内存减少3% (内存减少bios怎么改?)

现代计算机诞生,如何编译更快、更小的代码问题随之出现。
编译优化是成本收益比最高的优化手段,更好的代码优化可以显著降低大型数据中心应用程序的操作成本。编译代码的大小对于部署在安全引导分区上的移动和嵌入式系统或软件来说是至关重要的,因为编译后的二进制文件必须符合严格的代码大小预算。随着这一领域的进步,越来越复杂的启发式方法严重挤压有限的系统空间,阻碍了维护和进一步的改进。
最近的研究表明,机器学习可以通过用机器学习策略取代复杂的启发式方法,在编译器优化中释放更多的机会。然而,在通用的、行业级编译器中采用机器学习策略仍然是一个挑战。
为了解决这个问题,谷歌两位高级工程师钱云迪、Mircea Trofin 提出了“MLGO,一个机器学习指导的编译器优化框架”,这是第一个工业级的通用框架,用于将机器学习技术系统地集成到 LLVM(一个开源的工业编译器基础设施,在构建关键任务、高性能软件时无处不在)中。

MLGO 使用强化学习训练神经网络来做出决策,以取代 LLVM 中的启发式算法。根据作者描述,LLVM 上有两处 MLGO 优化:
2)通过寄存器分配提高代码性能。
这两种优化都可以在 LLVM 资源库中获得,并已在生产中部署。
MLGO是如何工作的?
内联(Inlining)有助于通过做出能够删除冗余代码的决策来减少代码大小。在下面的示例中,调用者函数 。内联这两个调用站点将返回一个简单的 函数,该函数将减小代码大小。
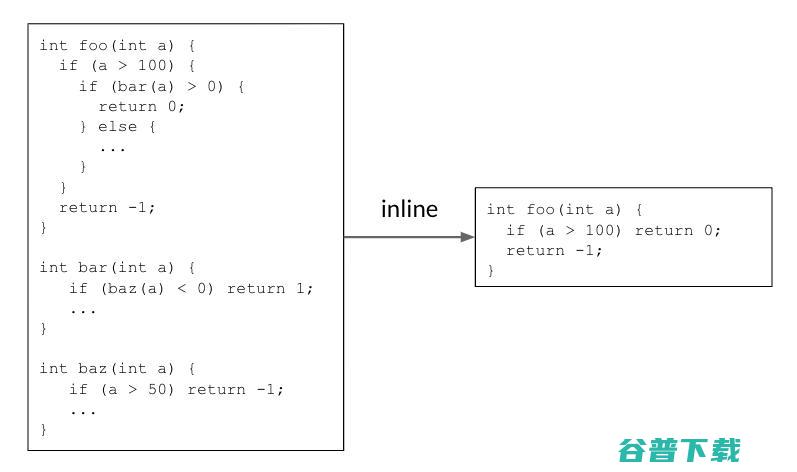
图注:内联通过删除冗余代码来减少代码大小
在实际代码中,有成千上万的函数相互调用,因此构成了一个调用图(Call graph)。在内联阶段,编译器遍历(traverses)所有调用者-被调用者对的调用图,并决定是否内联一个调用者-被调用者对。这是一个连续的决策过程,因为以前的内联决策会改变调用图,影响后面的决策和最终的结果。在上面的例子中,调用图 需要在两条边上做出“yes”的决定,以使代码大小减少。
在MLGO之前,内联/非内联的决定是由启发式方法做出的,随着时间的推移,这种方法越来越难以改进。MLGO用一个机器学习模型代替了启发式方法。在调用图的遍历过程中,编译器通过输入图中的相关特征(即输入)来寻求神经网络对是否内联特定的调用者-被调用者对的建议,并按顺序执行决策,直到遍历整个调用图为止。
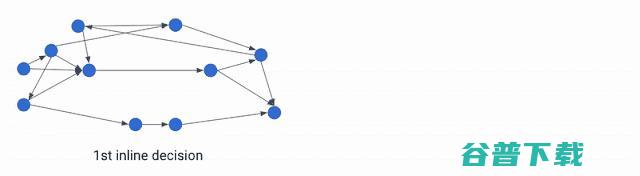
图注:内联过程中MLGO的图示,“ # bbs”、“ # users”和“ callsite height”是调用者-被调用者对特性的实例
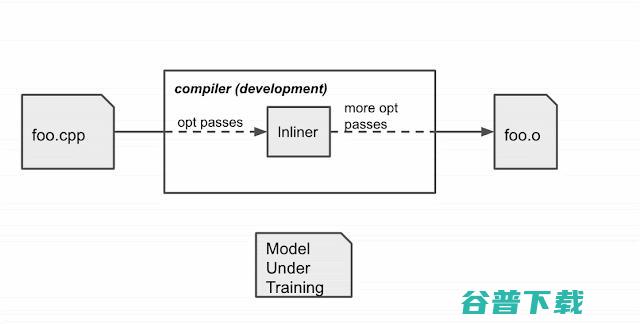
MLGO 使用策略梯度和进化策略算法对决策网络进行 RL 训练。虽然没有关于最佳决策的基本事实,但在线 RL 使用经过培训的策略在培训和运行汇编之间进行迭代,以收集数据并改进策略。特别是,考虑到当前训练中的模型,编译器在内联阶段咨询模型,以做出内联/不内联的决策。编译完成后,它产生一个顺序决策过程的日志(状态、行动、奖励)。然后,该日志被传递给训练器以更新模型。这个过程不断重复,直到得到一个满意的模型为止。
训练后的策略被嵌入到编译器中,在编译过程中提供内联/非内联的决策。与训练场景不同的是,该策略不生成日志。TensorFlow 模型被嵌入 XLA AOT ,它将模型转换为可执行代码。这避免了TensorFlow运行时的依赖性和开销,最大限度地减少了在编译时由ML模型推理引入的额外时间和内存成本。
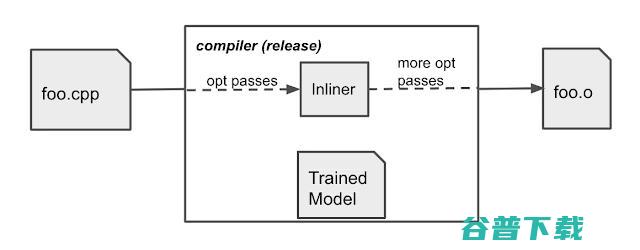
图注:生产环境中的编译器行为
