等传输函数代替了sigmoid,形成了如今DNN的基本形式。单从结构上来说, 全连接的DNN和图1的多层感知机是没有任何区别的 。值得一提的是,去年出现的高速公路网络(highway network)和深度残差学习(deep residual learning)进一步避免了梯度消失,网络层数达到了前所未有的一百多层(深度残差学习:152层)!
具体结构大家可自行搜索了解。如果你之前在怀疑是不是有很多方法打上了“深度学习”的噱头,这个结果真是深得让人心服口服。
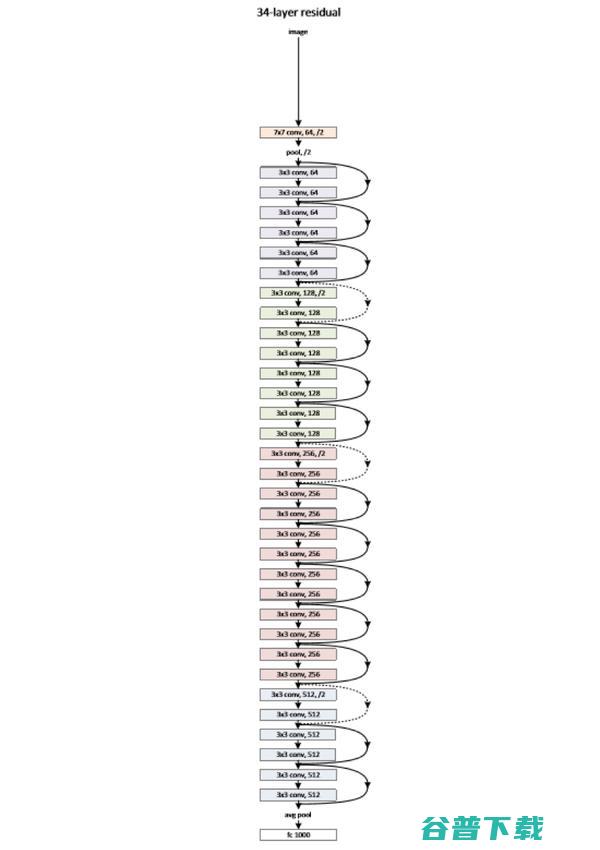
图2 缩减版的深度残差学习网络,仅有34层,终极版有152层
如图1所示,我们看到 全连接DNN的结构里下层神经元和所有上层神经元都能够形成连接 ,带来的潜在问题是 参数数量的膨胀 。假设输入的是一幅像素为1K*1K的图像,隐含层有1M个节点,光这一层就有10^12个权重需要训练,这不仅容易过拟合,而且极容易陷入局部最优。
另外,图像中有固有的局部模式(比如轮廓、边界,人的眼睛、鼻子、嘴等)可以利用,显然应该将图像处理中的概念和神经网络技术相结合。此时我们可以祭出题主所说的卷积神经网络CNN。对于CNN来说,并不是所有上下层神经元都能直接相连,而是 通过“卷积核”作为中介。同一个卷积核在所有图像内是共享的,图像通过卷积操作后仍然保留原先的位置关系 。
两层之间的卷积传输的示意图如下:
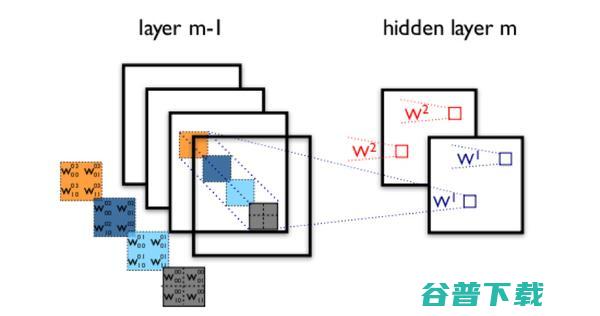
图3 卷积神经网络隐含层
通过一个例子简单说明卷积神经网络的结构。假设图3中m-1=1是输入层,我们需要识别一幅彩色图像,这幅图像具有四个通道ARGB(透明度和红绿蓝,对应了四幅相同大小的图像),假设卷积核大小为100*100,共使用100个卷积核w1到w100(从直觉来看,每个卷积核应该学习到不同的结构特征)。
用w1在ARGB图像上进行卷积操作,可以得到隐含层的第一幅图像;这幅隐含层图像左上角第一个像素是四幅输入图像左上角100*100区域内像素的加权求和,以此类推。
同理,算上其他卷积核,隐含层对应100幅“图像”。每幅图像对是对原始图像中不同特征的响应。按照这样的结构继续传递下去。CNN中还有max-pooling等操作进一步提高鲁棒性。