我们在一个包含30k 模块的大型内部软件包上培训了大小内联策略。训练后的策略在编译其他软件时可以推广,并 减少了3% ~ 7% 的时间和内存开销。 除了跨软件的通用性之外,跨时间的通用性也很重要,软件和编译器都在积极开发之中,因此训练有素的策略需要在合理的时间内保持良好的性能。我们在三个月后评估了该模型在同一组软件上的性能,发现只有轻微的退化。
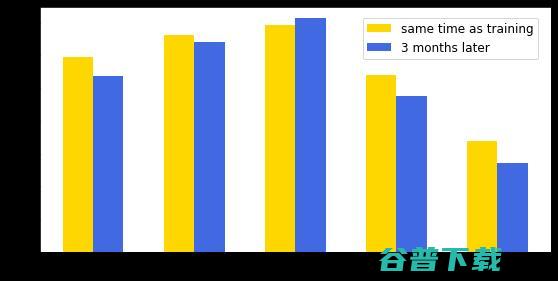
图注:内联大小策略大小减少百分比,x 轴表示不同的软件,y 轴表示减小的百分比。“Training”是训练模型的软件,“InfraX”是不同的内部软件包。
MLGO 的内联换大小训练已经在 Fuchsia 上部署,Fuchsia 是一个通用的开源操作系统,旨在为不同的硬件和软件生态系统提供动力,其中二进制大小是关键。在这里,MLGO 显示 C++ 翻译单元的大小减少了6.3%。
寄存器分配
作为一个通用框架,我们使用 MLGO 来改进寄存器分配(Register allocation)通道,从而提高 LLVM 中的代码性能。寄存器分配解决了将物理寄存器分配给活动范围(即变量)的问题。
随着代码的执行,不同的活范围在不同的时间完成,释放出的寄存器供后续处理阶段使用。在下面的例子中,每个 "加法 "和 "乘法 "指令要求所有操作数和结果都在物理寄存器中。实时范围x被分配到绿色寄存器,并在蓝色或黄色寄存器的实时范围之前完成。x 完成后,绿色寄存器变得可用,并被分配给活范围t。
在代码执行过程中,不同的活范围在不同的时间完成,释放出的寄存器供后续处理阶段使用。在下面的例子中,每个“加法”和“乘法”指令要求所有操作数和结果都在物理寄存器中。活动范围 x 被分配到绿色寄存器,并在蓝色或黄色寄存器的实时范围之前完成。x 完成后,绿色寄存器变得可用,并被分配给活范围 t 。
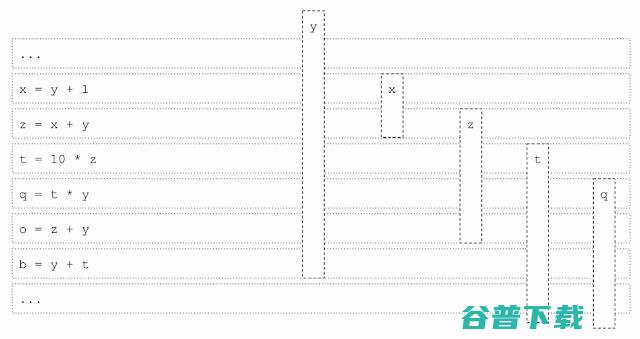
当分配活动范围 q 时,没有可用的寄存器,因此寄存器分配通道必须决定哪个活动范围可以从其寄存器中“驱逐”,以便为 q 腾出空间。这被称为“现场驱逐”问题,是我们训练模型来取代原始启发式算法的决策。在这个例子中,它将 z 从黄色寄存器中驱逐出去,并将其赋给 q 和 z 的前半部分。
我们现在考虑实际范围 z 的未分配的下半部分。我们又有一个冲突,这次活动范围 t 被驱逐和分割,t 的前半部分和 z 的最后一部分最终使用绿色寄存器。Z 的中间部分对应于指令 q = t * y,其中没有使用 z,因此它没有被分配给任何寄存器,它的值存储在来自黄色寄存器的堆栈中,之后被重新加载到绿色寄存器中。同样的情况也发生在 t 上。这给代码增加了额外的加载/存储指令,降低了性能。寄存器分配算法的目标是尽可能地减少这种低效率。这被用作指导 RL 策略训练的奖励。
与内联大小策略类似,寄存器分配(regalloc-for-Performance)策略在 Google 内部一个大型软件包上进行了培训,并且可以在不同的软件上通用,在一组内部大型数据中心应用程序上每秒查询次数(QPS)提高了0.3% ~ 1.5% 。QPS 的改进在部署后持续了几个月,显示该模型的可推广性。
总结
MLGO使用强化学习训练神经网络来作决策,是一种机器学习策略取代复杂的启发式方法。作为一个通用的工业级框架它将更深入、更广泛应用于更多环境,不仅仅在内联和寄存器分配。
MLGO可以发展为:1)更深入,例如增加更多的功能,并应用更好的 RL 算法;2)更广泛,可应用于内联和重新分配之外的更多优化启发式方法。
作者对 MLGO 能够为编译器优化领域带来的可能性充满热情,并期待着它的进一步采用和研究界未来的贡献。
版权文章,未经授权禁止转载。详情见 转载须知 。