图4 一个典型的卷积神经网络结构
注意到最后一层实际上是一个全连接层,在这个例子里,我们注意到 输入层到隐含层的参数瞬间降低到了100*100*100=10^6个 !这使得我们能够用已有的训练数据得到良好的模型。题主所说的适用于图像识别,正是由于 CNN模型限制参数了个数并挖掘了局部结构的这个特点 。顺着同样的思路,利用语音语谱结构中的局部信息,CNN照样能应用在语音识别中。
全连接的DNN还存在着另一个问题——无法对时间序列上的变化进行建模。然而, 样本出现的时间顺序对于自然语言处理、语音识别、手写体识别等应用非常重要 。对了适应这种需求,就出现了大家所说的另一种神经网络结构——循环神经网络RNN。
在普通的全连接网络或CNN中,每层神经元的信号只能向上一层传播,样本的处理在各个时刻独立,因此又被成为前向神经网络(Feed-forward Neural Networks)。而在 RNN中,神经元的输出可以在下一个时间戳直接作用到自身 ,即第i层神经元在m时刻的输入,除了(i-1)层神经元在该时刻的输出外,还包括其自身在(m-1)时刻的输出!表示成图就是这样的:

我们可以看到在隐含层节点之间增加了互连。为了分析方便,我们常将RNN在时间上进行展开,得到如图6所示的结构:
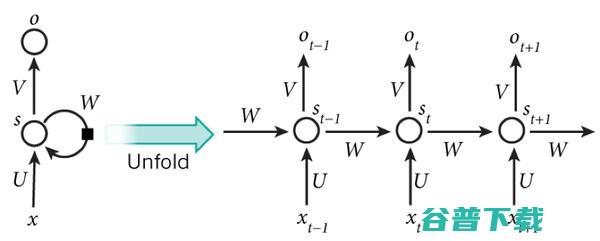
Cool, (t+1)时刻网络的最终结果O(t+1)是该时刻输入和所有历史共同作用的结果 !这就达到了对时间序列建模的目的。 不知题主是否发现,RNN可以看成一个在时间上传递的神经网络,它的深度是时间的长度!正如我们上面所说, “梯度消失”现象又要出现了,只不过这次发生在时间轴上 。
对于t时刻来说,它产生的梯度在时间轴上向历史传播几层之后就消失了,根本就无法影响太遥远的过去。因此,之前说“所有历史”共同作用只是理想的情况,在实际中,这种影响也就只能维持若干个时间戳。
为了解决时间上的梯度消失,机器学习领域发展出了 长短时记忆单元LSTM,通过门的开关实现时间上记忆功能,并防止梯度消失 ,一个LSTM单元长这个样子:

除了目前提到的三种网络,以及我之前提到的深度残差学习、LSTM外,深度学习还有许多其他的结构。举个例子,RNN既然能继承历史信息,是不是也能吸收点未来的信息呢?
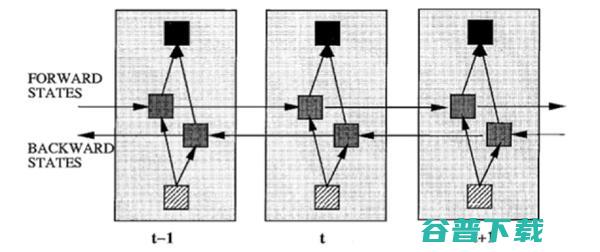
因为在序列信号分析中,如果我能预知未来,对识别一定也是有所帮助的。因此就有了 双向RNN、双向LSTM,同时利用历史和未来的信息 。
事实上, 不论是哪种网络,他们在实际应用中常常都混合着使用,比如CNN和RNN在上层输出之前往往会接上全连接层,很难说某个网络到底属于哪个类别 。不难想象随着深度学习热度的延续,更灵活的组合方式、更多的网络结构将被发展出来。
尽管看起来千变万化,但研究者们的出发点肯定都是为了解决特定的问题。如果想进行这方面的研究,不妨仔细分析一下这些结构各自的特点以及它们达成目标的手段。
入门的话可以参考:
Ng写的Ufldl: UFLDL教程 – Ufldl
也可以看Theano内自带的教程,例子非常具体: Deep Learning Tutorials
欢迎大家继续推荐补充。
参考文献:
雷锋网按:本文来自于知乎 科研君 的 回答 。
版权文章,未经授权禁止转载。详情见 转载须知 。



首都医科大学附属北京友谊医院始建于1952年,原名为北京苏联红十字医院,是新中国成立后,在苏联政府和苏联红十字会援助下,由党和政府建立的第一所大型医院。1954年新院址落成,毛泽东、周恩来、刘少奇、朱德等老一辈革命家为医院亲笔题词。毛泽东主席特别题词“减少人民的疾病,提高人民的健康水平”。1957年3月,苏联政府将医院正式移交我国政府,周恩来总理亲自来院参加了移交仪式。1970年,周总理亲自为医院命名为“北京友谊医院”。

华瑞保险提供养老保险,意外保险,医疗险,重疾保险,等年金等多险种综合性保险服务。以“诚信、专业、价值”为经营发展理念,致力于为客户带来价值

简庭泰国通信提供泰国呼叫中心、国际呼叫线路、境外隐私号码、海外视频彩信等通信资讯服务。

赚钱网建立于2004年,是一家老牌赚钱资讯网站。网上怎么赚钱一直是每个网站站长和网民最关心的内容,网络赚钱充满了诱惑、欺诈和不良因素,需要谨慎选择。网站怎样赚钱?做什么最赚钱?一切赚钱资讯尽在赚钱网!

河北绿吾丰生物肥料制造有限公司

您身边的贴身视觉管家

54op游戏是国内知名网页游戏运营平台,平台主要运营赤月传说,大皇帝,剑雨江湖,九阴绝学等网页游戏产,同时提供几十款2016全新网页游戏产品礼包,开服信息,很好的解决免费游戏玩家找开服找网页游戏的需求,平台深受网页游戏玩家喜爱

深圳市炫宝智远科技有限公司,深圳CPU卡控水机厂家,是一卡通行业主导型专业厂商之一,产品范围包括:包括智能卡售饭系统、智能水控系统、刷卡设备;门禁考勤系统、智能化停车场系统、及会员系统;广泛应用于各种场所,包括工厂、学校、停车场、商场、宾馆、酒店、自助洗衣房、出租屋、公寓、连锁店、居民小区、政府单位等场所

四川省造纸行业协会

北京恒远安诺科技有限公司(安诺科技),电话13521412287,致力于成为国内领先的机电工控设备和仪器仪表电子商务供应商。安诺科技的采购团队通过直接从欧洲和美国厂家采购,为客户提供极具价格竞争力的产品和服务。

巩义市博宇铝材销售有限公司

广州佳环电器科技有限公司是一家专业从事臭氧发生器的研发,生产,应用技术的公司,臭氧消毒机,臭氧机,制氧机等


作为一种经久不衰的游戏类型,mmo独有的多人乐趣可谓广受欢迎,那么在如今这一类作品层出不穷且数量众多的情况下,哪些mmo更推荐去体验呢,别急,一些人气高的mmo类手游大全立刻送到,大家会在这些游戏搭建起来的虚拟世界里体验到很独特的多人冒险,享受自己的欢乐时光,1、,新笑傲江湖,这部游戏提供了十分自由的玩法内容,并为大伙创建了一个有着浓...。