浙江迦晟【shèng】电气有限公司主要产品服务有应急照明集中电源、消防应急照明、疏散指示系统、车库一氧化碳浓度监控系统、余压监测、压力测控系统、智能疏散指示系统、余压监控、电气火灾监控器、消防电源等各类工业领域等,有需要的朋友可以联系我们!

plugx-采样包下载平台loop采样下载音频采样下载serumpreset下载massivepreset下载spirepreset下载sylenthpreset下载合成器preset下载

2VV创始于1995年,集团总部位于捷克,是欧洲专业的通风生产商之一。现亚洲运营中心设于上海,成立至今一直从事高品质通风系统的研发及生产,产品通过并获得欧洲多项行业认证。 2VV现有多系列产品,其中ALFA系列专注于别墅、酒店等大空间房屋;DAPHNE系列主要适用于大平层或公寓等稍小空间;InGremio系列主要为管道系统,独特的防霉、杀菌、防静电特性,能够保证新鲜空气进入室内不会遭受二次污染。 2VV系列产品的组合能够为新建和改造住宅提供一体化的高品质空气解决方案。

深圳市泰久信息系统股份有限公司拥有丰富的智慧旅游与智慧影院实战建设经验,专注于各地旅游景区以及影院提供整体建设解决方案,帮助景区和影院实现线上线下移动O2O技术服务。

新乡市佳洁宝滤器有限公司是专业生产滤芯、贺德克滤芯、颇尔滤芯、液压油滤芯等一系列的国外替代滤芯为主的企业。公司依托中国过滤之乡,走专业化道路,针对以贺德克滤芯、颇尔滤芯、液压油滤芯等为主的国外替代滤芯和一些国标滤芯进行系统全面的整合,以便更专业地服务社会,满足广大客户需求。联系电话0373-2618876