朝天门火锅,相信很多人印象都比较深刻,它是重庆的一个比较特色的火锅品牌,成立的时间在二零零七年就成立了,到现在为止它的整个行业包括整个品牌的发展其实还是蛮不错的,它现在属于一家连锁的品牌,其不管是食品研发或者是一些后期的运营团队都是一个集体在全国范围内几百个城市都能够看到它分公司的身影,所以这也说明其品牌的延展性还是比较强的,近期也是...。

作为一家2003年创立的公司,迅雷一直以,中国最好的下载工具,而被广大网友所熟知,但就在大概3个月前,迅雷开始了一场轰轰烈烈的复兴,股价从2.9美元直升18美元,股价最大波动涨幅达到800%,巨大波动背后的原因也很简单,迅雷将其互联网CDN等云计算技术,与区块链技术结合,推出了全新的,玩客云,以及对应的数字资产,链克,原玩客币,一...。
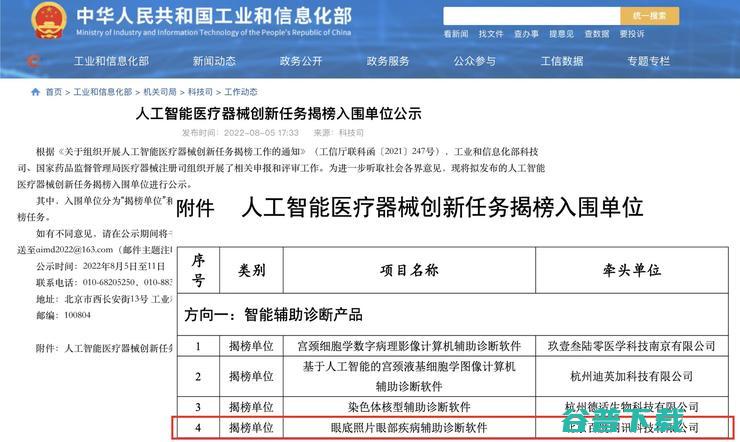
8月5日,百度凭借国内首款进入注册审评阶段的多病种眼底辅诊软件成功入围人工智能医疗器械创新任务揭榜名单,日前,由国家工业和信息化部、国家药品监督管理局联合组织的,人工智能医疗器械创新任务,揭榜入围单位名单已完成了为期一周的公示,此产品由百度牵头,联合中山大学中山眼科中心、上海交通大学附属第一人民医院眼科、爱尔眼科医院集团股份有限公司这...。

汽车是四个轮子加一张沙发,这是在功能汽车时代,,外行人,李书福给出的形象描述,未来的汽车是一张,沙发加四个轮子的计算机,在智能化趋势下,这是不少技术极客对未来智能汽车的高度概括,如果我们从汽车行业发展角度观察,会发现一个有意思的变化,沙发,和,轮子,的科技含量正在逐渐弱化,而,计算机,的功能却越来越被强化,这台功能逐渐被强...。

9月13日,vivo官宣将在10月14日举行新品发布会,预计就是首发天玑9400的vivoX200系列,这一代,应该是发哥旗舰首次比高通旗舰早发布,开卖,作为参考,X100系列是23年11月13日发布的,X90系列是22年11月22日发布的,而骁龙8Gen4要10月21日才发布,所以小米15系列最快也要10月底,今年双十一就能看到天玑...。

当事人精神并不存在问题,而是一种行为艺术,轨道交通是大家出行的工具,可有些人却把它变成展示自我的场所,会对周边的乘客带来一种不好的体验,在杭州地铁6号线就有一名女子在地铁车厢的地上爬行,后面还跟着一男一女进行拍摄,大家都觉得很奇怪,有人说这个女子在找东西,还有人觉得这个女子精神有问题,也有人认为这是一个网红在拍视频博眼球,甚至有的人觉...。

发表在专业问答2024,2,815,04展示机型信息,品牌型号,华为路由器AX3Pro系统版本,DOS系统200mbps等于25mb,s,200mbps代表每秒可以传输200兆位字节的数据,而1B等于8字节数据,因此200mbps等于每秒可以传输25MB的数据,因此200mbps等于25MB,s,200mbps等于多少mb,s200m...。