云上神农架官网-云上公司注册,简称云上神农架官网-云上公司注册,是互联网线上虚拟园区,通过互联网的办法提供线下园区几乎所有的配套服务。除电子营业执照办理外,还能提供政策申报与兑现、线上培训、引导基金等服务。

次元合融官网

东莞法律咨询站汇聚了专业律师团队,涉及的主要业务领域包括房产律师、企业劳动、婚姻离婚、刑事、合同经济纠纷等,是一家专业提供法律顾问的东莞律师事务所

国内著名录音电话机、电话录音系统、电话录音卡、电话录音盒等技术领先电话录音设备制造商.产品应用三十多个行业,逾万家用户的成功体验.录音电话机、电话录音系统全国免费咨询热线:13503840447800-883-6256.

考研个人分享网http://www.363322014.com/是个人分享的博客考研类网站,考研人的笔记,分享,是一种享受,做好自己,传递知识。创作不易,多多点赞,转发支持一下。研究生们可以通过搜索、筛选和整理,选择适合自己的资料。我爱学习。

济南图科电子有限公司为国家高新技术企业,公司潜心致力于超声技术应用领域的研究,建立了领先的科研技术团队,凭借强大的技术研发能力,开发了拥有核心技术和完全自主知识产权的外贴式超声波液位计、外贴式超声波液位开关、雷达物位计等产品。外贴式液位计,外贴式超声波液位计,外贴式液位开关,外测液位计,外测式液位计,外测式液位开关,声呐式液位计,液氨液位计,液化气液位计,液氯液位计、雷达物位计、音叉物位开关,油枕液位计、变压器油枕液位计,变压器油液位计;

IPIDEA是全球HTTP企业级代理IP服务方案提供商!为客户提供全球海外代理IP,全球HTTP代理,socks5代理ip,代理IP,代理IP,住宅代理IP,在线代理,海外在线代理,HTTP代理,动态代理IP,静态代理IP,在线代理IP,住宅代理IP,国外代理IP,国外代理IP,国外在线代理IP等代理IP服务,拥有全球220+国家地区的私有住宅IP资源,满足您代理IP的需求。


小编今日为伙伴们带来的是2024闯迷宫的游戏大全的相关内容,游戏以复杂路径为舞台,玩家需在其中探索出路,或解谜闯关,或对抗挑战,凭智慧策略于曲折回廊间寻求突破与胜利,在众多游戏里,小编精心筛选整理出了一些值得一玩的游戏,倘若你热衷于此类游戏,那么可一定要认真瞧瞧1、,迷宫探险家,玩家将置身于风格各异的奇妙世界,西方魔幻元素环绕四周,在...。

一些非常具有休闲气质的合成游戏,玩家可以将相同的图案合成起来,然后组成一个更加高级的图案,经典的合成游戏大全推荐,推荐大家玩的这些游戏都可以完全按照大家的喜好来选择,大家在玩这一系列游戏的时候一定要全神贯注,而且要有较高的观察力,这样才能够将两两相同的图案组合在一起,从而能够创造出一种新的生物,1、,合成动物,这是一款以动物为主题的...。

#司机开着引擎盖驾车半小时#,近日,在广西柳州,一辆轿车竟敞开引擎盖,在路上行驶了约半小时,车主何某称,开引擎盖是为了用车载充电宝给车辆充电,可以通过引擎盖打开后的缝隙看见前方道路,她还辩解道,,哪一条规定说不能开引擎盖开车,最终,何某被处罚款100元、扣2分,央视新闻的微博视频...。

从俄国数学家AndreyMarkov,安德烈·马尔可夫,提出著名的,马尔科夫链,以来,语言建模的研究已经有了100多年的历史,近年来,自然语言处理,NLP,发生了革命性的变化,2001年,YoshuaBengio用神经网络进行参数化的神经语言模型,开启了语言建模的新时代,其后,预训练语言模型如BERT和GPT的出现再次将NLP提高到一...。

在RTE2023主论坛,声网创始人兼CEO赵斌将带来开场主旨演讲,他将分享过去一年RTE行业的发展变化,有哪些可能改变行业方向的重磅事件,在智能与高清的大趋势下,又洞察到哪些不同行业场景的实时互动新玩法、新机会,以及未来趋势,今年我们还特别邀请了硅谷重量级创投教父,FoundersSpace创始人兼CEO史蒂夫‧霍夫曼,SteveHo...。