烧烤是人们意识中,十分诱人的美食,具有麻辣劲爽的口感,男女老少都爱吃,近年来,餐饮行业发展速度加快,也推动的烧烤行业的发展速度,很多品牌不断的出现,其中串意十足烧烤店非常的受欢迎,因为店内的产品种类齐全,而且味道很好,所以受到无数消费者的追捧,也提升品牌的发展速度,很多创业者看到这个项目的市场前景,所以想要在加盟之前,清楚的了解串意十...。

1、公里,综合油耗62L百公里,高速油耗49L百公里车主三宝骏630的油耗管理的还是不错的,开到如今平均油耗是7L100km,跑高速的时刻更少,我有试过6L100km的,不过是在高速匀速的状,2、宝骏630手动15实在的油耗百公里7~8L左右,城市百公里8L左右,市郊百公里油耗7L左右,高速百公里油耗6~7L左右,团体的驾驶习气和路况...。

或许是网络产生了提前疑问,或许是主机正在保养,耐烦等待即可,鲨鱼搜查长处弱小的磁力云搜查工具,聚合多个搜查引擎,弱小的内容过滤系统,搜查结果屏蔽99%的不肥壮内容,可配合弱小的MX播放器,在线云播,可配合超级弱小的迅雷下载须要的资源,界面清爽体积小巧,搜查资源速度更快!有哪些好用的磁力搜查,BT搜查网站可以介绍一下BT青草不错鲨鱼搜查...。

作为2022苹果秋季发布会的压轴产品,iPhone14Pro、iPhone14ProMax终于正式发布。价格方面,和上一代iPhone13Pro/ProMax完全一致,海外分别是999美元和1099美元起步,对应128GB存储,最大可选1TB存储容量,苹果正式发布iPhone14Pro系列:药丸屏变身灵动岛!

随着消费者对电视套娃式消费的不满情绪日渐积累,国家层面开始出手治理电视套娃式收费的乱象,近日,国家广播电视总局联合工业和信息化部、国家市场监管总局等有关单位,在京召开治理电视,套娃,收费和操作复杂工作动员部署会,要求今年底前,开展试点工作和专项整治,聚焦解决,收费包多、收费主体多、收费不透明,问题,大力改善用户开机看电视的体验,基本实...。

如果要问哪家科技公司塑造了现代互联网、现代生活,Google公司当之无愧,Google最初只是一款新奇的搜索引擎,现在已经发展成了一家科技巨头,旗下拥有8款用户超10亿的产品,眼下,许多人使用Google软件搜索人类知识库、通讯、办公、消费媒体内容、在浩瀚的互联网世界里畅游,2018年9月4日,Google迎来了20岁生日,它已成为史...。

电动车作为环保的出行工具,成为了大多数出行时的好的选择,比德文电动车作为其中一个品牌,自从面世之后,得到了很多人的认可,有部分创业者看中此品牌后,前来询问比德文电动车怎么加盟,感兴趣的创业者继续看下面介绍的内容,比德文电动车在行业内具备较大的影响力,旗下推出了好的电动车产品,品牌旗下配备了专业的研发团队,可以根据行业的变化来研发新的电...。

肖洪波毕业于清华大学,目前担任触景无限科技CEO,曾任惠普项目负责人、CA中国技术顾问、IBM资深信息架构师、UIUC高等媒体研究中心图像组项目负责人雷锋网按,近日,触景无限科技,北京,有限公司入选雷锋网发布的,AI最佳掘金案例年度榜单,,并获得最佳前端人脸识别方案奖,AI最佳掘金案例年度榜单,从商业维度出发,评选出8大行业中的30...。

格力董明珠22岁女秘书孟羽童抖音带货,连夜上架多款产品,销量惨淡,李国庆称一看就是炒作,要将孟羽童培养成第二个董明珠,前不久,格力电器董事长董明珠的一句话让她的22岁女秘书孟羽童意外走红,受到大量关注,而孟羽童相关话题也频频登上热搜,讨论热度一涨再涨,近日,有网友发现,一个名为,明珠羽童精选,的抖音账号悄然注册,该账号的头像为董明珠...。