发表在当贝投影仪2024,6,616,00当贝F6和极米H6都是采用LED光源的投影仪,都是主打客厅用的投影仪,那么两款投影仪之间有什么区别呢,下面就来详细对比分析一下,看看当贝F6和极米H6区别有哪些,全面对比分析哪款更值得入手,一、当贝F6和极米H6区别有哪些,1.光学参数对比在亮度方面,当贝F6的亮度达到2350CVIA流明,对...。

◆展品范围,★餐饮食品,中西式餐饮店、酒店、特色名吃、咖啡饮品店、茶坊、茶室连锁、休闲食品、海鲜食品、速食食品、各地风味美食、特色小吃、休闲食品、糕点、饮料、月饼、酒吧、风味土特产品等特许经营机构;★教育培训,教育培训、教育创业、婴童早期教育、成人专业教育、儿童智力开发游戏、网络游戏、动漫、管理软件开发及其他文化创意项目;★加盟服务,...。

鲜为人知!齐白石的正楷竟然如此罕见!,楷书,书法,篆书,画坛,正楷,齐白石,颜平原

假设是阳历4月1日,是白羊座03,21,04,19激情开朗的情人我给你一表,你自己对照一下吧.星座是按阳历,公历、新历,划分的星座出世日期类型白羊座03,21,04,19激情开朗的情人金牛座04,20,05,20豪放的情人双子座05,21,06,20善变的情人巨蟹座06,21,07,22恋家的情人狮子座07,23,08,22自信的情人...。

对于长安CS95四驱车型的油耗疑问,数据显示它的百公里综合油耗大概为11.5升,这款车型搭载了一台名为JL486ZQ4的2.0升涡轮增压发起机,它具有弱小的能源功能,这台发起机的最大功率到达了171kw,并能在每分钟5000转时输入其最大功率,而最大扭矩则高达360牛米,并且在1750转到3500转的转速范畴内可以成功,发起机外部驳回...。

腾讯软件中心提供2023年最新2023.8.29.13官方正式版同花顺免费版高速下载,本正式版同花顺免费版软件安全认证,免费无插件。

霍启刚郭晶晶甘肃旅游,贴脸搂肩合照超甜,戴一元发圈朴素接地气,发圈,甜蜜,t恤,甘肃,旅游,霍启刚,郭晶晶,戴一元,国际跳水赛事,奥林匹克运动会

由新浪财经、人民日报,客户端,、吴晓波频道联合打造的,2017十大经济年度人物,颁奖盛典于2018年1月28日在北京演艺中心举办,雷军第一个登场亮相,获得的评价也极高,他是手机行业颠覆者,从巅峰到低谷再强势反弹,凭借对品质和技术创新的坚持,2017年提前完成千亿销售目标五,他战略布局新零售,高速推进小米之家线下大规模扩张,绘就全球化...。

时代在不断的不变化,但是一直都没有变的就是每个对美食的希求,而现在的餐饮行业在近几年中发展的很快速,有不少创业的人看中了这个行业,许多人都想在中间分一块蛋糕,要想能够成功的进行创业,就要找一个发展成熟和完整的品牌进行加盟,蜀地冒菜就是一个不错的选择,这个品牌为消费者提供很可口的美食,现如今在餐饮行业中成为了很有人气的品牌,公司的运营模...。
本周的投资项目非常有进步,比如定位数据平台CartoDB终于不再侧重基础的地图,而是地图之上的数据和应用层;比如小熊维尼把AR跟早教结合起来终于找了个靠谱点的商业模式;比如腾讯和百度双双在医疗项目上纷纷发力,而且项目的业务内容都惊人的一致,就是通过移动端简化看病难、看病贵的毒瘤症状,其中特别要提出表扬的AR早教这个,之前国内一票缺想象...。
代码说明,本页面的认证代码为DXwap移动联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在DXwap移动联盟网站首页底部或友情链接位置处,普通认证,普通联盟认证标志适用所有类型的广告联盟,能有...。

一家上市公司,包括一把手在内的几乎所有核心高管同时,荣退,,这场面恐怕多少年也见不到一回,去年4月27日,阅文集团官方通告,吴文辉、梁晓东、商学松、林庭锋等高管集体荣退,辞任管理职务,时任腾讯集团副总裁、腾讯影业首席执行官程武出任阅文集团首席执行官和执行董事,这在外界看来,是腾讯对包括网文、影视等文娱产业链相关业务的整合,看上去是个,...。
